The web’s collective memory is stored in the servers of the Internet Archive. Legal battles threaten to wipe it all away.
If you step into the headquarters of the Internet Archive on a Friday after lunch, when it offers public tours, chances are you’ll be greeted by its founder and merriest cheerleader, Brewster Kahle.
You cannot miss the building; it looks like it was designed for some sort of Grecian-themed Las Vegas attraction and plopped down at random in San Francisco’s foggy, mellow Richmond district. Once you pass the entrance’s white Corinthian columns, Kahle will show you the vintage Prince of Persia arcade game and a gramophone that can play century-old phonograph cylinders on display in the foyer. He’ll lead you into the great room, filled with rows of wooden pews sloping toward a pulpit. Baroque ceiling moldings frame a grand stained glass dome. Before it was the Archive’s headquarters, the building housed a Christian Science church.
I made this pilgrimage on a breezy afternoon last May. Along with around a dozen other visitors, I followed Kahle, 63, clad in a rumpled orange button-down and round wire-rimmed glasses, as he showed us his life’s work. When the afternoon light hits the great hall’s dome, it gives everyone a halo. Especially Kahle, whose silver curls catch the sun and who preaches his gospel with an amiable evangelism, speaking with his hands and laughing easily. “I think people are feeling run over by technology these days,” Kahle says. “We need to rehumanize it.”
In the great room, where the tour ends, hundreds of colorful, handmade clay statues line the walls. They represent the Internet Archive’s employees, Kahle’s quirky way of immortalizing his circle. They are beautiful and weird, but they’re not the grand finale. Against the back wall, where one might find confessionals in a different kind of church, there’s a tower of humming black servers. These servers hold around 10 percent of the Internet Archive’s vast digital holdings, which includes 835 billion web pages, 44 million books and texts, and 15 million audio recordings, among other artifacts. Tiny lights on each server blink on and off each time someone opens an old webpage or checks out a book or otherwise uses the Archive’s services. The constant, arrhythmic flickers make for a hypnotic light show. Nobody looks more delighted about this display than Kahle.
It is no exaggeration to say that digital archiving as we know it would not exist without the Internet Archive—and that, as the world’s knowledge repositories increasingly go online, archiving as we know it would not be as functional. Its most famous project, the Wayback Machine, is a repository of web pages that functions as an unparalleled record of the internet. Zoomed out, the Internet Archive is one of the most important historical-preservation organizations in the world. The Wayback Machine has assumed a default position as a safety valve against digital oblivion. The rhapsodic regard the Internet Archive inspires is earned—without it, the world would lose its best public resource on internet history.
Its employees are some of its most devoted congregants. “It is the best of the old internet, and it’s the best of old San Francisco, and neither one of those things really exist in large measures anymore,” says the Internet Archive’s director of library services, Chris Freeland, another longtime staffer, who loves cycling and favors black nail polish. “It’s a window into the late-’90s web ethos and late-’90s San Francisco culture—the crunchy side, before it got all tech bro. It’s utopian, it’s idealistic.”
But the Internet Archive also has its foes. Since 2020, it’s been mired in legal battles. In Hachette v. Internet Archive, book publishers complained that the nonprofit infringed on copyright by loaning out digitized versions of physical books. In UMG Recordings v. Internet Archive, music labels have alleged that the Internet Archive infringed on copyright by digitizing recordings.
In both cases, the Internet Archive has mounted “fair use” defenses, arguing that it is permitted to use copyrighted materials as a noncommercial entity creating archival materials. In both cases, the plaintiffs characterized it as a hub for piracy. In 2023, it lost Hachette. This month, it lost an appeal in the case. The Archive could appeal once more, to the Supreme Court of the United States, but has no immediate plans to do so. (“We have not decided,” Kahle told me the day after the decision.)
A judge rebuffed an attempt to dismiss the music labels’ case earlier this year. Kahle says he’s thinking about settling, if that’s even an option.
The combined weight of these legal cases threatens to crush the Internet Archive. The UMG case could prove existential, with potential fines running into the hundreds of millions. The internet has entrusted its collective memory to this one idiosyncratic institution. It now faces the prospect of losing it all.
Kahle has been obsessed with creating a digital library since he was young, a calling that spurred him to study artificial intelligence at MIT. “I wanted to build the library of everything, and we needed computers that were big enough to be able to deal with it,” he says.
After graduating in 1982, he worked at the supercomputing startup Thinking Machines Corporation. While there, he developed a program called Wide Area Information Server (WAIS), a way to search for data on remote computers. He left to cocreate a startup of the same name, which he sold to AOL in 1995. The next year, he launched a two-headed project from his attic: “AI and IA.”That “AI” was a for-profit company called Alexa Internet—“Alexa” a nod to the Library of Alexandria—alongside the nonprofit Internet Archive. The two projects were interlinked; Alexa Internet crawled the web, then donated what it collected to the Internet Archive. Kahle couldn’t quite make the business model work. When Amazon made an offer in 1999, it seemed prudent to accept. The Everything Store paid a reported $250 million in stock for Alexa, severing the AI from IA and leaving Kahle a wealthy man.
Kahle stayed on with Alexa for a few years but left in 2002 to focus on the Internet Archive. It has been his vocation ever since. “His entire being is committed to the Archive,” says copyright scholar Pam Samuelson, who has known Kahle since the ’90s. “He lives and breathes it.”
If Silicon Valley has a Mr. Fezziwig, it’s Kahle. He’s not an ascetic; he owns a handsome black sailboat anchored in a slip at a tony yacht club. But his day-to-day life is modest. He ebikes to work and dresses like a guy who doesn’t care about clothes, and while he used to love Burning Man—he and his wife, Mary Austin, got married there in 1992—now he thinks it’s gotten too big. (Their current bougie-hippie pastime is the seasteading gathering Ephemerisle, where boaters hitch themselves together and create temporary islands in the Sacramento River Delta every July.)
What he really loves, above all, is his job.
“The story of Brewster Kahle is that of a guy who wins the lottery,” says longtime archivist Jason Scott. “And he and his wife, Mary, turned around and said, awesome, we get to be librarians now.”
Kahle is now the merry custodian to a uniquely comprehensive catalog, spanning all manner of digital and physical media, from classic video games to live recordings of concerts to magazines and newspapers to books from around the world. It recently backed up the island of Aruba’s cultural institutions. It’s an essential tool for everything from legal research—particularly around patent law—to accountability journalism. “There are other online archiving tools,” says ProPublica reporter Craig Silverman, “but none of them touch the Internet Archive.” It is, in short, a proof machine.What makes the Internet Archive unique is its willingness to push boundaries in ways that traditional libraries do not. The Library of Congress also archives the web—but only after it has notified, and often asked permission from, the websites it scrapes.
“The Internet Archive has always been a little risky,” says University of Waterloo historian Ian Milligan, who has a forthcoming book on web archiving. Its distinctive utility is entwined with its long-standing outré approach to copyright. In fact, Kahle and the Internet Archive sued the government more than two decades ago, challenging the way the Copyright Renewal Act of 1992 and the Copyright Term Extension Act of 1998 had expanded copyright law. He lost that case—but, certainly, not his desire to keep pushing.
One of those pushes came in 2005. At the time, beloved hacker Aaron Swartz was often working on Internet Archive projects, and he cocreated and led the development of a new initiative called the Open Library program along with Kahle. The goal was to create one webpage for every book in the world. Kahle saw it as an alternative to Google Books, one that wasn’t driven by commercial interests but loftier and decidedly kumbaya information-wants-to-be-free ambitions.
In addition to its attempt to catalog every book ever, the project sought to make copies available to readers. To that end, it scans physical books, then allows people to check out the digitized versions. For over a decade, it has operated using a framework called controlled digital lending (CDL), where digitized books are treated as old-fashioned physical books rather than ebooks. The books it lends out were either purchased by the Internet Archive or donated by other libraries, organizations, or individuals; according to CDL principles, libraries that own a physical copy of a book should be able to lend it digitally.
The project primarily appeals to researchers for whom specific books are hard to attain elsewhere, rather than casual readers. “Try checking out one of our books and then reading it—it’s tough going,” Kahle says. He’s not lying. A blurry scan of a physical book on a desktop screen compared to a regular ebook on a Kindle is like music from a tinny iPhone speaker versus a Bose surround sound system. Most borrowers read what they check out for less than five minutes.
Like other digital media, ebooks are typically licensed rather than sold outright, at a much higher rate than the cover price. Libraries who license ebooks get a limited number of loans; if they stop paying, the book vanishes. CDL is an attempt to give libraries more control over their inventory, and to expand access to books in a library’s collection that exist only as physical copies.
For years, publishers ignored the Internet Archive’s book-scanning spree. Finally, during the pandemic, after the Internet Archive took one liberty too many with its approach to CDL, they snapped.
In March 2020, as schools and libraries abruptly shut down, they faced a dilemma. Demand for ebooks far outstripped their ability to loan them out under restrictive licensing deals, and they had no way of lending out books that existed only in physical form. In response, the Internet Archive made a bold decision: It allowed multiple people to check out digital versions of the same book simultaneously. It called this program the National Emergency Library. “We acted at the request of librarians and educators and writers,” says Chris Freeland.
Kahle remembers feeling a vocational tug in that moment for the Internet Archive to do whatever it could to expand access. He thought they had broad support, too. “We got over 100 libraries to sign on and say ‘help us,’” Kahle says. “They stood behind the National Emergency Library and said ‘do this under our names.’”
Dave Hansen, now executive director of the nonprofit Authors Alliance, was a librarian at Duke University at the time. “We had tremendous challenges getting books for our students,” he says. “What they did was a good-faith effort.”
Not everyone agreed. Prominent writers vehemently criticized the project, as did the Authors Guild and the National Writers Union. “They are not a library. Libraries buy books and respect copyright. They are fraudsters posing as saints,” author James Gleick wrote on Twitter. (Today, Gleick maintains that the Internet Archive is not a library, though he says “fraudsters was a little harsh.”)
“They seem to work by fiat,” says Bhamati Viswanathan, a copyright lawyer who signed an amicus brief on behalf of the publishers in the Hachette case. Viswanathan thinks it was arrogant to circumvent the licensing system. “Very much like what the tech companies seem to be doing, which is, ‘we’re going to ask forgiveness, not permission.’”
The Internet Archive was in its first full-blown PR crisis. The coalition of publishing houses filed its lawsuit in June 2020, alleging that both the National Emergency Library and the Internet Archive’s broader Open Library program violated copyright. A few weeks later, the Internet Archive scuttled the National Emergency Library and reverted to its traditional, capped loan system, but it made no difference to the publishers.
The publishing houses and their supporters maintain that the Archive’s behavior harmed authors. “Internet Archive is arguing that it is OK to make and publicly distribute unauthorized copies of an author’s work to the global public,” Terrance Hart, the general counsel for the Association of American Publishers, tells WIRED. “Imagine if everyone started doing the same. The only existential threat here is the one posed by Internet Archive to the livelihoods of authors and to the copyright system itself in the digital age.”
AI Lab
WIRED’s resident AI expert Will Knight takes you to the cutting edge of this fast-changing field and beyond—keeping you informed about where AI and technology are headed. Delivered on Wednesdays.
After the lawsuit was filed, over a thousand writers signed a letter in support of libraries and the Internet Archive to be able to loan digital books, including Naomi Klein and Daniel Ellsberg. One supportive author, Chuck Wendig, had very publicly changed his mind after initially tweeting criticism. Even some writers who currently belong to and support the Authors Guild, like Joanne McNeil, were staunch supporters of the Archive. She sometimes reads out-of-print books using the lending service and still sees it as a vital tool. “I hope my books are in the Open Library project,” she says, telling me that she’s already aware that her critically acclaimed but modestly popular books aren’t widely available. “At least I’ll know that way there’s someplace someone can find them.”
The shows of support didn’t matter. The publishers didn’t back down. In March 2023, the Internet Archive lost the case. This September, it lost its appeal. The court refuted the fair use arguments, insisting that the organization had not proved that it wasn’t financially harming publishers. In the meantime, legal bills continue to pile up for the Internet Archive’s next challenge.
After the initial ruling in Hachette v. Internet Archive, the parties agreed upon settlement terms; although those terms are confidential, Kahle has confirmed that the Internet Archive can financially survive it thanks to the help of donors. If the Internet Archive decides not to file a second appeal, it will have to fulfill those settlement terms. A blow, but not a death knell.The other lawsuit may be far harder to survive. In 2023, several major record labels, including Universal Music Group, Sony, and Capitol, sued the Internet Archive over its Great 78 Project, a digital archive of a niche collection of recordings of albums in the obsolete record format known as 78s, which was used from the 1890s to the late 1950s. The complaint alleges that the project “undermines the value of music.” It lists 2,749 recordings as infringed, which means damages could potentially be over $400 million.
“One thing that you can say about the recording industry,” Pam Samuelson says, “is that there are no statutory damages that are too large for them to claim.”
As with the book publishing case, the Internet Archive’s defense hinges on fair use. It argues that preserving obsolete versions of these records, complete with the crackles and pops from the old shellac resin, makes history accessible. Copyright law is notoriously unpredictable, and some find the Internet Archive’s case shaky. “It doesn’t strike me, necessarily, as a winning fair use argument,” says Zvi Rosen, a law professor at Southern Illinois University who focuses on copyright.
James Grimmelmann, a professor of digital and information law at Cornell University, thinks the labels are “vastly exaggerating the commercial harm” from the project. (If there was a sizable audience for extremely low-quality versions of songs, he reasons, why wouldn’t the labels be putting out 78-style releases?) On average, each recording is accessed only once a month. Still, Grimmelmann isn’t convinced that will matter. “They are directly reproducing these works,” he says. “That’s a very hard lift for a judge.”
It may be years before the case is resolved, which means the uncertainty about the Internet Archive’s future is likely to linger, and potentially spread. And if it is resolved through either a settlement or a win for the recording industry, other copyright holders could be inspired to sue. “I’m worried about the blast radius from the music lawsuit,” Grimmelmann says.In Kahle’s view, the Internet Archive’s legal challenges are part of a larger story about beleaguered libraries in the United States. He likes to frame his plight as a battle against a cadre of nefarious publishers, one piece of a larger struggle to wrest back the right to own books in the digital age. (Get him started on the topic, and he’ll likely point out that both ebook distributor OverDrive and publishing company Simon & Schuster are owned by the global investment firm Kohlberg Kravis Roberts & Co.) He’s keenly aware that everything he has built is in danger. “It’s the time of Orwell but with corporations,” Kahle says. “It’s scary.”
Losing the Archive is, indeed, a frightening prospect. “There is a misperception that things on the web are forever—but they really, really aren’t,” says Craig Silverman, who thinks the nonprofit’s demise would make certain types of scholarship and reporting “way more difficult, if not impossible,” in addition to representing a disappearance of a bastion of collective memory.
Just this September, Google and the Internet Archive announced a partnership to allow people to see previous versions of websites surfaced through Google Search by linking to the Wayback Machine. Google previously offered its own cached historical websites; now it leans on a small nonprofit.
The Internet Archive also has challenges beyond its legal woes. For starters, it’s getting harder to archive things. As Mark Graham, director of the Wayback Machine, told me, the rise of apps with functions like livestreaming, especially when they’re limited to certain operating systems, presents a technical challenge. On top of that, paywalls are an obstacle, as is the sheer and ever-increasing amount of content. “There’s just so much material,” he says. “How does one know what to prioritize?”
Then there’s AI, once again. Thus far, the Internet Archive has sidestepped or been exempt from the new scrutiny on web crawling as it relates to AI training data. This June, for example, when Reddit announced that it was updating its scraping policy, it specifically noted that it was still allowing “good faith actors” like the Internet Archive to crawl it. But as opposition to rampant AI data scraping grows, the Internet Archive may yet face a new obstacle: If regulators and lawmakers are clumsy in attempts to curb permissionless AI web scraping, it could kneecap services like the Wayback Machine, which functions precisely because it can trawl and reproduce vast amounts of data.
The rise of AI has already soured some creative types on the Internet Archive’s approach to copyright. While Kahle views his creation as a library on the side of the little guy, opponents strenuously dispute this view. They paint Kahle as a tech-wolf disguised in librarian-sheep clothing, stuck in a mentality better suited for the Napster era. “The Internet Archive is really fighting the battles of 20 years ago, when it was as simple as ‘publishers bad, anything that hurts publishers good,’” says Neil Turkewitz, a former Recording Industry Association of America executive who has criticized the Archive’s copyright stances. “But that’s not the world we live in.”
When I talk to Kahle over Zoom this September, shortly after he’d learned that the Internet Archive had lost the appeal, he’s agitated—an internet prophet literally wandering around in the wilderness. He’s perched in front of jagged cliffs while hiking outside of Arles, France, a blue baseball cap pulled over his hair, cheeks extra-ruddy in the sun, his default affability tempered by a sense of despondency. He hadn’t known about the timing of the ruling in advance, so he interrupted a weeklong vacation with Mary to jump back into work crisis mode. “It’s just so depressing,” he says.
As he sits on a rock with his phone in his hand, Kahle says the US legal system is broken. He says he doesn’t think this is the end of the lawsuits. “I think the copyright cartel is on a roll,” he says. He frets that copycat cases could be on the way. He’s the most bummed-out guy I’ve ever seen on vacation in the south of France. But he’s also defiant. There’s no inkling of regret, only a renewed sense that what he’s doing is righteous. “We have such an opportunity here. It’s the dream of the internet,” he says. “It’s ours to lose.” It sounds less like a statement and more like a prayer.
Google took to Twitter this weekend to complain that iMessage is just too darn influential with today’s kids. The company was responding to a Wall Street Journal report detailing the lock-in and social pressure Apple’s walled garden is creating among US teens. iMessage brands texts from iPhone users with a blue background and gives them additional features, while texts from Android phones are shown in green and only have the base SMS feature set. According to the article, „Teens and college students said they dread the ostracism that comes with a green text. The social pressure is palpable, with some reporting being ostracized or singled out after switching away from iPhones.“ Google feels this is a problem.
„iMessage should not benefit from bullying,“ the official Android Twitter account wrote. „Texting should bring us together, and the solution exists. Let’s fix this as one industry.“ Google SVP Hiroshi Lockheimer chimed in, too, saying, „Apple’s iMessage lock-in is a documented strategy. Using peer pressure and bullying as a way to sell products is disingenuous for a company that has humanity and equity as a core part of its marketing. The standards exist today to fix this.“
The „solution“ Google is pushing here is RCS, or Rich Communication Services, a GSMA standard from 2008 that has slowly gained traction as an upgrade to SMS. RCS adds typing indicators, user presence, and better image sharing to carrier messaging. It is a 14-year-old carrier standard, though, so it lacks many of the features you would want from a modern messaging service, like end-to-end encryption and support for non-phone devices. Google tries to band-aid over the aging standard with its „Google Messaging“ client, but the result is a lot of clunky solutions that don’t add up to a good modern messaging service.
Since RCS replaces SMS, Google has been on a campaign to get the industry to make the upgrade. After years of protesting, the US carriers are all onboard, and there is some uptake among the international carriers, too. The biggest holdout is Apple, which only supports SMS through iMessage.
Enlarge/ Apple’s green-versus-blue bubble explainer from its website.
Apple
Apple hasn’t ever publicly shot down the idea of adding RCS to iMessage, but thanks to documents revealed in the Epic v. Apple case, we know the company views iMessage lock-in as a valuable weapon. Bringing RCS to iMessage and making communication easier with Android users would only help to weaken Apple’s walled garden, and the company has said it doesn’t want that.
In the US, iPhones are more popular with young adults than ever. As The Wall Street Journal notes, „Among US consumers, 40% use iPhones, but among those aged 18 to 24, more than 70% are iPhone users.“ It credits Apple’s lock-in with apps like iMessage for this success.
Reaping what you sow
Google clearly views iMessage’s popularity as a problem, and the company is hoping this public-shaming campaign will get Apple to change its mind on RCS. But Google giving other companies advice on a messaging strategy is a laughable idea since Google probably has the least credibility of any tech company when it comes to messaging services. If the company really wants to do something about iMessage, it should try competing with it.
As we recently detailed in a 25,000-word article, Google’s messaging history is one of constant product startups and shutdowns. Thanks to a lack of product focus or any kind of top-down mandate from Google’s CEO, no division is really „in charge“ of messaging. As a consequence, the company has released 13 half-hearted messaging products since iMessage launched in 2011. If Google wants to look to someone to blame for iMessage’s dominance, it should start with itself, since it has continually sabotaged and abandoned its own plans to make an iMessage competitor.
Messaging is important, and even if it isn’t directly monetizable, a dominant messaging app has real, tangible benefits for an ecosystem. The rest of the industry understood this years ago. Facebook paid $22 billion to buy WhatsApp in 2014 and took the app from 450 million users to 2 billion users. Along with Facebook Messenger, Facebook has two dominant messaging platforms today, especially internationally. Salesforce paid $27 billion for Slack in 2020, and Tencent’s WeChat, a Chinese messaging app, is pulling in 1.2 billion users and yearly revenues of $5.5 billion. Snapchat is up to a $67 billion market cap, and Telegram is getting $40 billion valuations from investors. Google keeps trying ideas in this market, but it never makes an investment that is anywhere close to the competition.
Google once had a functional competitor to iMessage called Google Hangouts. Circa 2015, Hangouts was a messaging powerhouse; in addition to the native Hangouts messaging, it also supported SMS and Google Voice messages. Hangouts did group video calls five years before Zoom blew up, and it had clients on Android, iOS, the web, Gmail, and every desktop OS via a Chrome extension.
As usual, though, Google lacked any kind of long-term plan or ability to commit to a single messaging strategy, and Hangouts only survived as the „everything“ messenger for a single year. By 2016, Google moved on to the next shiny messaging app and left Hangouts to rot.
Even if Google could magically roll out RCS everywhere, it’s a poor standard to build a messaging platform on because it is dependent on a carrier phone bill. It’s anti-Internet and can’t natively work on webpages, PCs, smartwatches, and tablets, because those things don’t have SIM cards. The carriers designed RCS, so RCS puts your carrier bill at the center of your online identity, even when free identification methods like email exist and work on more devices. Google is just promoting carrier lock-in as a solution to Apple lock-in.
Despite Google’s complaining about iMessage, the company seems to have learned nothing from its years of messaging failure. Today, Google messaging is the worst and most fragmented it has ever been. As of press time, the company runs eight separate messaging platforms, none of which talk to each other: there is Google Messages/RCS, which is being promoted today, but there’s also Google Chat/Hangouts, Google Voice, Google Photos Messages, Google Pay Messages, Google Maps Business Messages, Google Stadia Messages, and Google Assistant Messaging. Those last couple of apps aren’t primarily messaging apps but have all ended up rolling their own siloed messaging platform because no dominant Google system exists for them to plug into.
The situation is an incredible mess, and no single Google product is as good as Hangouts was in 2015. So while Google goes backward, it has resorted to asking other tech companies to please play nice with it while it continues to fumble through an incoherent messaging strategy.
The iPhone maker cultivated iMessage as a must-have texting tool for teens. Android users trigger a just-a-little-less-cool green bubble: ‘Ew, that’s gross.’
Soon after 19-year-old Adele Lowitz gave up her AppleAAPL 0.51% iPhone 11 for an experimental go with an Android smartphone, a friend in her long-running texting group chimed in: “Who’s green?”
The reference to the color of group text messages—Android users turn Apple Inc.’s iMessage into green bubbles instead of blue—highlighted one of the challenges of her experiment. No longer did her group chats work seamlessly with other peers, almost all of whom used iPhones. FaceTime calls became more complicated and the University of Michigan sophomore’s phone didn’t show up in an app she used to find friends.
That pressure to be a part of the blue text group is the product of decisions by Apple executives starting years ago that have, with little fanfare, built iMessage into one of the world’s most widely used social networks and helped to cement the iPhone’s dominance among young smartphone users in the U.S.
How that happened came to light last year during Apple’s courtroom fight against “Fortnite” maker Epic Games Inc., which claimed the tech giant held an improper monopoly over distribution of apps onto the iPhone. As part of the battle, thousands of pages of internal records were made public. Some revealed a long-running debate about whether to offer iMessage on phones that run with Google’s Android operating system. Apple made a critical decision: Keep iMessage for Apple users only.
“In the absence of a strategy to become the primary messaging service for [the] bulk of cell phone users, I am concerned the iMessage on Android would simply serve to remove [an] obstacle to iPhone families giving their kids Android phones,” Craig Federighi, Apple’s chief software executive, said in a 2013 email. Three years later, then-marketing chief Phil Schiller made a similar case to Chief Executive Tim Cook in another email: “Moving iMessage to Android will hurt us more than help us,” he said. Another warning that year came from a former Apple executive who told his old colleagues in an email that “iMessage amounts to serious lock-in.”
When Adele Lowitz, left, experimented with using an Android smartphone instead of an iPhone, one friend asked: ‘Who’s green?’ PHOTO: STEVE KOSS FOR THE WALL STREET JOURNAL
When Adele Lowitz, left, experimented with using an Android smartphone instead of an iPhone, one friend asked: ‘Who’s green?’ PHOTO: STEVE KOSS FOR THE WALL STREET JOURNAL
From the beginning, Apple got creative in its protection of iMessage’s exclusivity. It didn’t ban the exchange of traditional text messages with Android users but instead branded those messages with a different color; when an Android user is part of a group chat, the iPhone users see green bubbles rather than blue. It also withheld certain features. There is no dot-dot-dot icon to demonstrate that a non-iPhone user is typing, for example, and an iMessage heart or thumbs-up annotation has long conveyed to Android users as text instead of images.
Apple later took other steps that enhanced the popularity of its messaging service with teens. It added popular features such as animated cartoon-like faces that create mirrors of a user’s face, to compete with messaging services from social media companies. Apple’s own survey of iPhone holders made public during the Epic Games litigation found that customers were particularly fond of replacing words with emojis and screen effects such as animated balloons and confetti. Avid teen users said in interviews with The Wall Street Journal that they also liked how they could create group chats with other Apple users that add and subtract participants without having to start a new chain.
How Apple’s iPhone and Apps Trap You in a Walled GardenYOU MAY ALSO LIKEUP NEXT 0:00 / 6:21 How Apple’s iPhone and Apps Trap You in a Walled GardenApple’s hardware, software and services work so harmoniously that it is often called a “walled garden.” The idea is central to recent antitrust scrutiny and the Epic vs. Apple case. WSJ’s Joanna Stern went to a real walled garden to explain it all. Photo illustration: Adele Morgan/The Wall Street Journal
The cultivation of iMessage is consistent with Apple’s broader strategy to tie its hardware, software and services together in a self-reinforcing world—dubbed the walled garden—that encourages people to pay the premium for its relatively expensive gadgets and remain loyal to its brand. That strategy has drawn scrutiny from critics and lawmakers as part of a larger examination of how all tech giants operate. Their core question: Do Apple and other tech companies create products that consumers simply find indispensable, or are they building near-monopolies that unfairly stifle competition?
Apple in its fight against Epic Games denied it held improper monopoly power in the smartphone market, pointing to intense competition globally with other phone makers and Android’s operating system. “With iMessage we built a great service that our users love and that is different from those offered by other platforms,” the company said in a statement.
Apple and other tech giants have long worked hard to get traction with young users, hoping to build brand habits that will extend into adulthood as they battle each other for control of everything from videogames to extended reality glasses to the metaverse. Globally, Alphabet Inc.’s Android operating system is the dominant player among smartphone users, with a loyal following of people who are vocal about their support. Among U.S. consumers, 40% use iPhones, but among those aged 18 to 24, more than 70% are iPhone users, according to Consumer Intelligence Research Partners’s most recent survey of consumers.
Shoppers at an Apple store in November.
PHOTO: NIYI FOTE/ZUMA PRESS
Apple is not the first tech company to come up with a must-have chat tool among young people, and such services sometimes struggle to stay relevant. BlackBerry and America Online were among the popular online communication forums of past decades that eventually lost ground to newer entrants.
Yet grabbing users so early in life could pay dividends for generations for Apple, already the world’s most valuable publicly traded company. It briefly crossed $3 trillion in market value for the first time on Jan. 3.
“These teenagers will continue to become consumers in the future and hopefully continue to buy phones into their 40s, 50s, 60s and 70s,” said Harsh Kumar, an analyst for Piper Sandler. The firm recently found that 87% of teens surveyed last year own iPhones.
Never date a green texter
Apple’s iMessage plays a significant role in the lives of young smartphone users and their parents, according to data and interviews with a dozen of these people. Teens and college students said they dread the ostracism that comes with a green text. The social pressure is palpable, with some reporting being ostracized or singled out after switching away from iPhones.
“In my circle at college, and in high school rolling over into college, most people have iPhones and utilize a lot of those kinds of iPhone specific features” together, said Ms. Lowitz, the Michigan student.
She said she came to realize that Apple had effectively created a social network of features that keeps users, such as her and others, locked in. “There was definitely some kind of pressure to get back to that,” she said.
Many of the new iMessage features—such as the 3D-like digital avatars known as memojis—exist fundamentally as a reason to own an iPhone and don’t make money for Apple directly. Last year Apple also made it possible to share FaceTime connections with Android users—a slight crack in Apple’s self-reinforcing ecosystem as video calling became more prevalent during the pandemic. In recent years, however, it has incorporated some moneymaking elements including Apple Pay and e-commerce links to other businesses such as Starbucks.
“We know that Apple users appreciate having access to innovative features like iCloud synching across all their Apple devices, Tapback and Memoji, as well as industry-leading privacy and security with end-to-end encryption—all of which make iMessage unique,” Apple said in a statement.Youthful ExuberanceThe share of Apple iPhones in the U.S. has swelleddramatically among young smartphone owners. Source: Consumer Intelligence Research PartnersNote: Annual survey conducted each September of 2,000 U.S. peoplewho purchased a smartphone in the previous 12 months. Age 18-24Older than 242014’15’16’17’18’19’20’2120304050607080%
Apple’s iMessage uses the internet to send text, video and photo messages, while iPhone users communicating with non-Apple users use old-school cellular channels such as SMS and MMS. Apple said its closed, encrypted system ensures messages are protected from hackers. Apple also disputes the idea that users are locked in to iMessage, saying users can easily switch to other smartphones.
A Google executive said Apple could make it easier for iMessage and Android users to communicate. “There are no real technical or product reasons for this issue,” Hiroshi Lockheimer, Google senior vice president of platforms and ecosystems, said. “The solutions already exist and we encourage Apple to join with the rest of the mobile industry in implementing them. We believe people should have the ability to connect with each other without artificial limits. It simply doesn’t have to be like this.” TECH NEWS BRIEFINGWhat Apple’s Texting App Tells Us About Its Strategy to Attract Users 00:00
IPhone users switch among a variety of apps to communicate. But if you use an iPhone, it is likely you’re also using iMessage. Apple’s internal research made public during the Epic Games litigation found that a survey of U.S. iPhone users, some as young as 14, overwhelmingly use iMessage. Among those who used an instant messaging app at least once a month, 85% of those surveyed said they used iMessage compared with 57% and 16% using Meta’s Facebook Messenger and WhatsApp, respectively, the Apple research showed. Meta’s messaging apps are widely used globally. WhatsApp, for example, topped 2 billion users in 2020.
In the pitched battle for messaging, Facebook executives in recent years became interested in capturing users at a younger age, according to documents reviewed by the Journal that formed the basis of a series of articles, called the Facebook Files, published in recent months.
One Facebook study, shared internally in 2019, aimed to understand why iMessage and SnapInc.’s Snapchat were the primary messaging apps for 10- to 13-year-olds. The research focused attention on a popular game played through iMessage called “Game Pigeon.”
The third-party game, acquired through Apple’s App Store and designed to operate in the messaging app, illustrates just one of the ways iMessages connects with young people. The game consists of users taking turns playing activities, such as checkers or word games, and allows for texting back-and-forth among players. “Game Pigeon” can’t be played between iPhone and Android users.
Miles Franklin, a longtime Android loyalist, was left out of rounds of a popular online game in high school. He switched to an iPhone two years ago.
PHOTO: MILES FRANKLIN
Facebook researchers concluded the appeal revolved around the social aspect of the games, helping younger people initiate conversations. “Game Pigeon generates amusement through digital interaction without the pressures of finding topics of conversation by enabling tweens to send games as content interactions and to use shared activities as a way to connect when they feel there is nothing to talk about,” according to the study.
Rounds of “Game Pigeon” in high school among friends were the first time Miles Franklin said he realized he was left out with his Android phone. “That’s my first taste of it,” said Mr. Franklin, now a 22-year-old senior at the University of Florida in Gainesville.
He said he long considered himself an Android loyalist going back to when he got his first phone at age 13 for his birthday. That changed, however, two years ago when he switched to an iPhone because he preferred it for making TikTok videos.
While it seems simple enough to shift to another messaging service, it isn’t in real life, according to Mr. Franklin. “I personally would do that,” he said. “But I’m not everyone else. I can’t convince other people to switch over to another app because they’re not gonna want to do that unless you’re really close to them.”
Grace Fang, 20-years-old, said she too saw such social dynamics among her peers at Wellesley College in Massachusetts. “I’ve had people with Androids apologize that they have Androids and don’t have iMessage,” she said. “I don’t know if it’s Apple propaganda or just like a tribal in-group versus out-group thing going on, but people don’t seem to like green text bubbles that much and seem to have this visceral negative reaction to it.” Ms. Fang added that she finds the hubbub silly and that she prefers to avoid texting all together.
‘I’ve had people with Androids apologize that they have Androids and don’t have iMessage,” said Grace Fang.
PHOTO: ASHLEY PANDYA
Jocelyn Maher, a 24-year-old master’s student in upstate New York, said her friends and younger sister have mocked her for exchanging texts with potential paramours using Android phones. “I was like, `Oh my gosh, his texts are green,’ and my sister literally went, `Ew that’s gross,’” Ms. Maher said.
She noted that she once successfully persuaded a boyfriend to switch to an iPhone after some gentle badgering. Their relationship didn’t last.
Such interactions have made fertile ground for memes on social media. During the pandemic, Jeremy Cangiano, who just finished up his MBA at the University of Massachusetts Lowell, dealt with his boredom on TikTok, quickly noticing that blue-bubble-green-bubble memes were popular among young people. He tried to cash in on it last year by selling his own merchandise that touted, “Never Date a Green Texter.”
‘Serious lock-in’
The blue iMessage bubble was born out of a simple engineering need, according to Justin Santamaria, a former Apple engineer who worked on the original feature. At first, Apple engineers just wanted to be able to easily identify iMessages when working with other texting formats as they developed their system, he said. The effect just stuck as it moved forward for consumer rollout.
“I had no idea that there would be a cachet or like, `Ugh green bubble conversations,’” he said. The idea that it would keep users locked in to using Apple devices wasn’t even part of the conversation at the time, he said.
The idea of opening iMessage to Android users arose in 2013, according to some of the internal records made public during the courtroom fight with Epic Games. As a market rumor circulated that Google was considering the acquisition of the popular messaging app WhatsApp, senior Apple executives discussed how such an acquisition might roil competition and how they might better compete.
Eddy Cue, who oversees Apple’s services business, told his colleagues he had some of his team investigating how to make iMessage available on Android phones, according to an email that surfaced as part of the Epic Games litigation. “We should go full speed and make this an official project,” he advised. “Google will instantly own messaging with this acquisition.”
SHARE YOUR THOUGHTS
How has the blue-green bubble battle played out in your own social circle? Join the conversation below.
Mr. Schiller, the executive who at the time oversaw marketing, wrote: “And since we make no money on iMessage what will be the point?” Mr. Cue responded: “Do we want to lose one of the most important apps in a mobile environment to Google? They have search, mail, free video and growing quickly in browsers. We have the best messaging app and we should make it the industry standard. I don’t know what ways we can monetize it but it doesn’t cost us a lot to run.”
Others weighed in. Mr. Federighi, Apple’s chief software executive, said in an email that he worried that making iMessage an option on Android could have a serious downside by removing an obstacle for iPhone families to get their children Android phones.
In the end, Google didn’t buy WhatsApp and Apple didn’t make its iMessage available to Android users. Facebook ultimately acquired WhatsApp in 2014 for $22 billion, ratcheting up competition with Apple.
In just a few years, the value of iMessage’s blue texts had become more clear to Apple execs. After an executive left the company and began using an Android, he wrote former colleagues in 2016 and said he had switched back to iPhones after just a few months.
His family resorted to using Facebook products to message him, former Apple Music executive Ian Rogers said in the email. “I missed a ton of messages from friends and family who all use iMessage and kept messaging me at my old address,” he wrote, adding that “iMessage amounts to serious lock-in.”
The note, which became public during Apple’s litigation with Epic Games, eventually made its way to Mr. Cook through then-marketing chief Mr. Schiller, who added his own two cents: “Moving iMessage to Android will hurt us more than help us, this email illustrates why.”
As for Ms. Lowitz, the Michigan college student, she was glad when her switch to Android—brought about by her participation in a paid research study—came to an end. She was ready to get back to her iPhone. “There’s too much within the Apple network for me to switch,” she said.
Anna Fuder, 19, a friend at Michigan who had declined to participate in the study for fear of giving up her iPhone, was overjoyed. “As soon as she switched back to her iPhone, it was like hallelujah,” Ms. Fuder said. “Blue again.
Google Talk, Google’s first-ever instant messaging platform, launched on August 24, 2005. This company has been in the messaging business for 16 years, meaning Google has been making messaging clients for longer than some of its rivals have existed. But thanks to a decade and a half of nearly constant strategy changes, competing product launches, and internal sabotage, you can’t say Google has a dominant or even stable instant messaging platform today.
Google’s 16 years of messenger wheel-spinning has allowed products from more focused companies to pass it by. Embarrassingly, nearly all of these products are much younger than Google’s messaging efforts. Consider competitors like WhatsApp (12 years old), Facebook Messenger (nine years old), iMessage (nine years old), and Slack (eight years old)—Google Talk even had video chat four years before Zoom was a thing.
Currently, you would probably rank Google’s offerings behind every other big-tech competitor. A lack of any kind of top-down messaging leadership at Google has led to a decade and a half of messaging purgatory, with Google both unable to leave the space altogether and unable to commit to a single product. While companies like Facebook and Salesforce invest tens of billions of dollars into a lone messaging app, Google seems content only to spin up an innumerable number of under-funded, unstable side projects led by job-hopping project managers. There have been periods when Google briefly produced a good messaging solution, but the constant shutdowns, focus-shifting, and sabotage of established products have stopped Google from carrying much of these user bases—or user goodwill—forward into the present day.
Because no single company has ever failed at something this badly, for this long, with this many different products (and because it has barely been a month since the rollout of Google Chat), the time has come to outline the history of Google messaging. Prepare yourselves, dear readers, for a non-stop rollercoaster of new product launches, neglected established products, unexpected shut-downs, and legions of confused, frustrated, and exiled users.
Google Talk (2005)—Google’s first chat service, built on open protocols
Lifetime: August 24, 2005-June 26, 2017 (12 years, until a Hangouts merger in 2013)
Clients: Windows, Android, the web, Gmail, Blackberry, iPhone, iGoogle, Orkut, any XMPP client
In the beginning, there was Google Talk, and things were good. Google’s first messaging service (which often got the unofficial nickname „GChat“) was also one of its best. It boasted a wide range of platform support, a long shelf life, and useful integration in a number of other Google products. Google Talk was part of the second big wave of popular instant messaging apps, and it seemed primed to take on the 1990’s stalwarts of instant messaging like AOL Instant Messenger (AIM), ICQ, Yahoo Messenger, and Windows Live Messenger.
So much about Google Talk’s life and design sounds like it was created by a totally different company from the Google that exists today. The original vision for Google Talk was about openness and „enabling user choice.“ Google wanted instant messaging to work like email, where different service providers and clients could all talk to each other over a single standard (wouldn’t that have been nice?). That standard was XMPP, or the „Extensible Messaging and Presence Protocol,“ an open source communication protocol used for passing around chat messages, presence information, contacts, and more. Google pledged to federate (or allow cross-communication) with any other chat service supporting the standard. You could also punch the right settings into any XMPP-compatible third-party client and talk to your Google Talk friends.
Because Ars Technica is a Very Old Website, you can still read a day-one, 2005 Google Talk review right here from Ars Editor-in-Chief Ken Fisher (can you believe Ken used to write articles?). Back then, Ken called day-one Google Talk „the Stone Age of instant messaging,“ citing a severe lack of features like file sharing, chat logs, group chat, or emoticons. There was one supported platform at launch: Microsoft Windows. That was mostly fine in 2005 when Windows had something like a 97 percent market share. Even then, XMPP support meant that you could still get online with the other 3 percent of operating systems by using a ton of third-party clients.
There will be a few recurring themes in this exhaustive history, and one of them is Google’s penchant for launching things in a „Minimum Viable Product“ (MVP) state. MVP is Silicon Valley project manager lingo for launching with the absolute bare minimum of features, getting feedback from the public quickly, and letting that feedback determine the future of the product. The idea is that it’s cheaper, easier, and less risky than developing a fully featured product in a bubble, since such a product might miss the mark with the public despite all the work. The downside to an MVP launch is that your product gets the most attention and news coverage when it is brand new, and you’re often giving a bad first impression. In a competitive landscape, there’s a chance the public will check out your bare-bones creation, declare it to be hopeless, and forget about it.
Enlarge/ Google Talk versus its competitors from around 2005-2006. The clean UI was a major advantage. Credit: Google, Techcrunch,Google OS,wlmgined.
Google does MVP launches all the time, and with Google Talk, that meant launching with the ability to send messages, do voice chat, and little else. Later we’ll cover some of Google’s dead-on-arrival MVP launches, but 2005 was a different era. Many people saw Google Talk’s bare-bones interface and features as a positive thing. In the era of AOL Instant Messenger, IM clients were noisy, flashy billboards with a million features and dedicated UI space for banner ads. A 2006 post from the Google Operating System blog sums up the differences well with installer file sizes, which is an interesting benchmark metric. Yahoo Messenger was 9.5MB. Windows Live Messenger was 15.3MB. Google Talk was a lean, mean 1.45MB.
While the AOL-style kitchen sink design was horrible, it also solved a key problem that will hang over Google’s efforts: „How does a messaging service make money?“ Back in the AIM days, that was answered with a literal banner ad in the UI. Every AOL user was generating ad impressions and revenue every time they used the service. Google Talk’s removal of the banner ad was a breath of fresh air, but it also meant the product had no plan for making money. The vast majority of Google’s messaging apps have nothing to offer when it comes to the monetization question. Maybe that’s a big part of why we’re here.
While Google Talk launched as a basic product, once it was out the door, a series of rapid-fire updates followed. In December, Google bought a 5 percent stake in AOL for $1 billion and promised a cross-communication between AIM, ICQ, and Google Talk. January 2006 saw the first official mobile client: a Blackberry app (Android did not exist yet) and federation with the public XMPP network. In February, Google Talk became integrated with Gmail on the web and added chat logs. Avatar support came in March, and July brought file transfers, voicemail, and sharing music status. September opened up Google Talk to non „Gmail accounts“ (this pre-dates unified Google accounts), and November added integration with Orkut, a social network the company launched two years earlier. By the end of the year, Google announced plans for integration with traditional phone systems, letting you dial a phone number from your computer.
The Gmail integration at around the six-month mark was a big deal for Google Talk. Chat contacts got a spot in the Gmail sidebar, and chat messages would appear as pop-up windows alongside your email. As Google put it in its blog post, „Gmail is now just another XMPP client that connects to the Google Talk network.“ If Gmail users didn’t check out Google Talk when it first launched or gave up on it after trying the bare-bones launch, they would definitely be reminded of it now that it got a headline spot in the Gmail interface.
A lot of Google’s future instant messaging decisions seem to be about recapturing the magic of Google Talk, and it seems like one of the lessons learned was „leverage the rest of the Google user base to shove your new product in front of users.“ Like with MVP launches, this strategy would fail spectacularly in the future, but it worked out for Google Talk. Web-based IM was novel in 2006, and casting a slightly wider net with Gmail from „email“ to „communication“ made sense. Gmail integration also brought with it chat logging, via a searchable, cloud-stored „chat“ label in Gmail. Being able to dig through all your email and chats with a single search was great.
That was basically the first year of Google Talk’s existence, and the overwhelming feeling at the time was „optimism.“ While the original MVP release could have turned off some users, Google quickly addressed complaints with the original release, and Talk felt like a growing instant messaging service with a bright future and lots of resources behind it. Plus, it was from Google. In the 2005-era, Google was a rocketship. This was a company that recently disrupted the web email market with the launch of Gmail and its astounding 1GB of free online storage. Google Maps had just arrived with the revolutionary ability to move the map around without having to reload the entire website. Google had just had an IPO! This was a company that was regularly up-ending existing markets, and now the company was going to be a dominant force in the instant messaging market, right?
Many of Google Talk’s clients were for things you’ve probably forgotten about. A client for the „iGoogle“ customizable homepage arrived in 2007, along with a standalone web client at Google.com/talk. Today, Google developing a single native Windows app sounds crazy, but in 2008, a second Windows client called the „Google Talk Labs Edition“ just threw the web edition of Google Talk into a Win32 WebKit box, complete with support for notifications. Google really started to neglect the native Windows client once this launched, making the Labs Edition—basically the web edition—the premiere version.
In 2008, Google Talk arrived on the iPhone via—who remembers this?—a mobile web app! While the iPhone launched in 2007, the native iPhone app store did not launch until later in 2008, and developers were limited to web apps made for Safari.
Google’s 2008 video introducing video chat in Gmail. I love that this video dedicates a few sentences to the concept of video chat in general, as if people wouldn’t be familiar.
2008 also would mark Google’s first foray into video chat, first with Google Talk in Gmail and later in the main client. A side project from all this messaging research will be „Google is also terrible at video chat.“ While this video iteration wasn’t yet the group video chat solution that Google is still scrambling to get together in the coronavirus age, Google’s video chat ambitions actually started 12 years ago.
Google Talk’s voice and video chat required a browser plugin. It ran on technology from a company called „Global IP Solution (GIPS),“ which sold VoIP engines to companies like Google, AOL, Yahoo, Oracle, and WebEx. In 2010, Google decided it relied enough on the company and bought GIPS for $68 million. A year later, Google open-sourced GIPS’s technology and IP, giving birth to the WebRTC project. Today, WebRTC is the dominant VoIP technology and a W3C standard, allowing most web browsers to make a voice or video call with zero plugins.
Google Talk ran Android’s entire push notification system
By 2008, a little operating system called „Android“ came out of the Googleplex. BBM—Blackberry Messenger—had launched a few years earlier and was a valued feature of Blackberry phones, and so the Android Team became big fans of Google Talk, which it could use as a BBM fighter. The team shipped an original client along with Android 1.0 and added video chat support in 2011. Android didn’t just support Google Talk, though; it was actually a core feature of the operating system. Android’s entire cloud messaging system runs on XMPP, and, in the beginning at least, it was the same always-on Google connection as your Google Talk account. In fact, for a long time, Android’s background process for all push notifications and syncing was called „GTalkService.“
GTalkService ran communication for Android’s entire push notification system, meaning that even things like a new Gmail notification came blasting down an always-on chat session between you and Google. XMPP was a real-time, authenticated way to quickly pass messages back and forth, so Google built an OS-wide notification system around it. The early days of Android development were done at a break-neck pace to try to catch up to the iPhone, and messy decisions like merging push notifications with your in-house messaging service helped get there faster.
Google eventually opened up the push system to third parties, first with Android „Cloud to Device Messaging,“ then „Google Cloud Messaging,“ and then „Firebase Cloud Messaging.“ (If you haven’t noticed, Google likes to reboot and rename products.) The modern Firebase Cloud Messaging is actually still XMPP-based to this day, though. Of course, it has been separated from Google Talk now.
I am just going to go ahead and call GTalkService the early ancestor of Google Play Services. GTalkService wasn’t only used for notifications on Android—the cloud synchronization of Google account data also ran through the GTalkService, keeping things like your contacts and calendar events up to date. GTalkService was even used to install apps on Android. The co-founder of Duo Security, Jon Oberheide, has two fantastic writeups on GTalkService from 2010. As he explains, „When you click to install an app through the Android Market, Google pushes down an INSTALL_ASSET to your phone [over GtalkService] which causes it to fetch and install that application.“ You didn’t actually request the app package from the Android app store, they were pushed to your phone via Google Talk. (Did I mention early Android development was quick and dirty?)
The benefit of doing app install calls over push notifications is that you don’t actually have to be in front of your phone to install an app. Google surfaced this feature with the Android Market (now Play Store) website, where you could remotely install a phone app from your desktop web browser—it’s all the same push request. GTalkService even gives Google a nuclear option for malware. The company could remotely uninstall malicious apps from your phone, without your permission! Oberheide holds the distinction of being the first person to trigger a remote, mass uninstall after uploading a (harmless) malware proof-of-concept app to the Android Market in 2010. After unveiling its malware nuke to the world, Google warned: „While we hope to not have to use it, we know that we have the capability to take swift action on behalf of users’ safety when needed.“
The slow death of GTalk
After maybe 2009, not much happened with Google Talk. The Android team kept building mobile clients up until 2011, but it seemed like the original team lost interest in the service. This is how it always works with Google chat services. The ones that don’t get shut down eventually are abandoned and left to rot. Users get frustrated with the lack of continual development and old clients and slowly migrate to other services. Eventually, a new Google team comes along with plans to reboot everything.
The shutdown of Google Talk was a very slow transition, and with the plethora of clients, the merger with Google Hangouts, and third-party XMPP support, it’s hard to pick an exact time of death. But the beginning of the end for Google Talk was in 2013 with the release of the Hangouts chat service we know today. Hangouts wasn’t just another messaging app, it was a replacement for Google Talk, allowing you to carry your contacts and messages to the new service. Some clients, like the Android Google Talk app, got an in-place automatic upgrade to Google Hangouts, along with optional transitions and replacements for most clients. The first major client shutdown came two years later when the Google Talk Windows client officially stopped accepting logins on February 23, 2015.
If you really wanted to go down with the ship, the last gasp for Google Talk was surprisingly late: June 26, 2017. At that point, third-party XMPP connections to the Google Talk service stopped working, the Gmail web integration was forcefully transitioned to Hangouts, and (if you had somehow dodged Android app updates for four continuous years) the legacy Google Talk app also stopped working. Google Talk had long become irrelevant with the rise of Hangouts in 2013, but if you wanted to pick a final death date, June 2017 is it. RIP Google Talk.
Part of the reason for the lengthy shutdown is that it wasn’t just „Google Talk: the consumer chat service“ that Google was turning off. It was also „Google Talk: The back end XMPP Google service“ that Google needed to make sure kept running, which by now had wound its tendrils into several services. Google Talk needed to be killed without interrupting service for Firebase Cloud Messaging, which grew out of the XMPP project. Google Docs actually had a bit of a service interruption when Google Talk finally shut down in 2017, too. While it was never cross-compatible with Google Talk, it turns out those pop-up chat boxes were actually based on Google Talk originally. A GSuite blog post in 2017 mentioned that, because „Docs Editors chat functionality is built on Google Talk,“ work needed to be done to „decouple the feature from Talk“ when it shut down. G Suite organizations that didn’t get their transitional Google Talk and Google Hangouts settings correct would briefly lose chat functionality.
Google really doesn’t do product shutdowns like this anymore: shutdowns where you had a lengthy four-year shutdown period and not just a relatively smooth transition to a new service but a fully optional transition that lasted several years. Today, the company is simply a lot more ruthless about kicking users off a service and abandoning them.
Google Talk got a really long section in this history, but it deserves it. As Google’s first and one of its most successful instant messaging services, it set the blueprint for everything that followed. If you pay attention, you’ll see future Google messaging services poorly try to copy Google Talk’s homework, often with disastrous results. When you’re the OG Google chat service, you’re adding new features that didn’t exist before for Google users. When you’re everything that comes after Google Talk, people are just asking, „How is this better than Google Talk?“
Google Voice (2009)—SMS and Phone calls get a dose of the Internet
Lifetime: March 11, 2009—Present
Clients: web, Android, iPhone, Web OS, Blackberry
It only took 3.5 years after the launch of Google Talk for a second Google messaging service to appear, though it actually had a good argument for why it should exist alongside Google Talk. In March 2009, Google asked the question: „What if we rigged up the phone system to the Internet?“ and Google Voice was born. Instead of a landline phone number or a cell phone number, Google Voice gave users a Google phone number—with an area code and everything—that was device agnostic. Your phone calls could be forwarded to other phone numbers based on the time or contact, and your text messages were accessible via the web and various apps.
The best part of Google Voice is having a number that really feels like you own it. In the early days of Google Voice, carriers made number porting as annoying as possible, and switching cell providers could mean losing your carrier-owned phone number. With Google Voice, it didn’t matter. You could give everyone your Google Voice number, and switching services just meant adding a new forwarding number that you never told anyone about.
The origins of Google Voice actually started back in 2007 when Google acquired GrandCentral Communications. GrandCentral was where all of Google Voice’s phone call (as opposed to messaging) functionality came from. It offered a new phone number with forwarding to other lines and an audio-only voicemail box that was accessible over the Internet. There wasn’t any texting functionality, though.
With the launch of Google Voice, Google added a ton of features to GrandCentral, like SMS support, conference calling, and low-cost international calling. The Googliest feature was voicemail transcription, where Google’s voice recognition AI would (attempt to) transcribe your voicemail into easily scannable text. In the early days, it wasn’t super accurate, but Voicemail transcription was still better than the black box of a play button. There was usually enough wonky text information to figure out if the voicemail was important or not. Voicemail transcription was one of Google’s first voice recognition products, and in the early days, Google Voice’s „creative“ interpretations of voicemail audio gave rise to the meme of sharing failed and funny Google Voice transcript errors. Take a look; Google’s speech-to-text technology has come a long way.
We’re here for the texting part of Google Voice, though, and SMSes to your Google Voice number worked just like a texting app. These showed up anywhere you had the app installed or on the web instead of being siloed on your phone. Since Google Voice was SMS, there were basically no features. Even getting MMS support was a long-running battle: it first showed up for Sprint users (via email) in 2011, but proper MMS support on all carriers didn’t arrive until 2017. Voice was never a flashy service, but since Google Voice was SMS, it let you talk with anyone, and it let you pull your dumb cell phone number into the cloud where it could work on multiple devices.
Voice was seen as a threat to carriers at the time, so the service ruffled a few feathers when it came out. When Google submitted an official Google Voice app to Apple’s app store, Apple rejected Google’s app and removed a few third-party Google Voice apps it had previously approved. This move drew the ire of the FCC, and it questioned Apple’s exclusive carrier partner at the time (in the US): AT&T. With free VoIP calls, SMS, and voicemails, Google Voice was an obvious threat to AT&T, which previously had been against VoIP apps on the iPhone. AT&T told the FCC it was not involved, however. Google said Apple VP Phil Schiller personally blocked the app, saying Apple didn’t want apps that „duplicated the core dialer functionality of the iPhone.“ Apple said it had not, in fact, rejected the Google Voice app, and it was still „studying“ the app. The Google Voice iPhone app was initially submitted in June 2009, and by the time of the FCC inquiry, the Google Voice app had been delayed for two months. Apple must have been doing a marathon study session!
Apple’s „studying“ continued for the entirety of 2009, and by January 2010 Google had launched a Google Voice mobile web app for iPhone and Palm’s WebOS (may it rest in peace). Apple ruled over the App Store with an iron fist, but it couldn’t stop the Internet, and Apple users could point their browser at the Google Voice mobile site and make calls, view voicemail, or send SMS all through a web page. The downside was that the web couldn’t do notifications at the time, so Google Voice didn’t really work well for receiving SMSes or voicemails. It wasn’t until November 2010 that Apple finally finished its meticulous study session and let Google Voice into the app store.
Google Voice is the first item on our list that is actually still around; every day that Google Voice continues to exist feels like a surprise. The service has been hanging around for 11 years now and has spent most of its life in the „neglect“ stage of a Google messaging service. It often feels like Google Voice exists in a dusty closet at Google HQ somewhere, and the company forgets about it for years at a time.
Besides seeing its share of neglect, Google Voice has also seen its share of shutdowns. Google Voice used to have a range of third-party apps, but Google killed them all in a single swing one day in 2014. The company declared that any third-party apps that worked with Google Voice phone calls or SMS—which, by the way, had been operating for years—were „unauthorized,“ „a threat to your security,“ and „violating the terms of service.“ Google didn’t want to allow third-party Voice apps but also didn’t want to develop the first-party app itself, so it left users stuck with the crappy, neglected app.
We’ve already talked about how Google Talk and the Android push notifications were built around XMPP, but would you believe Google Voice at one point also used XMPP? XMPP was used to connect calls, and with this open standard, users could rig up landline phones to work directly over the Google Voice system, making it a VoIP provider. You’d also get free voice calls. XMPP support was shut down in 2018, but it sounds like it was replaced with some kind of closed-off solution that can be licensed by some companies. Polycom, for instance, still makes Google Voice FXO VoIP Gateways.
Google Voice has seen a resurgence starting around the launch of Google Fi in 2015, which merged the Google Voice feature set with an MVNO service. The two services were so similar at launch that you couldn’t even have both a Google Fi number and a Google Voice number—you had to port your Voice number to Google Fi. Since then we’ve seen a renewed commitment to Google Voice from Google, with revamped apps launching in 2017. Google Voice became a part of GSuite in 2018 and got mobile VoIP calls in 2019.
Google Wave (2009)—An email killer from the future
Lifetime: May 28, 2009—January 31, 2012 (2 years, 8 months but declared dead August 4, 2010)
Platforms: The web
I personally believe that Google Wave does not belong on a list of messaging apps, but every time I leave it out of a messaging app discussion I inevitablyget comments saying, „I can’t believe you forgot Google Wave!“ To stop those, it’s this exercise’s policy to cast a wide net and cover borderline products, at the very least so we can formally define them as „not a messaging app.“ Thus, Wave makes the cut.
For the record: Google Wave was email, not a messaging app. It wasn’t really used for one-to-one communication, and at no point was it possible to deliver notifications to a phone. At Google I/O 2009, Google introduced Wave to the world specifically as an email alternative, with co-creator Lars Rasmussen saying „Email was invented over 40 years ago…what might email look like if it was invented today?“ At no point was Wave out to replace Google Talk.
On the desktop, Wave had three main columns: a navigation and contact column on the right, an inbox in the middle, and a message view on the right. Like email, Wave would let you create message threads, and users could reply to either an entire group or a single person. Because Wave was hosted content and not email text that was copied to local computers, contact selection worked more like a modern permission system or chat room. You could grant or remove access to Wave threads by adding or removing people.
Wave was the first Google product to do real-time, letter-by-letter communication. The service would instantly send each keystroke across the Internet, and it would show up on another person’s screen, all through the magic of HTML5. Active Wave threads looked alive, with replies popping up, and images being uploaded in real time, letter by letter, without refreshing the page. Wave even had a feature called „Playback“ where the entire Wave creation process could be played back (in chunks) from scratch.
The live typing, letter-by-letter technology was eventually brought to Google Docs, which is where most people encounter this sensation today. The Wave team actually demoed collaborative document creation in a Wave, complete with in-line comments. Wave’s input system was really the basis for the modern version of Google Docs, and the entire document system was deemed good enough to be ported over.
Wave was created by Lars and Jens Rasmussen, the same pair of brothers who brought the world Google Maps. In the same way that Google Maps‘ live, scrollable map was a revolution for browsers at the time, Wave’s live typing and other app-like features were cutting-edge stuff at the time (though an app called EtherPad, which Google later acquired, cracked live typing first). The I/O 2009 intro to Wave felt like it was from another era. „[Wave] is an unbelievable, powerful demonstration of what is possible in the browser,“ Engineering VP Vic Gundotra told the crowd. „Over the next hour and a half, as you see this product, you. will. forget. that you are looking at the browser. I want you to repeat after me: I am looking at an HTML5 app. I am looking at what’s possible in the browser.“ Hearing this again is wild. Remember when browser apps sucked?
Another „you can do that in a browser?!“ feature of Wave was the ability to upload photos with drag-and-drop, just like in a native app. This was the one ability of Wave that wasn’t purely HTML5 wizardry. It required the installation of Google Gears, Google’s browser API shim, at launch. Google said it was working to make drag and drop from the desktop part of the browser standard, and the feature eventually made it into Chrome in 2010.
While Google Wave was the first implementation of Wave, Google did not try to make itself the center of Wave or to build a walled garden. Wave was open source, and like Google Talk, Google imagined Wave as a federated platform where users on different clients and service providers could still talk to each other. The Wave Federation Protocol happened over—wait for it—XMPP, with the extra Wave bits implemented as an open extension to the XMPP core.
Wave had a heavy branch of features dedicated to APIs and bots. Waves could be embedded in blogger webpages, allowing for live edits and additions to show up on a normal web page. Wave communicated this by adding a „Blogger“ bot to a Wave, letting everyone know the information was public and keeping the embedded Wave in sync (letter by letter, in real time) with the main Wave. Some bots could do things like import tweets into a Wave or play games or do real-time translation.
I can see the confusion people have in calling Wave a messaging app. Email and messaging are both just text, so a real-time email app is just as „instant“ as an instant messaging app. The difference is in the interface, though. Wave was always a big, heavy, inbox-driven app that you were supposed to live in, making it very email-like. Wave never got any mobile apps and only supported a single platform: the browser. That meant there was a mobile version of the site, but especially in 2009, this was an awful experience. Even if you wanted to use Wave as a messaging service, without an app, you wouldn’t be able to make your phone beep about an incoming message. Therefore, it has to be disqualified from being deemed „messaging.“
Nobody knew what Wave was for or how to use it
Google announced the death of Wave on August 4, 2010, just 15 months after the service was announced. Google said flatly, „Wave has not seen the user adoption we would have liked.“ Wave became read-only on January 31, 2012, and all Wave content was deleted in April 2012. As an open source project, Wave was supposed to live on at the Apache Software Foundation, but the project never produced an official release, and it was retired in 2018.
A big contributor to Wave’s death was the lack of a network effect. Wave could only be used to communicate with other users on Wave, so you get the catch-22 of people only wanting to use Wave if people already used Wave. Exacerbating this problem was the fact that Google hamstrung the initial Wave userbase with an invite system, so even interested users couldn’t try out the service immediately. (Admittedly, a load of users firing up the all-live, all-the-time app was probably a scary proposition for Google’s network engineers.) Wave went a whole year before removing the invite system, which, for a collaborative communication app, seriously limited its viability. On May 26, 2010 (Google I/O 2010), Wave’s invite system was dropped, and it was open to the public. But by then, the hype was gone and no one cared. Wave lasted an incredible 70 days as a public service before Google announced it was dead.
Shortly after Wave’s death, a group of Ars staffers got together and rounded up a litany of complaints covering why they didn’t use the service. This was before the browser javascript benchmark wars, and browsers weren’t great at handling the javascript-heavy Wave site, which was described as „slow and wonky.“ The triple-plane layout could get cramped on a 4:3 desktop monitor (though columns were minimizable), and the site was called „ugly“ and „confusing.“ Spotting the newest messages, which could be anywhere in a long Wave, was difficult. Like a wiki, ownership of an individual message on Wave was not really a thing. Anyone could edit, or delete, anyone else’s content in the Wave.
Live, letter-by-letter typing is an interesting communication method, and if you’ve never tried, fire up Google Docs with a friend and give the document text a shot as a communication platform. For good typists, it’s a faster, more fluid form of communication that’s kind of fun. For less confident typers, live typing turns keyboard input into a high-pressure performative act with a live audience, and you can see how it would turn off some people. The lack of any kind of draft mode meant you didn’t have a free second to compose your thoughts into text or think about what you wanted to type—every letter was immediately broadcast onto the Internet, showing the world your typing speed and error rate. Google is a place full of tech-savvy computer nerds, and sometimes a group like that, building a product in a bubble, completely whiffs on the emotional human element of a messaging app or social network. This was one of those times.
Wave policy of „always live update everything, all the time“ can lead to a Wave inbox being pretty overwhelming when it is active and popular. Martin Seibert made the above video for a Techcrunch article showing just how bad it can get. Being live means the inbox just constantly jumps around as new messages load in, making it difficult to even read a thread subject before it disappears. When popular, Wave was a completely unmanageable mess where you’d never hit Inbox zero.
When Wave was still active, there was a ton of talk about federation, bots, and APIs. Users constantly hoped that someone, Google or a third party, would make Wave interoperable with any other service, like Google Talk or email. That approach would solve the problem of Wave only being useful when talking to Wave users. If Wave hooked up to another service, Wave could be useful for the individual user no matter what, and Wave features could be added any time two Wave users were communicating with each other. Google Voice did a great job of this with the phone system by adding extra features to SMS, Voicemails, and phone calls. A solid connection to an established communication network never materialized, though, so Wave never had a solid userbase.
In the peak social media days, everyone was on Facebook because everyone was on Facebook. In this case, nobody used Wave because nobody used Wave. From here on out, the network effect would forever be a huge problem for Google messaging services. Some future projects took note of this and tried to juice the initial network—in some successful and, uh, extremely unsuccessful ways. Speaking of which…
Google Buzz (2010)—The non-consensual social network
Lifetime: February 9, 2010—December 15, 2011 (1 year, 10 months)
Platforms: Desktop Gmail, mobile web apps for Android and iOS.
Where do you even start with Google Buzz, one of Google’s most notorious products? Remember that in 2005, Google Talk found a major shortcut to a big user base when it was integrated into Gmail. So, surely, the same strategy would work for Google’s social network aspirations, right? In early 2010, the Google Buzz social network launched, not as a standalone service but as a Gmail sidebar component just like Google Talk. Oh yeah, it also started automatically following and sharing stuff with your frequent email contacts without really asking users if that was OK. What followed was a whirlwind of controversy, complaints, and lawsuits, and it’s kind of astounding how most of the Google Buzz saga took place over just four days.
Google built a basic social networking app with a scrolling list of posts and replies—it was basically identical to Facebook or Twitter, but in Gmail. Follow a person. Post some text. Add a picture. Press the „like“ button. The basics were wholly unoriginal other than the fact that it was invading your email inbox.
Every single design decision made for Google Buzz can be framed as „fixing the network effect.“ Remember how Wave died because nobody used Wave? That was not going to happen with Google Buzz. Shoving the product into Gmail would quickly get it a big user base of its own. Buzz was also pitched as a „social aggregator“ and could pull in posts from other services, so even if none of your friends were on Buzz, you could still use Buzz and see their content. Buzz would pull in posts from Twitter, photos from Picasa and Flickr, or (brace yourself for sadness) articles you liked on Google Reader.
Buzz’s critical mistake was how the initial setup worked. It was totally automatic—Buzz built your social graph for you by automatically adding frequent contacts from Google Talk and Gmail. You would automatically follow them and they would automatically follow you, all without the input of a human on either end. It also automatically connected Google Reader and Google Picasa data and instantly associated any public content with your Buzz profile. From there, the service shoved all that in front of any „friends“ it detected.
Google’s day-one blog post for Google Buzz is worth a read just to get an idea of what an astoundingly out-of-touch, non-consensual nightmare the Google Buzz rollout was. „Buzz is built right into Gmail, so there’s nothing to set up,“ the blog post reads. „You’re automatically following the people you email and chat with the most.“ Buzz was also going to spam the hell out of your inbox unless you found a way to stop it: „To make sure you don’t miss out on the best part of sharing, Buzz sends responses to your posts straight to your inbox. Unlike static email messages, Buzz messages in your inbox are live conversations where comments appear in real-time.“ Google just decided to turn your email client into a social media network, and it hoped you were OK with that. Nobody was.
Buzz never got a standalone website, and it never got any mobile apps. It did get a mobile website for Android and iOS, via a coveted link on the mobile Google.com search page. Android 2.0 also integrated a Google Buzz home screen widget and Google Maps added a „buzz about this place“ button in location listings. Besides the expected mobile browsing of, uh, buzzes, mobile Buzz was also a Foursquare and Dodgeball clone, letting you tag posts with a location.
Google Buzz’s automatic setup exposed a ton of data about people without really properly informing them or getting their consent. Like most social networks, who your friends are following was public information on Buzz, but since this was created automatically from contacts, Buzz exposed everyone’s frequent email contacts to the world. Your Buzz username was also your email address, so that was automatically exposed to the world, too. If you used the Foursquare-like location sharing, then your location would be broadcasted to any „nearby“ Buzz users—not just your friends.
Buzz used a lot of the same predatory privacy tactics as Facebook, where, sure, there were technically controls for all this stuff somewhere, but they were purposefully deemphasized to trick users into making everything public. Buzz made users opt-out of exposing sensitive information, instead of having them opt-in to sharing. Users who didn’t carefully comb every square inch of the screen for the low-contrast fine print didn’t understand what they were exposing, and they felt betrayed after realizing what was shared with their contacts.
By day two, Google still wasn’t in touch with the reality of what it had done. A new blog post touted how proud Google was of all the (forced) usage Google Buzz was getting. „It’s been just two days since we first launched Google Buzz. Since then, tens of millions of people have checked Buzz out, creating over 9 million posts and comments,“ the post stated. „Plus, we’re seeing over 200 posts per minute from mobile phones around the world.“ If you’re a bean-counting, spreadsheet-obsessed, emotionless robot, this probably sounds like a success. The problem was, no normal human liked this, and most of these posts were complaints. Google’s day-two blog post gave a minor nod to some privacy concerns people had raised, but the damage was already done.
The rest of the world had turned against Buzz by day two, and the consumer revolt was incredible. Buzz was called a „privacy nightmare“ in the press. In one viral post, a woman recounted how Google Buzz’s algorithms decided it was a good idea to automatically reconnect her with her abusive ex-husband and threatened her safety.
By day four, Google finally gave up and posted an apology on its official blog. „We quickly realized that we didn’t get everything quite right,“ the company said. „We’re very sorry for the concern we’ve caused and have been working hard ever since to improve things based on your feedback.“ These „improvements“ involved stripping back Buzz’s automatic setup process and turning „automatic following“ into a „suggested contacts“ list. The company added better blocking controls for unwanted followers and stopped auto-connecting Picasa photos and Reader articles. It also added the option to turn off Google Buzz in the Gmail settings, finally providing an opt-out for Buzz entirely.
As far as much of the public was concerned, the entire life and death of Google Buzz occurred these first four days. Buzz launched, it messed up everyone’s Gmail for a few days, and everyone scrambled to turn it off and clean up the mess Google had made. Buzz was never anything special in terms of the actual product, and the stigma of the initial launch and the out-of-place Gmail integration made most people ignore it or turn it off.
Beyond week one, Buzz’s lasting legacy centers on lawsuits and legal action. The Electronic Privacy Information Center (EPIC), a privacy watchdog and public interest research group, filed an FTC complaint over Buzz’s privacy violations. After an investigation, Google settled with the FTC, committing to maintaining a „comprehensive privacy program“ for 20 years. A class-action lawsuit was filed that eventually saw Google settle for $8.5 million. Google Buzz even earned international condemnation, with government officials from 10 countries sending Google an open letter telling it to drop its „launch now, fix later“ policy.
Buzz feels like something that was generated entirely by an algorithm. Any normally functioning human would understand that there is a difference between email and social media and what those two things are used for. Email is often an obligatory, formal, and official form of communication with people and companies; social media is for fun (theoretically). There are tons of accounts you would communicate with over email that you would never want to see on social media, and vice versa, yet no one at Google realized this during the making of Google Buzz.
Buzz’s death was announced unceremoniously as the second bullet point in one of Google’s infamous „spring cleaning“ posts on October 14, 2011. At this point, absolutely nobody cared, since all of Google’s social attention had been on its new baby, Google+ (that had launched four months earlier). Google announced Buzz would be shut down in „a few weeks“ and that it „learned a lot from products like Buzz, and are putting that learning to work every day in our vision for products like Google+.“ I can’t find any reports of the actual Google Buzz shutdown date, but the Wikipedia entry has a completely unsourced date of December 15. If accurate, that would mean the product lasted one year and one month. Really, though, Google Buzz was four days of terror and then it died.
Slide’s Disco (2011)—An independent app escapes the Googleplex
Lifetime: March 24, 2011 to October 11, 2012 (1 year, 6 months)
Platforms: iOS, Android, the web
Is this one new for you? This one is new for me. Once upon a time, there was a company called „Slide, Inc.“ It was founded in 2004 by PayPal co-founder Max Levchin, and this company was the maintainer of the super-popular Facebook games Superpoke and Superpoke Pets. One day, Google—probably as part of its panic over the rise of Facebook—bought Slide. Slide had an incredible run at Google. Google announced it purchased the company on August 6, 2010, for $182 million, and then Google announced it was killing the company August 26, 2011. During those 387 days of operating under Google, Slide did the obvious thing and made a messaging app.
It was called „Disco.“
To start, it was only for iOS and only worked in the US. I feel like this app is mostly lost to time, due to only being alive for a year and mostly having a low profile during that time. The best report I can find is from Business Insider, which, in a wonderful time capsule, describes the app as „another one of those group texting apps everyone keeps talking about.“ Group messaging was apparently novel enough at the time for this kind of commentary. BI continued: „Disco is late to the game and already a bit behind in the features other group messaging apps have“ and compared it unfavorably to GroupMe, which launched a year earlier.
Group chat is not actually supported by SMS (that’s MMS, and it was not well supported at the time), but Disco did its best to turn single-target SMS into a group chat anyway. You could create a new group with the Disco app, which would generate a new phone number for the group. You and your group chat cohorts would all send their messages to this one Disco number, and Disco forward the messages to everyone else, prepended with their contact name. The Disco app didn’t actually do much. It was used for managing groups, and users could add a group number to your contacts. After that, all the actual texting happened in the iPhone SMS app. I’m going to guess this wasn’t an over-the-top messaging service for political reasons. Like we covered with Google Voice, AT&T and Apple would not have liked any service that „duplicated functionality.“ Disco still counted against your carrier’s SMS billing, though, so everyone was happy.
There wasn’t much more to Disco than this. That Business Insider report actually criticized Disco for a lack of features like „location sharing or group calling.“ Digging through the site’s Archive.org history reveals that eventually there was an Android app, and at one point you could even send messages to Disco from the web at disco.com.
Slide and Disco are both things you can add to Google+’s considerable body count. The initial blog post title, „Google and Slide: building a more social web,“ should tell you all you need to know about what happened to Slide at Google. Google+ was launching in about a year, and like all competing Google projects, Slide needed to be ground up and fed to the new social beast.
The Google+ Era (2011)—Google’s social panic
Looking back, it’s almost hard to recall the deranged fever dream that was the Google+ era. Social media was a serious fad in 2011, and after the failure of Orkut, Jaiku, and Google Buzz, Google didn’t have a social horse to bet on. Facebook had a stated goal of signing up every single human on the planet, and while it seems ridiculous today, Google saw Facebook as an existential threat. The thought was something along the lines of, „What if people ask their social graph instead of doing a Google search?“ as if asking a gaggle of people from high school was somehow equivalent to doing actual research. (Don’t do this. That’s how you get anti-vaxxers.)
Google went into a complete panic over its lack of social platform, and on June 28, 2011, Google+ was born. In addition to a regular Facebook-style social networking site, Google+ was a hyper-aggressive, all-consuming social backbone that would run through most major Google services. If users wouldn’t voluntarily use a Google social service, Google would make all of its services into a social service. The best quote showing how intense this was going to get came from Google executive Steve Grove, who dropped this doozy of a line: „Google+ is kind of like the next version of Google.“
The motivation for Google+ came directly from the top. Earlier in 2011, then-CEO Larry Page tied all employee bonuses to the success of Google+. Very little at Google is done via a top-down directive like this, making Google+ one of Google’s only products that seemed like a unified effort. Google’s typical lack of unity is why you see so many messaging apps. Android’s SMS app is handled by the Android team, and they don’t really need to talk to anyone else. Google Voice was an acquisition and created its own team. Wave was a new project started by the Google Maps founders. Google Buzz was from the Gmail team.
Some companies with strong leadership can move toward a singular goal as a big unit, but with Google, working together was such a foreign concept that management had to bribe every individual employee with this bonus plan. I maintain that this is the only time Google has done something together as a company. The rest of the time, it’s individual teams making autonomous decisions.
The core Google+ site was a pretty basic, Facebook-style social networking app, with posts, comments, and „+1″s instead of likes. The one big innovation was the concept of „Circles,“ Google+’s group-sharing mechanic. Instead of everyone being a „friend“ like on Facebook, Google+ had users build several social circle lists, so you could have lists like „Co-workers,“ „Close friends,“ and „Family“ and choose to share various things with each of them since each post had a checkbox sharing UI. This seems like a direct reaction to the outcry of Google Buzz, which shared everything with everybody. For Google+, Google said, „You want sharing options? Here are all the options you could want!“
Google learned very little from Google Buzz when it came to shoving social services inside established apps, though. Over the next few years, Google+ would be built into nearly every Google product. A top navigation banner across Google’s suite of services included your Google+ profile and a live notification count. Google Search results integrated Google+ content, mixing in private data with public search results and letting users „+1“ sites. For some period of time, you couldn’t make a new Gmail account without also making a Google+ profile. Gmail showed Google+ profiles associated with each email sender. The Google Play Store required a Google+ account to leave a review. YouTube required a Google+ account to leave a comment. Android used Google+ for photo backup and contact retrieval. Google Maps integrated reviews and photos from Google+ directly into business pages, and Google Latitude, Google Maps‘ location-sharing service, was killed in favor of Google+ location sharing.
Google+’s greatest sin was the murder of Google Reader, a beloved RSS reader that some people still mourn to this day. Shortly after the service’s death in 2013, Reader’s ex-product manager revealed the team was borged into the Google+ collective sometime in 2010, which led to Reader’s death.
Google+ wasn’t all bad, though. It launched with „instant uploads“ for photos, leading to what would eventually become Google Photos, one of Google’s best new(ish) products.
Google+ Hangouts video chat—The first Hangouts
Enlarge/ Google+ Hangouts video chat, featuring Google+’s architect, Vic Gundotra.
Google
Besides the social network and borging everything into the Google+ collective, the service’s 2011 launch included a group video chat platform called „Google+ Hangouts.“ Note that this is completely unrelated to the „Google Hangouts“ chat service that would launch in 2013—it was just video chat.
Hangouts video chat had a novel interface that would show thumbnails of users at the bottom of the screen, and it automatically switched the main view to whoever was talking at the time. There was a text chat on the side and a few face-tracking special effects. You could even watch YouTube videos as a group.
While Google+ was not always looked on favorably, Google+ Hangouts was a big hit. Lifehacker called it, „The best free group video chat we’ve seen.“ In 2012, Google added a feature called „Hangouts on air,“ which would broadcast your group conversation on YouTube, basically making it the defacto standard for group conversation podcasts. Broadcasting a group video chat over YouTube was a great collaboration between Google services, so naturally, Google killed the feature in 2019 and never really launched a replacement.
Google+ Hangouts launched with 480p video only, and it needed a browser plugin to work—the same plugin used for Google Talk. In 2013, Hangouts video chat turned on HD 720p video chat when it switched from H.264 to Google’s open source video codec, VP8. In 2014, Google switched over to WebRTC, the „RealTime Communication“ standard for browsers, allowing Google Hangouts to do video chat without a plugin.
Google+ Huddle/Messenger—I guess we should have some kind of DM function
Lifetime: June 28, 2011—August 14, 2013 (2 years, 1 month)
Clients: Android and iOS
Enlarge/ The Google+ Android app and Google Huddle. There wasn’t much to it.
Google+’s very first messaging service was „Google Huddle,“ a name that almost no one remembers. That’s because Google Huddle launched with G+ in June 2011, but this service became „Google+ Messenger“ by September 2011. Apparently, there used to be a startup called Huddle that owned the global trademark, and Google quickly agreed to change the name. Whoops.
Google+ Huddle Messenger was an exclusively mobile group messaging service. Google+ always had a „mobile-first“ design, but for some reason, for Google+ Messenger, „mobile-first“ got turned into „mobile-only.“ This was a constant source of frustration for users. Messenger was just the world’s most basic group texting app, and you could invite anyone in your Google+ circles to join.
The service got a front-page promotion on the Google+ Android and iOS apps, but other than that, it never really went anywhere. You could send text—and only text—to a group… and that was it. It made sense to be able to DM people on Google+, but did it make sense for that app to be the totally siloed Google+ Messenger mobile app? Not really. Messenger always felt like an afterthought, and after two years of zero improvements, the feature was killed on August 14, 2013.
A competitor emerges—iMessage has entered the chat
Lifetime: October 12, 2011-Present
Clients: iOS, macOS, WatchOS
And now, a brief history of Apple Messaging services: iMessage. End of article.
Apple launched iMessage along with iOS 5 in October 2011 and brought iMessage to the Mac with the release of OS X 10.8 Mountain Lion the next year. Apple did not release a second, competing messaging app 18 months after the launch of iMessage. In fact, Apple has never launched a competing messaging app in the nine years this service has been around. The full power of the company is behind iMessage with no other distractions.
iMessage quickly became the template for what users wanted from a Google Messaging system. Apple’s service was the SMS client on iOS, but it also pushed people over to the enhanced iMessage service whenever possible. Therefore you could use iMessage to communicate with everyone, no matter what. As Apple was fond of saying at the time: it just worked. iMessage messages synced to your Mac, and eventually, SMS forwarding arrived in 2014, so I guess you can say that’s when the service fully powered-up.
We’ll later see Google acquiesce to the wishes of carriers and put SMS on a pedestal, but Apple was the polar opposite. Cupertino couldn’t care less about the feelings of AT&T et al. Carriers were apparently blindsided by the announcement of iMessage and Apple’s commandeering of SMS. I think it’s funny that this happened the same year AT&T’s iPhone exclusivity ended and Verizon finally got to launch an iPhone. I like to imagine Apple said something like, „Hey carriers, multiple partners means you are all now considerably less valuable to Apple! We’re going to kill SMS. If you don’t like it, there’s the door.“ The truth, though, is that Apple didn’t even feel the carriers were important enough to communicate with them.
We’re not covering the full history of iMessage, but naturally having the full weight of Apple behind the service makes it a very competitive messaging app. It has group chat, end-to-end encryption (for iMessage messages), voice messages, FaceTime video calls, and a million other features.
The big downside to iMessage is that it only works on Apple products, and there’s no website, which is pretty limiting compared to the usual „works with everything“ client smorgasbord from (good) Google products. Just like BBM, Apple views this as a type of lock-in, though. Apple is a hardware company, and you’re supposed to only buy Apple products. This also means Apple sees iMessage as a solvent business since more lock-in means more hardware sales.
The hardware lock-in limits the install base iMessage can have, though, since not everyone wants or can afford Apple hardware. The result is that while iMessage is great, you won’t see it on a „most popular messaging services“ list.
One more competitor—WhatsApp is now worth $22 billion
Missing out on the WhatsApp sale was a major turning point for Google.
By 2012, WhatsApp had become one of the world’s most popular messaging apps and was announcing explosive metrics like 10x more messages per day than it had seen the year before. The app doesn’t have much of a presence in the US, but it is extremely popular in India, Europe, Africa, and Latin America. In late 2012, rumors started swirling that the then-independent company was taking acquisition bids. The first bit of smoke was from a TechCrunch report in December 2012, saying that Facebook was sniffing around. WhatsApp shot the rumor down publicly, calling it „not factually accurate.“ Next up was an April 2013 report from DigitalTrends saying Google was negotiating a WhatsApp buyout for $1 billion. WhatsApp shot down this report, too.
It’s hard to believe any of WhatsApp’s denials since just a year later, the company really did end up selling—to Facebook—for a deal that ended up being valued at $22 billion. There was apparently a bidding war going on, and, according to a report from Fortune, Google tapped out at $10 billion. Google’s $10 billion bid would have been the company’s second-largest acquisition ever, after Motorola. Instead, Facebook’s valuation of the messaging market was in a completely different league from Google’s, and it turned the deal into one of the biggest tech acquisitions ever.
WhatsApp was a company that was only five years old at the time and had only 50 employees, yet it ran rings around Google’s messaging efforts (which is a truly embarrassing situation). It’s the perfect example of how harmful Google’s lack of focus can be. From 2009 to 2014, WhatsApp built a messaging app worth $22 billion that boasted 450 million users. From 2009 to 2014, Google launched five different messaging apps.
Pre-Facebook acquisition, WhatsApp also answered the question of, „How do you make money with a messaging service?“ WhatsApp made money through the innovative scheme of charging money—it cost $1 to sign up and $1 a year going forward. WhatsApp originally did this to slow user growth to a manageable amount and cover the cost of sending initial SMS sign-up texts. The founders were apparently shocked to see that $1 didn’t hurt people’s appetite for the app, and it just remained a paid app.
If Google had spent the money to buy WhatsApp, today it would probably be a messaging powerhouse. Instead, the messaging rich got richer, and Facebook was able to control the WhatsApp user base along with its already popular Facebook Messenger service. I think most observers would say Facebook understands social networks and messaging more than Google could ever dream of, and it’s interesting that Facebook treats messaging as a pillar of the company. It’s something the company is willing to spend tens of billions of dollars on, while Google is content to let messaging languish as a series of unstable side projects.
We recently got an amazing bit of commentary on this series of events from Apple, which ended up having some of its internal communication aired out in public thanks to the Epic Games case against the company. When the first „Google’s buying WhatsApp!“ rumors started swirling, Apple’s SVP of Internet Software and Services, Eddy Cue, started pitching the idea of a response to what he saw as a formidable Google/WhatsApp combination. Cue asked the other Apple execs, „Do we want to lose one of the most important apps in a mobile environment to Google?“
Hearing a high-ranking Apple exec call messaging „one of the most important apps“ is, again, strikingly different compared to how Google normally runs messaging. At any point in the last 15 years, messaging has almost always been a complete afterthought in the company’s lineup. Cue wanted to respond to Google/WhatsApp by going really hard and bringing iMessage to Android instead of keeping it the Apple-ecosystem exclusive it is today. Other execs were skeptical of the move, and the plan never happened, but it shows again how Google buying WhatsApp could have been a major turning point for the industry.
Cue (and Facebook) were definitely right about the future of WhatsApp. WhatsApp had 450 million monthly active users at the time of the Facebook purchase, and today the app has grown to over 2 billion users. Google has released another five messaging apps in that amount of time and still doesn’t have a stable or successful messaging platform.
Google Docs Editor Chat (2013)—Just like Gmail chat, but not integrated with anything
Lifetime: June 6, 2006 (Sheets)/April 25, 2013 (Docs and Slides)-Present
Clients: Desktop web only
Let’s take a minor detour from the major messaging apps to talk about Google Docs. Google Docs/Sheets/Slides is a great online tool for collaborating on a document. And often when you’re collectively writing or editing something, you want to have a discussion about it. For that, the Google Docs Editors have a very handy integrated chat service.
Google Docs and Slides got a siloed chat feature in 2013, but if you want to get really technical, Sheets first had chat at launch, all the way back in June 2006, when it was „Google Spreadsheets Labs.“ The other Google office suite app would be more reliant on an in-line comment system for communication at first (does that count as a messaging service?), though, and it wouldn’t get a similar chat feature until seven years later.
This 2013 version of the Google Docs editor chat looked and worked just like Google Talk in Gmail. It actually was Google Talk under the hood, but somehow this wasn’t integrated with Google Talk. Google Docs throws everyone looking at a document into a single group chat, and combined with the fact that some documents could be public, maybe that didn’t jibe with Google Talk’s contact security model.
If Google could have made everything work, Gmail’s use of a real chat service still seems like a more convenient solution. While Google Talk works everywhere and will pop up on your phone, Google Docs Chat is awkwardly only available through the desktop web app, which means you’ll only get a message if you are sitting in front of a computer with that specific document open. I am always first invited to look at a Google Doc through a real messaging service, like Hangouts, and then at some point we have to awkwardly stop talking on Hangouts and start talking to Google Docs just to get the convenience of having everything in a single window. If I leave early and someone asks a late question, that question doesn’t arrive if it’s asked through Google Docs. The weird thing about Docs and Gmail is that the interfaces are nearly identical—pop-up chat boxes that you can type in—but Gmail’s is so much more reliable and convenient thanks to being plugged into a real chat service.
Like we discussed in the Google Talk section, thanks to sharing some back-end functionality with Google Talk, the 2017 shutdown of Google Talk disrupted Docs chat for a bit while it switched to Hangouts. What’s crazy about that timeline is that Google Docs and Slides implemented Chat in 2013, one month before Google Hangouts launched. This capped off months of rumors about Google’s new chat service, so surely the Google Docs team knew Talk was on the way out. Yet, it launched the feature based on Talk technology anyway. Skate to where the puck is going, people!
Google Hangouts (2013)—Google’s greatest messaging service
Lifetime: May 15, 2013 to Present
Platforms: Android, iOS, the web, web Gmail, Windows, Mac, Linux, Chrome OS, Android Wear, Google Glass
Circa 2013, Google was running into a problem—way too many messaging apps. If you were a Google user and wanted to message someone, you could IM them on Google Talk, send an SMS from Android’s texting app, send them an SMS through Google Voice, or fire up Google+ Messenger. Google’s plan to solve the problem of four messaging apps was… to develop a fifth messaging app.
This messaging app would eventually be a great unifier, though. Rumors of Google’s super messaging platform started as early as 2012, with one Google product manager admitting to the media Google was doing „an incredibly poor job“ meeting the needs of messaging users (you don’t say?). By 2013, rumors of an IM project codenamed „Babel“ were regularly popping up, promising a unified Google messaging solution.
At Google I/O 2013, Google announced that Hangouts would turn from a video app into a full-blown messaging service. During the presentation, Google pitched an idea that some messaging services still can’t offer: a client that can do text, photos, and video chat, across all devices, on any OS. On day one, Hangouts was everywhere. There were clients on Android, iOS, and on any desktop via the Gmail website or a standalone Chrome extension (which was indistinguishable from a native app). That last bit worked on Windows, Mac, Linux, and Chrome OS.
Hangouts‘ default list view showed conversations instead of people, mixing in one-to-one chats with group chats. Any photos shared to a room would be saved in a Google+ Photos album, and text history is saved forever (if you want) in Gmail and synced across devices. Hangouts‘ G+ integration meant you could add entire circles to your group chats or add people through a simple checkbox UI. Google Talk pre-dated the invention of Unicode-standard emojis, so Hangouts was Google’s first messaging service to ship with a comprehensive set of the little glyphs. There were read receipts and animated typing indicators, and since this was based on Google Hangouts the video chat app, a single button push could drop everyone into a group video call.
Google Hangouts replaced Google Talk, and the existing user base got an in-place upgrade, a move that should be a benchmark for how serious Google is about any given messaging app. In the future, a thousand Google Messaging apps will rise and fall after the launch of Hangouts, but only one, Google Chat, will be deemed worthy enough to inherit this user base. The desktop version of Gmail swapped out the Google Talk sidebar for a Hangouts sidebar, which was functionally very similar. On Android, Hangouts shipped as an upgrade to Google Talk, and to this day it has the same package name as Google Talk: com.google.android.talk.
The in-place upgrade strategy led to a huge overnight explosion of Google Hangouts users. Android would pass 1 billion activations in a few months, and Google Talk was a preinstalled app since the beginning. All of those still-active Android users would become Google Hangouts users once they checked for app updates. A year earlier, Google announced Gmail was the world’s biggest email service, with 425 million active users. Now all of these people were on Hangouts.
Hangouts also started the death of XMPP messaging for Google’s biggest messaging service. All the federation work that Google started with Google Talk wasn’t making the jump to Hangouts. XMPP clients like Adium and Pidgin could still connect to Hangouts, but they would have to do it with Google credentials. Non-Google users wouldn’t be able to connect to the Hangouts service through a federated server the way they could with Google Talk. Even with Google credentials, XMPP clients on Hangouts were second-class citizens and didn’t get access to many features.
Enlarge/ Hangouts didn’t unify anything at launch. Before Hangouts there were only four messaging apps; after Hangouts there were four messaging apps. That would change, though.
On day one, Hangouts was a bit of a disappointment. Those hoping for a unifying Google messaging service, like the rumors promised, didn’t get one. We started with four services—Google Talk, Android SMS, Google+ Messenger, and Google Voice. And in the immediate aftermath of the Hangouts launch, there were still four services—Hangouts, Android SMS, Google+ Messenger, and Google Voice. Nothing was actually unified. There were also a few missing features compared to Google Talk, like the lack of audio calls and presence indicators. This is the minimum viable product launch strategy in action, and the disappointment is standard. A lot of Google services never recover from the initial negative reaction, but Hangouts did.
The key to overcoming MVP disappointment is to rapidly ship updates, and Hangouts did that. Three months after launch, in August 2013, Google+ Messenger was killed, and the company was down to three messaging apps. October 2013 brought the long-anticipated Hangouts SMS integration on Android. Users could register Hangouts as the default SMS app, finally giving Android users an equivalent to Apple’s iMessage on iOS. That month also brought the release of Android 4.4 KitKat, where there was no default „SMS“ app for Android anymore, there was only Hangouts (so if counting, we’re down to two apps). Google finally delivered on the full promise of Hangouts when, by late 2014 around a year and a half after launch, Hangouts finally added Google Voice support. These features all arrived slower than any Hangouts user would like, but finally, there was one Google messaging app to rule them all.
At this point in 2015, Google Hangouts was at the height of its powers. To date, it’s still the greatest messaging service Google has ever produced. It worked on every platform. It pulled in SMS, Google Voice, and regular Hangouts messages. They were all stored in a seamless, merged history of messages from each contact, and you could switch message delivery systems via an easy drop-down menu. It had most of the features you could want, like video calls and location sharing. And accordingly, by June 2015, the app hit a billion downloads, just on Android. A dedicated Hangouts website, hangouts.google.com, would launch in August.
The death of Hangouts, unified Google messaging, and hope
Hangouts‘ reign as Google’s unified messaging service held together for about one year, basically the entirety of 2015. By the end of December, Google couldn’t help itself and there was already talk of a new Google messaging service that was gearing up to launch, but this time with chatbots (this would eventually be Google Allo). Also in 2015, Hangouts development was already going slower than people would like, and the neglect was starting to be visible.
Google actually caved on an iMessage-style SMS takeover a year earlier, in 2014. The company pushed forward the bold direction of running all SMS messages through Hangouts in the 2013 release of Android 4.4 KitKat, which didn’t include any other SMS app. Carriers complained soon after, and Google immediately sided with carriers over users, shipping what the company described as a „carrier-centric“ SMS app, Google Messenger, in Android 5.0 Lollipop. Around 2014, the iOS/Android duopoly was not set in stone yet, and with Google still fighting Windows Phone 8, it didn’t want to upset carriers and give Microsoft an opening for success. Hangouts‘ SMS support would still hang out for a few more years, but Google proved it didn’t have the stomach to do anything the carriers didn’t enthusiastically approve of.
Hangouts collapsed about as quickly as it was built. Despite the superior functionality on Hangouts, Google started pushing users to switch SMS usage from Hangouts to the „carrier-centric“ Google Messenger SMS app in early 2016. At Google I/O 2016 in May, Google Allo was announced, a new messaging service that would ship with lots of bells and whistles that could have been helpful to Hangouts. By October 2016, Hangouts was no longer a default Android app, having lost its spot to Allo.
Hangouts started being stripped of features, but it was never enough to kill the app. In May 2017, Hangouts was stripped of its SMS functionality. In December 2018, Google announced a formal plan to kill Hangouts and transition users (many of whom have been around since Gtalk) over to yet another Google Messaging app, Google Chat, which was first built as a competition to Slack for G Suite. The Wear OS Hangouts app died in 2019, and location sharing and audio calls were ripped out of Hangouts in 2020.
Yet actually killing Hangouts has proven incredibly difficult for Google—mostly due to how many clients there are and how widespread it is. Despite the late 2018 shutdown announcement, Google hasn’t made a ton of progress in 2019 and 2020 toward replacing Hangouts. The latest timeline said that optional upgrades for consumers to Google Chat will start in 2021, and Google Voice support will die in 2022. There’s still no actual shutdown date.
Google Hangouts was the gold standard of Google Messaging apps, and the app has cast a long, dark shadow over all of Google’s up-and-coming messaging services. From here on out, any complaints about newer Google Messaging services almost always revolved around the quote, „Hangouts did this better.“ If Google could have just taken care of Hangouts over the years and thrown the full weight of the company behind this single messaging service, today it might have an iMessage-fighting, WhatsApp-rivaling message app, and I probably wouldn’t be writing this article. Google just could never throw the full weight of the company behind a single messaging app, and soon Google would move on to a new shiny bauble, leaving Hangouts to rot.
Google Spaces (2016)—A messaging app for Google I/O 2016 attendees
Lifetime: May 16, 2016—March 3, 2017 (8 months)
Platforms: Android, iOS, the Web
Google was really in the messaging mood at Google I/O 2016, where the company launched not one, but two messaging apps. The first was a completely baffling app called „Google Spaces,“ a group messaging service for „small group sharing.“
Spaces were basically chatrooms that you could share stuff to. You could create a room around a certain topic, invite people to it via a URL, and then people could post messages, photos, and links into the room. That was pretty much it. There were apps for the web, Android, and iOS, and the mobile apps would ship you notifications whenever someone posted a new message. Each space room looked identical to a messaging app, while an „activity stream“ would show all the new stuff from all your spaces (that looked like a social network stream).
Spaces‘ only unique feature was the odd choice to have Google Search „built-in.“ Instead of just copying and pasting a link to something from an outside app, Spaces would let you fire up a built-in web browser and navigate around the web. The Spaces web view would pin an easy „share to space“ button at the bottom of the screen, but was copying and pasting a link really that difficult?
Spaces had no real use case and no real appeal. Some takes compared Spaces to Slack, just with extremely limited functionality. Others express bewilderment that spaces looked and worked pretty much exactly like a Google+ Community, but detached from Google+ and without any cross-functionality. A big problem was that there wasn’t any moderation functionality at all, so if anyone got your Spaces URL and decided to be a jerk, there was nothing anyone could do about it.
Looking back, Spaces seemed like it was an app built specifically for Google I/O 2016. For those three days, every Google developer talk had a „Space“ where you could download the slides and see other related media. Google even pitched Spaces this way in the introductory blog post:
We’ll also be experimenting with Spaces this week at Google I/O. We’ve created a space for each session so that developers can connect with each other and Googlers around topics at I/O, and we’ve got a few surprises too. If you’re joining us in person at I/O, make sure you install Spaces on Android or iOS before you arrive!
Once everyone flew back home from Google I/O, the app was basically dead. As far as I can tell, Spaces never got an update or a new feature. Spaces worked for a whole eight months before posting was shut off on March 3, 2017, and Google deleted all the data the next month.
The life and death of Spaces raises an important question: Does anyone at Google do quality control for these things? Is there any gatekeeper at all? Someone that says, „No, this isn’t good enough to put the ‚Google‘ name on?“ Does anyone demand that launching a product comes with some kind of support commitment? It seems like the answer to all these things is „no,“ and that’s really a tough way to run a brand. Some Google divisions are out there building long-term, well-supported products The Right Way™, like Android and Chrome, and they get lumped in with fire-and-forget products like Space and Allo that destroy trust in the Google brand.
As consumers, it’s impossible to tell from the outside if a new product actually has a real commitment at Google, or if it’s just being shoved out the door to fluff up someone’s résumé. There needs to be some kind of standard for a product launch, and Space suggests there isn’t.
Google Allo (2016)—Google’s dead-on-arrival WhatsApp clone
Lifetime: September 21, 2016—March 14, 2019 (2 years, 5 months)
Platforms: Android, iOS, Phone-based web interface
Google lost out on purchasing WhatsApp in 2014. So just over two years later, at Google I/O 2016, Google announced a pair of apps that seemed aimed directly at the one that got away. „Google Allo“ was a straight-up clone of WhatsApp with some minimal Google magic, and Google Duo was a dead-simple „companion“ video app. Allo would go on to be one of the biggest flops in Google Messaging History. After a high-profile announcement on the Google I/O stage, the app launched a few months later in September to terrible reviews. It plummeted off the download charts in just a few months. The problem with cloning WhatsApp is that WhatsApp had a billion users at this point in 2016, and Allo had zero users. To say nothing of the many show-stopping feature deficiencies of Allo, why would anyone that likes WhatsApp-style apps use Google’s WhatsApp clone when actual WhatsApp existed? No one had an answer for that, and Allo was a disaster.
Allo took Google’s strategy of the Minimum Viable Product and turned in less functionality than ever. At launch, Allo only worked on phones. There wasn’t a web app or Chrome extension that would allow desktops and laptops to receive messages, and the support for iOS and Android tablets ranged from terrible to impossible-to-use. The limited device support wasn’t just from a lack of clients. Allo only supported signing in to one device at a time, anyway—if you signed in on device #2, the Allo on device #1 would shut off and stop receiving messages.
All of Allo’s strange client problems were due to it being a WhatsApp clone and to it being targeted at India. Allo didn’t use your Google account at all, and instead relied on your carrier’s phone number for identification. Users would have to make a new Allo account that was powered by the carrier’s SMS system, and it felt totally crazy to have to tell Google—a company that is supposed to know everything about you—basic info like your name and profile picture. Being locked to a SIM card was why Allo only worked on one device. That’s just the way SIM cards work. Browsers also don’t have a SIM card, so you couldn’t log in on a browser.
This account system made sense for WhatsApp, which had no existing account infrastructure or userbase, and a target audience of people that were relatively new to the Internet and don’t have a ton of devices. For Google though, people interested in a new Google product usually already have a Google account. The Google ecosystem is supposed to be a core part of the sales pitch. Allo just threw all of that out the window.
We can get into some of the bells and whistles later, but they really didn’t matter. The reaction to Allo was mostly just disbelief at how astoundingly incomplete it was when it came to the basics. Locking your messages into a single device meant the app wasn’t any more convenient than SMS. Allo didn’t seem like it wasn’t built for a modern, multi-device world. Compared to Hangouts, which worked on everything and supported SMS and Google Voice, Allo seemed like a joke and basically died on arrival.
The hype Allo generated as a Google product launch was enough to generate five million downloads in its first five days. After that, Allo completely stalled and would take three months to hit 10 million downloads. Keep in mind these are just downloads—people trying the app—and don’t represent people who stuck around and became active users, which, for every app, will be far lower than the total downloads. By January, four months after launch, the app fell off the Play Store’s top 500 app list and was completely dead.
Allo shows the ultimate failure of Google’s Minimum Viable Product strategy. MVP works when you have almost no competition, or if you are taking a radically different approach to what’s on the market, but it completely falls on its face when you are just straight-up cloning an established competitor. There’s no reason to use a half-baked WhatsApp clone when regular WhatsApp exists. The whole point of a minimum viable product is to launch, get feedback, and quickly iterate on that feedback, but Allo never did that. The app didn’t deliver any substantial new features quickly.
Google only got around to fixing one of Allo’s day-one, show-stopping problems—the lack of a desktop app—one year after launch, at which point Allo was already dead, buried, and the corpse had rotted away. Even then, the desktop mode wasn’t very good. Authentication was still based on your SIM card, so the desktop app needed you to log in with your phone and then forward that authentication to a browser via a QR code. From there, your phone would forward Allo messages to the web app. The phone was still the key, though. If your phone was missing, or the battery was dead, you couldn’t use Allo on the web.
What Google didn’t seem to understand at the time is that, like we covered in the earlier WhatsApp section, WhatsApp-style apps are not appealing to the whole world. Google tried to push its poor WhatsApp clone in the US, but even regular WhatsApp is not popular in the US. Apps that rely on SMS authentication don’t work well in a multi-device world, and that’s OK. Facebook understands this, so it has the Internet-based Facebook Messenger, which works great on multiple devices, has a website that doesn’t require your phone, and is generally available everywhere. Facebook also has the SMS-based WhatsApp, which is limited in device compatibility but is super easy to join. These two apps in Facebook’s arsenal have divvied up the world; neither app on its own would be popular everywhere.
When even the world’s most successful messaging company can’t make one app to rule the entire world, I don’t understand how one of the worst messaging companies thinks they can crack it.
Allo’s legacy: The Google Assistant
Allo was DOA thanks to the SMS limitations and competition from WhatsApp, but it did have some interesting ideas. There were stickers and adjustable text sizes, and Google Inbox’s machine-generated Smart Replies made the jump to a messaging app. An „incognito mode“ would turn on end-to-end encryption, but it wasn’t on by default.
Allo’s longest-lasting legacy is actually the Google Assistant, which debuted on the service. Allo’s text-only (it never spoke) chatbot version of the Google Assistant in September 2016 pre-dated the launch of the feature on the Google Pixel (October 2016) and the Google Home (November 2016). The Assistant in Allo was just like the Assistant in Google’s voice products today: You could ask it general knowledge questions, the weather, sports scores, or a million other things. Unlike the current voice interfaces, in the Allo version, the Assistant never talked out loud, it just sent you text messages and showed up as a contact in your chat list.
The theoretically fun part about the Google Assistant in Allo was that you could drag it into a group chat, ask it something like „what time is this movie playing?“ and negotiate a time with your group chat. This was all in theory because nobody ever actually used Allo. I really would not mind if the Google Assistant chatbot re-emerged in the next Google IM client.
As an individual chat contact, there wasn’t really a great reason to have a running history with the Google Assistant the way you would with a person, but the individual responses were good and useful. Later Google Assistant interfaces would cut off this running history and start with a fresh answer sheet every time, but the interfaces still look a lot like a messaging app.
Most people could tell Allo was instantly doomed from the terrible download numbers, but Google officially kicked off the beginning of the end for Allo in April 2018, about a year and a half after launch, when it announced it was „pausing“ Allo development. Allo was shut down a year later, in March 2019
Google Allo was just a slow-motion car crash that never sounded like it had a viable product pitch compared to Hangouts. We criticized Allo before it came out as „not making much sense,“ we were thoroughly disappointed when it launched, and we made fun of it when it died. It never stood a chance
Google Duo (2016)—A video companion app for… WhatsApp?
Lifetime: August 16, 2016—Present
Platforms: Android, iOS, Phone-based web interface
Enlarge/ Google Duo is a video chat app that still exists.
Google
Google Duo technically launched one month before Allo, but it’s much easier to understand as a footnote to the Google Allo story. There’s almost nothing to say about Duo because it was as basic of a video app as you can get: a simple contact list, a full-screen video feed interface, and not much else. Since, like Allo, it was targeted at India, Google put real effort into making Duo run on as little bandwidth as possible, and Google’s video and networking experts built something with a real market advantage.
This might be giving Google too much benefit of the doubt, but maybe the reason Allo was so bad was because Google didn’t actually need Allo to survive. Google pitched Duo and Allo as „companion apps,“ which was a ridiculous idea at the time. Messaging apps have built-in video functionality. Why would you split video and chat into two different apps? The most likely explanation was WhatsApp.
WhatsApp video chat wouldn’t launch until November 2016, so as a separate app, Duo could not only be a video companion app to Allo, it could also be a video companion app to WhatsApp. Lots of WhatsApp users ended up using Duo with WhatsApp. Not having Allo would mean Google would be sending the strange message of „go use Whatsapp,“ a rival Facebook service, and Duo couldn’t be paired with Hangouts since that already had video chat. Maybe Allo was a marketing crutch in retrospect?
While Allo is dead, Duo lives on. Today, as a default Android app, it has over a billion Play Store downloads. For years, the app required an SMS-powered account, like Google Allo, but sometime at the beginning of 2020, Google started letting people use Duo with only a Google account. All throughout 2020, Duo did its best to keep up with the world’s voracious video demand during the pandemic, increasing from 8 to 12 to 32 video chat members. Duo still couldn’t keep up with Zoom though, which allowed people to video chat without any account at all.
Duo’s survival makes it one of the strangest Google apps out there. It’s part of the Google ecosystem, but it really doesn’t feel like it. And Google Meet is clearly the future of Google’s corporate and consumer video chat roadmap. An August 2020 report from 9to5Google (which also broke the Google Hangouts/Google Chat merger news) says that someday, Google Duo will „merge“ with Google Meet and be shut down. Buckle up, Duo users.
Google (Hangouts) Meet (2017)—Not Zoom
Lifetime: March 9, 2017—Present
Platforms: Android, iOS, Web, custom hardware, Google Glass
In March 2017, six months after the launch of Google Allo and Google Duo, Google announced another messaging and video app pair. This time, the releases were aimed at enterprise organizations. „Hangouts Chat“ and „Hangouts Meet“ were branding nightmares because they marked the third and fourth time Google has recycled the „Hangouts“ brand into a completely unrelated product. Don’t confuse Hangouts Chat and Hangouts Meet with either Google+ Hangouts (the video group chat service that launched with Google+ in 2011) or Google Hangouts (Google’s unified messaging service from 2013). Hangouts Chat and Hangouts Meet are totally new products, unrelated to anything else. It only took three years after Hangouts Chat and Meet were announced for Google to realize having four separate products called „Hangouts“ was too many. Eventually, the company did rename Hangouts Chat to „Google Chat“ and Hangouts Meet to „Google Meet.“
Hangouts Chat wouldn’t launch until about a year after that March 2017 announcement, but Google Hangouts Meet was launched that month. As usual, there is not a ton to say about a Google video chat app. You can join a room. The UI looks like a bunch of camera feeds. There are a few different layouts, like a Brady Bunch-style grid of squares or a thumbnail view.
Hangouts—and I mean old Hangouts, the 2011 consumer video chat version that was absorbed by the 2013 messaging app—only supported 10 video chatters at once. Hangouts Meet supported 30 people at launch, and today, the paid version of Google Meet caps out a questionably-productive 250 people.
Under the hood, both (old) Hangouts and Google Meet do video chat over WebRTC, so there’s not a huge difference in the actual video calls. The starting UIs were a lot different, though. Google Hangouts worked like a phone call and would ring any online devices. Google Meet is more of a destination; you link to a conference room that you share over some other form of communication, and everyone has to click.
The biggest legacy of Google Meet will probably be that it’s not Zoom, a video conferencing app that absolutely exploded during the COVID-19 pandemic and quickly became a household name. As the pandemic raged across the globe, people were locked down at home and needed a way to communicate for work, school, and fun. Suddenly, everyone in the modern world entered the video chat market, and the world needed to pick a service.
Nine years after the launch of Google+ Hangouts group video chat in 2011, would you believe that Google still wasn’t ready for the COVID video chat era? Google was busy re-re-re-re-launching its video chat solution, so it was caught totally flat-footed when COVID hit. Google Meet just barely got off the ground. Meet was locked behind the GSuite paywall until the very end of April, which was about two months into the work-from-home, remote schooling trend in many areas. Meet was also in the middle of a rebrand from „Google Hangouts Meet“ to „Google Meet,“ which was also happening in April 2020, when Zoom was already hockey-sticking up the daily usage charts. That’s nine years into the group video chat market, and when the golden ticket hit, Google had no product ready and no brand recognition. Instead, Google was just starting to launch, or really re-launch, a product.
Enlarge/ Zoom’s revenue. This is what being ready looks like. (Note that the start of the pandemic, March 2020, was Zoom’s FY 2021 Q1)
Being paywalled meant Google Meet wasn’t viable for the hordes of non-technical users that suddenly needed to roll-their-own work-from-home setup. Any kind of payment, account, or software requirements would need to be repeated for all ~30 people in a meeting, and if you actually wanted to hold a meeting instead of spending all day getting people set up, that meant the meeting software setup needed to be as simple as possible. Zoom was ready. At the start of the pandemic, Zoom had a free tier that worked for most people. Also unlike Google, everyone in a Zoom meeting didn’t need a Zoom account—only the meeting owner needed an account. Everyone else just needed to have the app installed and click a link.
Zoom’s ease-of-setup turned the company into a rocketship that we might never see again in the tech space. By September 2020, the company was posting insane headlines like (not a typo) a 4000% increase in profits during the pandemic and a 2900% increase in users. Zoom became a household name, and today the service is so popular that „Zoom“ is now a verb meaning „to video call someone.“ I’ve definitely heard of people Zooming someone on Skype or Google Meet.
By April 2020, The New York Times was already writing about how Zoom had blown past its established rivals, and the report featured this absolutely brutal anecdote from a Google meeting:
Late last month, Philipp Schindler, Google’s chief business officer, held a videoconference with thousands of the search giant’s employees using Google Meet, three people who attended the call said. During the session, one employee asked why Zoom was reaping the biggest benefits even though Google had long offered Meet.
Mr. Schindler tried placating the engineer’s concerns, the people said. Then his young son stumbled into view of the camera and asked if his father was talking to his co-workers on Zoom. Mr. Schindler tried correcting him, but the boy went on to say how much he and his friends loved using Zoom.
Google’s last user numbers for Meet were announced in April 2020, and the company said its service had 100 million daily meeting participants. It’s definitely not a failure, but that pales in comparison to Zoom’s 300 million daily meeting participants. This weird „daily meeting participants“ metric that Zoom and Google settled on can also count a single user multiple times if they participate in multiple meetings, so it’s inflating both of the services numbers. Microsoft Teams, Microsoft’s Slack and Zoom competitor, has 145 million daily active users (individual people), so it’s safe to say Google is in third place, at least.
To try and catch up, Google is following the old Google+ playbook of „shove it into everything“ and hope users will accept the service. The Gmail app now has a „Google Meet“ (and „Google Chat“) tab at the bottom for some inexplicable reason—it’s basically an ad banner that you can thankfully turn off. The desktop Gmail site also has a Meet button in the sidebar and in the Google Chat widget.
At IO 2021, Google announced plans to stick Google Meet into Google Docs via a pop-up sidebar, like the way text chat works. Google Meet is a default app on Android and Chrome OS devices now and it (along with Zoom) got support on the Google Nest smart displays. In October 2020, Google even launched a Google Meet client for Google Glass Enterprise Edition. (Yes, despite the 2013-ish release and flop of the consumer edition, Google Glass still exists as a business device in 2021.)
Of course, Google Meet is also fully integrated into Google Chat, the companion chat service, but it was even back-ported into Google Hangouts, the 2013 chat service Google Chat is supposed to eventually, someday, maybe start replacing. Both have prominent „Start a meeting“ buttons in the UI these days. Patching Google Meet, an enterprise video meeting solution, into Hangouts, a consumer chat service, is awfully strange. Generating a meeting link for friends and family to join, instead of the old Google Hangouts method of answering a ringing video call, is a lot more awkward in practice.
Google even has companies make „Google Meet Hardware“ now. There is a whole selection of enterprise-grade (that means „obscenely expensive“) display, microphone, and camera packages for wiring up a boardroom with video conference capabilities. On the low-end, we’ve got the Asus Google Meet Starter Kit, which is $1750 and includes a 4K, wide-angle camera to capture the whole room, a combination speaker and microphone box that goes in the middle of the conference table, and (what is seemingly the core of all of these systems) the „Google Meet Compute System.“ That’s essentially an Intel Core i7-powered Chromebox that gets you connected to Google Meet. On the high-end, there’s the „Logitech Tap – Google Meet Large Room Bundle,“ which is $5100 and includes a 10.1-inch touchscreen, a camera, two speakers, a compute box, and two microphone pods for large table coverage. The camera is a swanky 4K pan/tilt/zoom unit that automatically targets and zooms in on the person it detects is talking.
There are also a few all-in-one displays, like the $1450 Acer Chromebase for Google Meet. And Meet is supported on the $5,000 Google Jamboard, a digital whiteboard for Google Docs.
I will give it to Google that (for now at least) Google Meet is well-maintained and constantly gets meaningful updates. There’s screen sharing, broadcasted meetings that support 100,000 GSuite viewers, the ability to record a meeting to Google Drive, and real-time captions. The app works well and is easy to use, it was just late. The status quo had been established, so it will be hard to get people to switch from Zoom.
YouTube Messages (2017)—Yes, this was really a thing
Lifetime: August 7, 2017—September 18, 2019 (2 years, 1 month)
Clients: Android. iOS, the Web
Google’s inability to throw its weight behind a single messaging solution has a ripple effect across the company’s whole ecosystem. Looking back at this point in 2017, we start to see a series of decisions from popular Google apps that all seem to follow the same rationale. They realize messaging is important and look like they would like to plug into a single competitive Google messaging app. But, lacking a stable messaging platform from the rest of Google or a top-down directive to be compatible with whatever the latest client is, these service teams end up building their own bespoke messaging service. These usually aren’t standalone apps but are instead messaging features that are glommed onto random Google apps. They are very awkward since they are never compatible with anything else, and it’s up to the users to manage a new, siloed list of contacts and message history. This is basically „The Google Docs Strategy.“
The first Google app to strike out on its own in the quest for a viable messaging solution was YouTube, which, in 2017, launched a feature called—what else—YouTube Messages! I see a lot of people who try to „invent“ this product as a joke, but it was a real thing that really existed for about two years, starting in 2017. The thought process here was pretty clear: YouTube probably gets a lot of referrals from „Hey did you see this?“ messages between friends, so why not let people do that directly from the site?
On the mobile app, YouTube’s messaging feature lived under a new „Shared“ tab, which was given a premium slot in the bottom bar, next to „Home,“ „Trending,“ „Subscriptions,“ and „Library.“ The Shared tab was exactly a messaging app, showing a list of conversations you and your friends were having around videos, all inside the YouTube app. On desktop, a „Messages“ button lived next to the bell and app buttons and would bring up a pop-up chat window, just like Google Docs and Gmail.
The YouTube Messages input box came with a little „+ video“ button, so you could easily drop videos into your conversation. It looks like you could react to each message with a heart button (not the typical „Like“ button?), too. Contacts for YouTube Messaging could be added through your phone’s contact app or by just sending someone an „invitation link“ through email or some other chat app.
When YouTube announced the messaging feature would be shut down after just two years of operation, it did not give a reason. One theory floated by TechCrunch is that YouTube messenger was inundated with children, who were using the messaging service to skirt parental controls that had been put in place blocking other messaging apps. YouTube is frequently used as a babysitter, so it’s unblocked for kids, and the surprise addition of a messaging app gets to slip through the filter. Backing up this theory are the 1,400+ angry comments on the original shutdown announcement, full of all-caps messages, emojis, and various messages about how YouTube Messaging is „the only way for some people to talk to their friends.“ In 2019, YouTube was in the midst of a big controversy over pedophilia, and YouTube started doing things like shutting down comments on videos featuring minors. Someone at YouTube might have noticed the Messaging feature demographics and decided to give that the axe, too.
Google (Hangouts) Chat (2018)—Part 1: Cloning Slack is actually a good idea
Lifetime: February 28, 2018—Present
Platforms: Android, iOS, Web
Hangouts Chat was announced alongside Hangouts Meet in 2017, but it didn’t leave a very limited early access program until February 28, 2018, when it became available exclusively to organizations paying for G Suite (G Suite is now called Google Workspace). Hangouts Chat has had one of the most turbulent rides of Google’s products in its short four years on this Earth. In that time, it has undergone both a big rebranding and what seems like a major pivot in its target audience. Coupled with initial restrictive access requirements, it has been one of Google’s hardest apps to nail down.
Hangouts Chat was announced as an „enterprise-focused communication tool,“ AKA a competitor to Slack. There aren’t a lot of hands-on impressions from the early days of the app, since it was 1) invite-only, 2) locked behind the G Suite paywall, and 3) would need a corporation to subject its entire staff to an „early access“ app. Nobody wanted to try this. Your best bet for an early look is this 9to5Google hands-on article from December 2018, a full nine months after the general G Suite launch. It’s so plain and barren.
The day-one features were support for rooms, DMs, treated messages, bots, and @mentions of usernames. The way Hangouts Chat treats threads is pretty different. Slack is presented as a normal chat room, and then you can reply to any individual message to start a thread. Hangouts Chat makes every message threaded, resulting in a kind of forum-style layout where every message must either be a reply or a new, top-level comment. There’s not even a stationary text input box. There are „reply“ input boxes at the bottom of every thread and a „new thread“ button at the bottom of all that.
Just like Slack, Hangouts Chat supports several chatbots, letting you stream outside info into your chat room for things like Asana, Trello, Google Drive, and more. Hangouts Chat works on iOS, Android, and the web, and while there used to be Electron apps for Windows and Mac (just like Slack), today, desktop is handled by a Progressive Web App (PWA). Both Electron and PWAs present web apps as desktop apps, but Electron packs its own Chromium-based browser, while PWAs use the Chromium browser already on your computer.
I don’t think the execution is there yet, even four years after it was first announced, but the basic idea of a Google version of Slack still sounds fantastic. It’s not often that making an exact copy of a competitor results in a successful product, but here, I think a pixel-for-pixel copy of Slack would do well. Many organizations (Ars Technica included!) pay for both G Suite and Slack, and if a fully featured „Google Slack“ was included in the G Suite price, I think a lot of organizations would switch just to cut down from two bills to one. It has been four years now, though, and Google (Hangouts) Chat still feels like an early access app—not a viable Slack replacement.
If you’re wondering what’s missing from Google Chat compared to Slack, Slack has an entire right-side panel you can set up with critical information, like a running list of your @mentions, a list of files in the chat, or pinned messages. Channels in Slack have topics, which are great for important notifications or getting everyone on a channel on the same page. There are keyword notifications that will ping you any time someone in chat mentions a certain topic, which is great for summoning the Android Defence Force (OK, that’s really just me) in the Ars Technica Slack. If you want to see everything, bird’s-eye views like „All unreads“ or „All DMs“ are for you, as these options will show everything in one big, scrollable list. There’s not just a dark mode, there’s a fully customizable theme system—just type in whatever hex codes you want. You can create and upload your own emoji, even animated ones (at Ars, we have 410 custom emojis and counting). Slack also supports multiple organization workspaces, so here it’s possible to not just be in the Ars Technica Slack, with all the usual people, rooms, and emojis, but also the Conde Nast Slack, with a whole different set of people, rooms, and other settings. There are probably a million other things I’m forgetting about. Slack is a very mature app.
Google Chat is not even close to Slack, but Slack is nearly twice the age of Google Chat. Can Google Chat catch up? Right now it does not seem like Google is giving the app the focus or resources it needs to compete. In the same way that Facebook snapped up WhatsApp for $22 billion in 2014, in December 2020, Slack was acquired by Salesforce for an incredible $27.7 billion. Once again this deal shows that Google’s competitors value a single messaging app to be worth tens of billions of dollars, while Google seems to value messaging at an order of magnitude less than that. Has Google ever invested even a fraction of Slack’s price tag into a single app? Google Chat certainly doesn’t seem like anywhere close to a $27 billion app.
We’ll deal with Google Chat’s big consumer pivot later on, but for now, it’s on to the next project.
Google Maps Messages (2018)—Business messaging, now with the instability of Google
Lifetime: November 14, 2018—Present
Clients: Android, iOS
Customer service happens through Google Maps all the time. You look up a business on the site or app and have a question about what services they offer. Traditionally, you call them up. What if you could do that through instant messaging, though?
When, exactly, you want to start qualifying this as a „Google“ messaging service is up for debate, but it definitely is today. Google officially launched a „Message“ button in Maps in July 2017. At first, just as the „call“ button would launch your phone app, the „Message“ button would launch your SMS app. From there, you could text Google (not the business), which would forward the message on to the business.
In this first version, businesses could sign up for Google’s messaging support one of two ways. First, just give Google an SMS number, and the company could forward all your messages to that number, where you could easily reply. The second option, hilariously, was to receive messages through Google Allo! At this point, the Allo app was about one year into its two-year lifetime, and it apparently powered this feature on Google’s back end. Oh no.
For consumers, the entire way this „Message“ button worked was changed in November 2018, when Google Maps got a full-blown messaging UI. Instead of firing up an SMS app, Google Maps got its own in-house version of the ubiquitous bubble-powered message UI. It also got a message inbox, where you could see all of the messages you’ve ever sent (but, to businesses), just like every other messaging app on Earth. At launch, the message inbox got a premium spot in the slide-out navigation panel, where „Messages“ lived right between „Your contributions“ (reviews and photos) and „Location Sharing.“ Today the slide-out navigation panel is dead, and in the new bottom tab UI, the Messages inbox is in the „Updates“ tab.
With the death of Allo, the back-end of this had to change for businesses, and in 2019 Google’s solution was to bring the entire messaging system in-house. Allo was, of course, removed as an option to receive customer messages, but so was SMS. Now, businesses have to use the „Google My Business“ app for iOS or Android to reply to customers, making Maps Messaging a truly independent Google Messaging Service. For businesses that (understandably) don’t want to communicate to the entire world through a phone, there’s also the Google Business Messages API, a REST API that allows larger companies to plug the system into some kind of customer management app.
All of this messaging stuff is only on the Google Maps app, by the way. You can’t message businesses from the Google Maps website. This made total sense in 2017 when the feature opened up your phone’s SMS app—but most desktops don’t have an SMS app. Now that the entire end-to-end messaging system is a web-based Google service, though, there is no reason you can’t do it from maps.google.com. When will we get yet another Google website with a pop-up chat window?
This entire section is pretty much Google copying Facebook’s business messaging feature, which it has on Facebook Business pages. You know what Facebook business messages use, though? Facebook Messenger! Things are so simple when you have a stable messaging platform.
Google & RCS (2019)—So we found this dusty old messaging standard in a closet…
Lifetime: July 2019—Present
Platforms: Android, Phone-based web interface
When Google announced it was „pausing“ Allo development in 2018, it also announced it had found a hot new fling: Rich Communication Service, or RCS Messaging. RCS was cooked up by the GSM Association in 2008 as an upgrade to SMS. It adds a few really basic features to carrier messaging, like user presence, typing status, read receipts, and location sharing. The way RCS is supposed to work is that Verizon, AT&T, T-Mobile, and all the other carriers upgrade from SMS to RCS, and then all the texting apps on the network get to talk to each other. If you can’t tell from the standard’s 13-year-old origins, the rollout of RCS is best mapped out on a geologic time scale, with carriers occasionally paying lip service to upgrading SMS but doing very little in terms of actual action.
Google calls its RCS rollout „Chat,“ which is extremely confusing given that there is already a „Google Chat“ product that we covered earlier. The Google Chat and Google RCS Chat are not in any way related or compatible. Google’s client of choice for its RCS solution is Google Messages, aka Android’s stock SMS app. The lineage of the Google Messages app dates back to the Android 5.0 Lollipop days in 2014. A year before, Google went „full iMessage“ and killed the Android SMS app in favor of Google Hangouts SMS compatibility. Carriers didn’t like that, and Google quickly caved by building a „Messenger“ SMS app for Android 5.0. Being around for seven years means the Google Messenger app is mature and fully featured—for an SMS app. The app features Google’s smart reply buttons, a very modern UI, and even a web interface for desktops, which forwards messages from your phone to the website through a QR-Code pairing process. There’s also a „video call“ button that connects people through Duo if you both have the app installed.
Google’s fascination with RCS started in 2015 when it acquired Jibe Mobile, a back-end RCS company that was focused on selling RCS server solutions to carriers. With Jibe, Google could offer a full end-to-end RCS solution to carriers: the back-end server solutions from Jibe, and the front-end client work with Android. The carriers, already weary of how much power Google had over them with Android, opted not to turn over their entire messaging stack to Google, and pretty much nothing happened for four years. With the 2018 shutdown of Allo, Google announced it was moving some of the team over to Google Messages, with a renewed focus on RCS.
In October 2019, Verizon, AT&T, T-Mobile, and Sprint all responded by snubbing Google and launching their own RCS alliance, the „Cross Carrier Messaging Initiative (CCMI).“ The carriers talked a big talk saying they would build a „standards-based, interoperable messaging service“ and promised adopting 2008-era messaging features that would deliver „the next generation of messaging.“ The 2020 launch deadline flew by with nothing to show for it, and the whole initiative shut down in 2021 having accomplished absolutely nothing over two years.
The CCMI announcement pushed Google to counter with its own announcement: that it was giving up on carriers and would roll out its own RCS system using the Google Messages app. Not teaming up with the carriers would mean that its RCS solution would exist alongside SMS, and Google would push users to turn on „Chat features“ with a pop-up in Google Messages. This was basically turning RCS, a carrier-made messaging standard, into an over-the-top messaging service. Google first rolled out this system in the UK and France in July 2019, and as of November 2020, it’s available globally.
After the failure of CCMI, the three US carriers (RIP Sprint) have actually given in to Google’s RCS ambitions. T-Mobile, AT&T, and Verizon are all shipping Google Messages by default on Android. But critically, Apple is anti-RCS.
RCS is bad, and anyone who likes it should feel bad
Like Allo, RCS Messaging is another plan that doesn’t make a ton of sense on paper. RCS is a carrier-controlled messaging standard, and therefore not something Google has a ton of control over. Adding a feature to RCS means getting the entire carrier bureaucracy involved with debating and ratifying the new change. There is no way you can move fast enough to compete with an over-the-top messaging service controlled by a single entity. RCS might be better than SMS, but it will never be good.
RCS has a ton of downsides compared to a real messaging service, but that’s all supposed to be a worthy trade for one benefit: RCS is supposed to replace SMS, so it’s supposed to be universally available on all devices. Will that ever happen, though?
Apple does not want good messaging compatibility with Android. The company said as much in internal communication that was made public thanks to the Epic Games case. Apple’s internal debate showed it viewed iMessage’s high-quality iPhone-to-iPhone communication as „serious lock-in“ and a feature that kept users on iOS. Following this same logic, Apple doesn’t want RCS because that would make messaging with Android easier. In Apple’s view, easier communication with Android users would only help those users leave iOS.
Even if you could snap your fingers and magically roll out RCS to every device, you wouldn’t actually create a competitive messaging solution. Being a standard created in 2008 means RCS has standards from 2008, and it’s lacking things you would want from a modern messaging service, like end-to-end encryption. The Google Messenger strategy strangely insists on using RCS as the base protocol, but the service also keeps trying to build features on top of it that kick in when both users are on Google Messages.
Today, if both users are using Google Messenger, you can have all sorts of interesting features, like end-to-end encryption for 1-1 chats, reaction emojis, and audio messages, which aren’t in the RCS spec. That makes it seem like Google is almost building its own messaging service, but with really unclear compatibility and an ancient RCS protocol, which it has no control over, as the core. What is the point of this? It’s hard to see carriers shipping Google Messages as a default Android app as progress. Google can easily make any app it wants an Android default. Google Talk and Google Hangouts enjoyed default-install status for years. They shipped on every single Android phone, not just the ones from US carriers. These services were also optionally available on iOS, while RCS is not.
RCS also has all the same problems as SMS and Google Allo when it comes to how you should architect a messaging service. RCS will use your carrier-owned phone number as your identity online, instead of an Internet-based account system. Changing Internet identity from a free email account to a paid number owned by a carrier is a terrible and, I would argue, immoral idea. Tying online identity to the ability to continuously pay a phone bill is straight-up discriminatory toward people of lower income. There should not be a risk of losing your online identity if you stop paying your bill for a month or change phone carriers. There’s no upside to phone number identity at all, yet Google keeps doing it.
Carrier-owned identity means your messaging world will be dependent on your smartphone and tied to a single device, instead of being a service that just lives on the Internet and is accessible everywhere. It makes support for multiple devices and form factors difficult. Google does have a Google Messages „website,“ but it’s not a web service—instead it is just a forwarding interface for your phone, which has to be charged up, turned on, and paired to the site. Like with Allo, a QR code scanned by your phone will set up a hacky message-forwarding solution that isn’t as convenient or capable as a native web service. Google is also working on a „device pairing“ feature to ship your SMS/RCS messages to a tablet over what I assume is local networking with your phone. It all just seems like a janky, backward solution compared to simply using a web service. As a phone app, Google Messages isn’t bad, but it has zero independent clients for non-phone form factors.
Google’s RCS plans seem like a disaster. Even if it worked and universally replaced SMS, you’d end up with a bottom-tier messaging service. It’s not even going to work, though.
Google Photos Messages (2019)—You get a messaging feature! And YOU! And you!
Lifetime: December 3, 2019—Present
Platforms: Android, iOS, the Web
Enlarge/ Google Photos Messaging. You can send pictures.
Google
Who’s starting to see a pattern? With no viable Google messaging platform, I feel like Google just opened the „top apps“ listings and started slapping a messaging feature onto every popular Google service. How soon until we get „Google Search Messaging?“ Hahaha. (Actual answer: May 6, 2021.)
Think about how Facebook works. You upload a cool photo and want to tell your friends so you can post it on your social media feed or message your friends through Facebook Messenger. Easy! This was the original vision for Google Photos, which launched alongside Google+. After the amputation of Google+, it’s now up to Google Photos to try to graft on some of these social features itself. So, in December 2019, Google Photos got a messaging service.
Google Photos Messaging is pretty standard. You can start a group chat thread via the photo „share“ button, where you can send a link or directly message someone else on Google Photos. The „Sharing“ tab at the bottom of the screen is your message inbox, and you can view and reply to any existing chat threads. Photos will send you notifications when new messages come in. This is all supported on the website, too. Would you believe it supports sending pictures?
Google Stadia Messages (2020)—Two great tastes that taste great together
Lifetime: November 16, 2020—Present
Platforms: Android, iOS, the Web
Easily the most doomed section of this entire article, even Google Stadia has a messaging service. Google Stadia is (or „was,“ depending on when you’re reading this article) a game-streaming service from Google. Instead of going out and buying a game console, you can stream a video game over the Internet, one frame at a time, from Google’s computerized warehouses to your various devices. After all that time running YouTube, the technology behind Stadia is solid and works fine, provided you have great Internet latency.
Google’s poor execution of Stadia seems like it’s leading to an inevitable execution of Stadia, though. The payment model is totally crazy. Rather than just being „Netflix for games,“ Stadia asks users to buy games at full price, and then you can only play them at 1080p unless you pay another $10-a-month subscription fee to unlock 4K mode. Given Google’s history (see: this entire article you’re reading), a lot of people are hesitant to pay full price for a Google gaming service where the games might disappear any month now.
Despite being a warehouse-scale computer capable of being far more powerful than your average PC, the cloud computers you’re renting from Google aren’t even particularly good. Games like Destiny 2 can only run on the PC equivalent of „medium“ settings, and some of those 4K games you’re paying $10-a-month extra for aren’t actually in 4K—they are upscaledto 4K because Stadia is too slow to run them in native 4K. Google is currently facing a lawsuit over false „4K“ advertising. Google refuses to lean into the good parts of game-streaming technology, which is that a warehouse-scale computer could be way faster than any local computer you could possibly build, if Google would just allocate the resources for it. This is the traditional sales pitch behind cloud computing, after all. Cloud games also have an instant start-up time with no install, which would make them great for game demos.
Couple those issues with Google’s shaky history of keeping services running, and Stadia seems doomed. The dominoes are already falling, in fact. User signups were reportedly „hundreds of thousands“ short of what Google was expecting, and the company closed its in-house development studio before it had time to develop a single game. Stadia’s VP and head of product quit, then the head of engineering quit. It seems like it’s only a matter of time before it’s game over for Stadia.
Wait, what were we talking about? Oh yeah, Stadia has a totally siloed messaging service. The feature rolled out in November 2020, about one year after Stadia’s incredibly bare-bones and underwhelming launch. It seems pretty normal. You can find people by their email address or Stadia gamer tag, provided that their profile is set up to be publicly searchable. It really seems like Stadia should plug into something for contacts, but it can’t even scan your phone contact list, Gmail, or a messaging app to find Stadia players you already know. Instead, you’ve just got to type everything in manually. The truth is, you probably don’t know any Stadia players, but it would be nice to scan your contacts so you could message ‚em.
Google Pay Messages (2021)—We actually learned nothing from Google Allo
Lifetime: March 4, 2021—Present
Platforms: Android, iOS
In 2021, Google completely re-launched Google Pay. It threw out the old codebase that had previously existed first as Google Wallet, then Android Pay, then Google Pay, and the company instead rolled out a completely different „Google Pay“ product it had developed in India. This product was originally called „Google Tez.“ Users making the transition lost their contact list and a lot of functionality, so we basically saw the shutdown of one service called „Google Pay“ and the launch of a completely separate, new service, also called „Google Pay.“
Just like Google Allo, which was also targeted at India initially, the new Google Pay uses your cell carrier’s phone number for your identity, which causes a whole bunch of problems. It takes what used to be a modern, Internet-based account system and throws it out in favor of tying your identity to your phone number, which you don’t control and is tied to your ability to pay a monthly bill. Old Google Pay could be accessed from anywhere you had an Internet connection, but carrier identity systems mean that now, you can only use your smartphone to access the service. As a result, the Google Pay website had to have all the functionality stripped out of it. Carrier-based identity systems might make sense in places where people only have a smartphone, but in the US, it’s very limiting. There’s also no clear upside that I can see. Why not just use a Google account like normal? People who want to use a Google product have a Google account. People who don’t have Google accounts at this point are generally boycotting the entire company.
Google Pay has long had the ability to send money to a friend or contact, and New Google Pay added—you guessed it—messaging! Existing users of old Google Pay had a list of contacts, but with the move to the new Google Pay, all your new contacts have to re-signup for the service again (because New Google Pay is a totally different service from old Google Pay, sigh). Provided you have such friends who made new accounts, you can add them to your Google Pay contacts, and then you’ll see three options: „Pay,“ „Request,“ and „Message.“
Payments are built into a lot of other messaging services, like WhatsApp, Facebook Messenger, and iMessage. Like Google Photos, the plan here is to try to replicate that by glomming a basic messaging service onto Google’s existing product. In reality, this decision just further fragments users across a million different Google messaging apps and features.
Google Assistant Messages (2021)—Text and voice chat, for families?
Lifetime: May 6, 2021—Present
Platforms: Android, iOS, smart displays
It’s amazing we don’t get more variety in messaging services given the sheer number of them that Google has launched. But finally, here’s something different: a voice-first messaging system. The Google Assistant has long had a feature called „Broadcast,“ which would blast out a message to every device on the same Wi-Fi network, making it sort of like an intercom system for your Google Nest speakers and smart displays.
In May 2021, Google expanded the Assistant’s Broadcast to work on phones, even when they’re not on your home network. You don’t always want to scream into your phone in public, and you don’t want to blast a broadcast message out of the speakers, so the new interface includes transcriptions of all the incoming voice messages plus a text input field. The interface for this is absolutely a messaging app with a play button below each text message for playback of any audio. At home on a Google smart speaker, a voice can read out any messages you send.
On Android, the Google Assistant is built into the Google Search app, so if anyone is making a „Google Search Messaging“ joke, that already exists! On iOS, messages arrive through a dedicated Google Assistant app. The one big limitation of this messaging service is that it’s for family members only, meaning people you have in your Google Family Group. It’s like a messaging app for a single „Family“ group chat.
Google Phone Messaging (2021)—Isn’t this going a little too far?
Lifetime: June 2021—Present
Platforms: Android
Every phone has two pretty basic apps: the phone app for phone calls and a messaging app for text messages. For a long time, Google has had an option in the phone app dialer to „Send a message,“ which would forward the typed-in number to your default messaging app. This is fine and normally wouldn’t count for our purposes.
Recently, though, Android Police spotted some versions of the phone app that, for some businesses, will show a „Chat“ button next to the „Call“ button after you’ve typed in a number. Instead of launching a separate messaging app, this would launch a totally new messaging interface, which the „recent apps“ screen identifies as part of Google Play Services. Presumably, this is based on the same kind of business messaging as Google Maps but with a whole new Google Phone client, for some reason. I know better than to ask for messaging unity at this point. Unity is for wimps!
Google Chat, Part 2 (2021)—No wait, this is actually a consumer app now!
Lifetime: June 14, 2021—Present
Platforms: Android, iOS, web, Gmail
We made it—meet the last messaging app on our list. The future of Google Messaging, for now, is Google Chat. We’re cheating a bit by giving Google Chat a second section, but that’s really what it feels like—a complete reboot and pivot of an existing project.
When Google Hangouts Chat was first announced, it was basically pitched as Google’s Slack competitor. Google’s 2017 blog post called the service „a communication tool focused on the way teams work“ that was „purpose-built“ to „help employees succeed.“ Suddenly, at the end of 2018, Google started talking about Hangouts Chat as if it was a consumer chat app.
When I say „suddenly,“ I mean it. Google Chat for consumers got what has to be one of the worst product announcements of all time: it was unveiled in an angry Twitter thread from Hangouts project lead Scott Johnston. Johnston took issue with a 9to5Google report that claimed that Google was shutting down Google Hangouts (the 2013 app), calling it „shoddy reporting“ because it „is only half the story.“ Johnston then dumped the other half out on Twitter: Hangouts, which Johnston was now calling „Hangouts Classic,“ would be transitioned to Google Chat, the enterprise communication app. What in the world?
Google Chat started life as „Google Hangouts Chat.“ So looking back, it might seem like porting over Hangouts users was the plan all along, but that definitely was not communicated by Google. Google Hangouts Chat was an enterprise app that you needed to pay for, and Hangouts was a free consumer chat app. Since this would be the third time a mostly unrelated service was called „Hangouts,“ everyone mostly just rolled their eyes and laughed at Google’s terrible branding. It was unthinkable that the two would merge. It didn’t make any sense.
Three days later, Google got its act together and put out a formal blog post. The post confirmed 9to5’s report that Google Hangouts was shutting down, and it laid out a questionable transition plan, saying, „[Google] Chat and Meet are primarily focused on team collaboration for G Suite customers and at some point will be made available for existing Hangouts users, too.“ So Google Chat is still an enterprise Slack competitor, but you’re going to push your consumer user base over to it anyway? What sense does that make?
Google Hangouts represents Google’s biggest consumer messaging userbase because it has been around forever. While Google messaging apps have grown and been cut down like so many blades of grass over the years, the one throughline is Google Talk users, who were more or less smoothly transitioned from Talk to Google Hangouts. They’ve been clinging onto Google’s wobbly messaging platform for 16 years. It sounds like somebody at Google realized they should do something with these users, and all of a sudden, enterprise Google Chat was drafted as the next app they would be pushed over to.
Starting in late 2020, Google Chat started opening up to free consumer accounts, instead of via the exclusive paywalled Google Workspace. At the time of writing, we’re firmly in the transition period between Google Chat and Google Hangouts. Unlike some of Google’s more calamitous user transitions lately—like moving from old Google Pay to new Google Pay, or from Google Play Music to YouTube Music—it looks like the transition from Google Hangouts to Google Chat will not be a disaster.
Currently, you can use both Hangouts and Google Chat, and your messages and contacts will show up in both apps. Google Chat mostly works and is fully functional, with support for image uploads, group chat, and most other things you could want. Hangouts users are getting gently pushed to Google Chat with a few pop-up messages that have started showing up in the UI. The interface is mostly a drop-in replacement for Google Hangouts, with a lot of the same features just in a more modern client. Google Chat adds @mentions—which are great for group chats—along with emoji reactions to messages and AI-generated smart replies.
The main oddity is Google Chat’s insistence on treating group chat rooms like some separate form of communication instead of listing them alongside your other chats. The interface is awkwardly split up into „Chat“ and „Rooms“ on the web, and these are in different panels. In the phone app, however, they are on totally different screens thanks to the tab interface. It makes chat rooms a pain to use. Another major problem with chat rooms is that they don’t show a preview for the last message in the message list, so they’re very hard to keep up with.
Google Chat’s „Rooms“ and „Chat“ break down is just like Slack’s Channels and DMs, but the difference is that Slack is an organization-wide app, so this breakdown makes a bit more sense. There are channels and people I don’t interact with, but they need to exist for other people. My list of contacts and rooms in Google Chat is personal and a lot smaller than Slack, so just putting everything in a flat list would be a lot easier. Slack also lets you star channels and contacts, giving you a flat list of people and group chats you frequently use all on the same screen. That basic functionality is all I want.
Google Chat is from the Google Workspace team, which also controls Gmail, so Chat is getting deep Gmail integration in an attempt to put the service in the face of as many users as possible. Google Talk and Hangouts have previously been built into gmail.com, just never like this. Google Chat basically gets free run of the place, with two sidebar sections, a pop-up, a status selector in the top-right corner, and a crazy split-screen interface that puts Google Chat on the left side of the screen and Google Docs on the other.
Google Chat also took the unprecedented move of being integrated into the Gmail smartphone app, which I guess is like the modern equivalent of being built into Gmail.com. With Google Chat, the Gmail app has a new tab bar at the bottom that can jump into interfaces for Meet or Chat, and Chat is fully functional with notifications, contacts, and everything else you’d want from a messaging app. You don’t need to have the Google Chat app installed at all, provided you have the Gmail app.
If you have Gmail and Google Chat installed, you’ll be notified twice of any incoming messages, and Gmail actually has a pop-up pointing this out. The pop-up recommends that you turn off notifications for the standalone Google Chat app and exclusively use Gmail for your Google Chatting, which really goes against the normal smartphone interface of individual app icons.
The big thing Google Chat has going for it is that, as a primarily enterprise app within Google Workspace, it has an actual monetization plan. Fifteen years ago, Google Talk stripped the banner ads out of the standard instant messenger interface, and this is the first time since that Google has come up with a monetization replacement plan. Companies pay for Google Workspace, and presumably, some of that Workspace money is being attributed to Google Chat. Will this be enough to keep the project going and finally provide some stability to Google Messaging?
Is anyone in charge at Google?
Even with all this shoddy history, Google doesn’t seem to have learned anything. Today, the confusing, intimidating pile of Google Messaging services is bigger than it has ever been, with Google Chat, Google Messages/RCS, Google Voice/Project Fi, and separate messaging services in Photos, Messages, Pay, Assistant, Stadia, Maps, and Phone. If you’re really an expert, you can probably narrow this list down somewhat, but Google is still simultaneously pushing the enterprise-first-but-also-consumer-messaging app, Google Chat, while also duplicating efforts and muddying its sales pitch to users with RCS on Google Messages. Which services does Google really care about? Which one is the future of the company? It’s hard to say.
The overwhelming impression from Google’s continual messaging chaos is that nobody at the company is really in charge. Some products at Google get mandatory support and hiring (like the advertising division), but others, like messaging, rely on the enthusiasm and availability of individual employees to be continually supported and stay running. Google has previously defended this hands-off management style as „letting a thousand flowers bloom,“ but the company’s messaging situation is more like a yard full of weeds—neglected, embarrassing, and damaging to the company’s reputation.
Apple calls messaging the „most important apps in a mobile environment.“ Facebook and Salesforce invest tens of billions of dollars into messaging, making acquisitions of WhatsApp and Slack some of the biggest deals in the tech industry, ever. Google, on the other hand, can’t be bothered to hold down a stable messaging project. It’s really incredible how out of step Google’s thinking is with its competitors.
If Google treated messaging like most of its competitors do, there would be a top-down mandate that messaging be a pillar of the company alongside Search, Gmail, Chrome, Android, Google Docs, Maps, and YouTube. The messaging strategy wouldn’t change every two years, and Google might actually have a chance to grow a messaging user base. The person that is supposed to be implementing some kind of strategy is Google CEO Sundar Pichai, but his timid management style means nobody is directing Google employees to put in the hard work of building and maintaining a messaging platform. Instead, individual groups at the company are free to fire off half-baked products into the public, and these releases get outsized attention, media coverage, and initial traction thanks to the „Google“ name. From there, they damage trust in the Google brand when services are shut down.
Enlarge/ This comic from former Googler (and Google Inbox team member) Manu Cornet perfectly describes how Google miscalculates the cost of product shutdowns.
I’ve written before about how Google’s constant product shutdowns damage the brand, and messaging apps are one of the biggest contributors to the growing Google graveyard. Switching to a messaging app requires a big commitment, with the need to get friends and family to switch. Like any social app, messaging apps are dependent on the network effect, and shutting them down every two years is a great way to sabotage any possible user adoption.
Being kicked off a service has a lasting effect on a user. Google treats shutdowns like they are no big deal, but it’s more like burning a bridge with everyone on it who used the service. I think it’s part of the reason public perception of Google has changed over the years. There used to be a lot more Google fans out there—people were optimistic about Google and eager to try any new Google products. If Google managed its products well, today these people might be vocal product advocates, similar to the support companies like Apple or Tesla enjoy. Instead, being a Google enthusiast over the years has meant getting hit frequently by Google shutdowns. Today, I don’t think there are many Google advocates left, and it’s hard to be optimistic about any new product launch.
The Google Talk saga is a case in point. It feels like it’s for a company that doesn’t exist today. When Google Talk launched, there was an assumption that Google would dominate messaging, because back then, Google was seen as a disrupter and a company that put effort behind the new markets it entered. Today, no one assumes Google will be successful in a new market. And it’s because of what we outlined here, a list of so many low-effort projects.
Enlarge/ Come to think of it, maybe you shouldn’t open this one at all.
Aurich / Thinkstock
I pretty frequently get requests for help from someone who has been impersonated—or whose child has been impersonated—via email. Even when you know how to „view headers“ or „view source“ in your email client, the spew of diagnostic wharrgarbl can be pretty overwhelming if you don’t know what you’re looking at. Today, we’re going to step through a real-world set of (anonymized) email headers and describe the process of figuring out what’s what.
Before we get started with the actual headers, though, we’re going to take a quick detour through an overview of what the overall path of an email message looks like in the first place. (More experienced sysadmin types who already know what stuff like „MTA“ and „SPF“ stand for can skip a bit ahead to the fun part!)
From MUA to MTA, and back to MUA again
The basic components involved in sending and receiving email are the Mail User Agent and Mail Transfer Agent. In the briefest possible terms, an MUA is the program you use to read and send mail from your own personal computer (like Thunderbird, or Mail.app, or even a webmail interface like Gmail or Outlook), and MTAs are programs that accept messages from senders and route them along to their final recipients.
Traditionally, mail was sent to a mail server using the Simple Mail Transfer Protocol (SMTP) and downloaded from the server using the Post Office Protocol (abbreviated as POP3, since version 3 is the most commonly used version of the protocol). A traditional Mail User Agent—such as Mozilla Thunderbird—would need to know both protocols; it would send all of its user’s messages to the user’s mail server using SMTP, and it would download messages intended for the user from the user’s mail server using POP3.
As time went by, things got a bit more complex. IMAP largely superseded POP3 since it allowed the user to leave the actual email on the server. This meant that you could read your mail from multiple machines (perhaps a desktop PC and a laptop) and have all of the same messages, organized the same way, everywhere you might check them.
Finally, as time went by, webmail became more and more popular. If you use a website as your MUA, you don’t need to know any pesky SMTP or IMAP server settings; you just need your email address and password, and you’re ready to read.
Ultimately, any message from one human user to another follows the path of MUA ⟶ MTA(s) ⟶ MUA. The analysis of email headers involves tracing that flow and looking for any funny business.
TLS in-flight encryption
The original SMTP protocol had absolutely no thought toward security—any server was expected to accept any message, from any sender, and pass the message along to any other server it thought might know how to get to the recipient in the To: field. That was fine and dandy in email’s earliest days of trusted machines and people, but it rapidly turned into a nightmare as the Internet scaled exponentially and became more commercially valuable.
It’s still possible to send email with absolutely no thought toward encryption or authentication, but such messages will very likely get rejected along the way by anti-spam defenses. Modern email typically is encrypted in-flight, and signed and authenticated at-rest. In-flight encryption is accomplished by TLS, which helps keep the content of a message from being captured or altered in-flight from one server to another. That’s great, so far as it goes, but in-flight TLS is only applied when mail is being relayed from one MTA to another MTA along the delivery path.
If an email travels from the sender through three MTAs before reaching its recipient, any server along the way can alter the content of the message—TLS encrypts the transmission from point to point but does nothing to verify the authenticity of the content itself or the path through which it’s traveling.
SPF—the Sender Policy Framework
The owner of a domain can set a TXT record in its DNS that states what servers are allowed to send mail on behalf of that domain. For a very simple example, Ars Technica’s SPF record says that email from arstechnica.com should only come from the servers specified in Google’s SPF record. Any other source should be met with a SoftFail error; this effectively means „trust it less, but don’t necessarily yeet it into the sun based on this alone.“
SPF headers in an email can’t be completely trusted after they’re generated, because there is no encryption involved. SPF is really only useful to the servers themselves, in real time. If a server knows that it’s at the outside boundary edge of a network, it also knows that any message it receives should be coming from a server specified in the sender’s domain’s SPF record. This makes SPF a great tool for getting rid of spam quickly.
DKIM—DomainKeys Identified Mail
Similarly to SPF, DKIM is set in TXT records in a sending domain’s DNS. Unlike SPF, DKIM is an authentication technique that validates the content of the message itself.
The owner of the sending domain generates a public/private key pair and stores the public key in a TXT record on the domain’s DNS. Mail servers on the outer boundary of the domain’s infrastructure use the private DKIM key to generate a signature (properly an encrypted hash) of the entire message body, including all headers accumulated on the way out of the sender’s infrastructure. Recipients can decrypt the DKIM signature using the public DKIM key retrieved from DNS, then make sure the hash matches the entire message body, including headers, as they received it.
If the decrypted DKIM signature is a matching hash for the entire body, the message is likely to be legitimate and unaltered—at least as verified by a private key belonging only to the domain owner (the end user does not have or need this key). If the DKIM signature is invalid, you know that the message either did not originate from the purported sender’s domain or has been altered (even if only by adding extra headers) by some other server in between. Or both!
This becomes extremely useful when trying to decide whether a set of headers is legitimate or spoofed—a matching DKIM signature means that the sender’s infrastructure vouches for all headers below the signature line. (And that’s all it means, too—DKIM is merely one tool in the mail server admin’s toolbox.)
DMARC—Domain-based Message Authentication, Reporting, and Conformance
DMARC extends SPF and DKIM. It’s not particularly exciting from the perspective of someone trying to trace a possibly fraudulent email; it boils down to a simple set of instructions for mail servers about how to handle SPF and DKIM records. DMARC can be used to request that a mail server pass, quarantine, or reject a message based on the outcome of SPF and DKIM verification, but it does not add any additional checks on its own.
The millions of dots on the map trace highways, side streets and bike trails — each one following the path of an anonymous cellphone user.
One path tracks someone from a home outside Newark to a nearby Planned Parenthood, remaining there for more than an hour. Another represents a person who travels with the mayor of New York during the day and returns to Long Island at night.
Yet another leaves a house in upstate New York at 7 a.m. and travels to a middle school 14 miles away, staying until late afternoon each school day. Only one person makes that trip: Lisa Magrin, a 46-year-old math teacher. Her smartphone goes with her.
An app on the device gathered her location information, which was then sold without her knowledge. It recorded her whereabouts as often as every two seconds, according to a database of more than a million phones in the New York area that was reviewed by The New York Times. While Ms. Magrin’s identity was not disclosed in those records, The Times was able to easily connect her to that dot.
The app tracked her as she went to a Weight Watchers meeting and to her dermatologist’s office for a minor procedure. It followed her hiking with her dog and staying at her ex-boyfriend’s home, information she found disturbing.
“It’s the thought of people finding out those intimate details that you don’t want people to know,” said Ms. Magrin, who allowed The Times to review her location data.
Like many consumers, Ms. Magrin knew that apps could track people’s movements. But as smartphones have become ubiquitous and technology more accurate, an industry of snooping on people’s daily habits has spread and grown more intrusive.
At least 75 companies receive anonymous, precise location data from apps whose users enable location services to get local news and weather or other information, The Times found. Several of those businesses claim to track up to 200 million mobile devices in the United States — about half those in use last year. The database reviewed by The Times — a sample of information gathered in 2017 and held by one company — reveals people’s travels in startling detail, accurate to within a few yards and in some cases updated more than 14,000 times a day.
These companies sell, use or analyze the data to cater to advertisers, retail outlets and even hedge funds seeking insights into consumer behavior. It’s a hot market, with sales of location-targeted advertising reaching an estimated $21 billion this year. IBM has gotten into the industry, with its purchase of the Weather Channel’s apps. The social network Foursquare remade itself as a location marketing company. Prominent investors in location start-ups include Goldman Sachs and Peter Thiel, the PayPal co-founder.
Businesses say their interest is in the patterns, not the identities, that the data reveals about consumers. They note that the information apps collect is tied not to someone’s name or phone number but to a unique ID. But those with access to the raw data — including employees or clients — could still identify a person without consent. They could follow someone they knew, by pinpointing a phone that regularly spent time at that person’s home address. Or, working in reverse, they could attach a name to an anonymous dot, by seeing where the device spent nights and using public records to figure out who lived there.
Many location companies say that when phone users enable location services, their data is fair game. But, The Times found, the explanations people see when prompted to give permission are often incomplete or misleading. An app may tell users that granting access to their location will help them get traffic information, but not mention that the data will be shared and sold. That disclosure is often buried in a vague privacy policy.
“Location information can reveal some of the most intimate details of a person’s life — whether you’ve visited a psychiatrist, whether you went to an A.A. meeting, who you might date,” said Senator Ron Wyden, Democrat of Oregon, who has proposed bills to limit the collection and sale of such data, which are largely unregulated in the United States.
“It’s not right to have consumers kept in the dark about how their data is sold and shared and then leave them unable to do anything about it,” he added.
Mobile Surveillance Devices
After Elise Lee, a nurse in Manhattan, saw that her device had been tracked to the main operating room at the hospital where she works, she expressed concern about her privacy and that of her patients.
“It’s very scary,” said Ms. Lee, who allowed The Times to examine her location history in the data set it reviewed. “It feels like someone is following me, personally.”
The mobile location industry began as a way to customize apps and target ads for nearby businesses, but it has morphed into a data collection and analysis machine.
Retailers look to tracking companies to tell them about their own customers and their competitors’. For a web seminar last year, Elina Greenstein, an executive at the location company GroundTruth, mapped out the path of a hypothetical consumer from home to work to show potential clients how tracking could reveal a person’s preferences. For example, someone may search online for healthy recipes, but GroundTruth can see that the person often eats at fast-food restaurants.
“We look to understand who a person is, based on where they’ve been and where they’re going, in order to influence what they’re going to do next,” Ms. Greenstein said.
Financial firms can use the information to make investment decisions before a company reports earnings — seeing, for example, if more people are working on a factory floor, or going to a retailer’s stores.
Health care facilities are among the more enticing but troubling areas for tracking, as Ms. Lee’s reaction demonstrated. Tell All Digital, a Long Island advertising firm that is a client of a location company, says it runs ad campaigns for personal injury lawyers targeting people anonymously in emergency rooms.
“The book ‘1984,’ we’re kind of living it in a lot of ways,” said Bill Kakis, a managing partner at Tell All.
Jails, schools, a military base and a nuclear power plant — even crime scenes — appeared in the data set The Times reviewed. One person, perhaps a detective, arrived at the site of a late-night homicide in Manhattan, then spent time at a nearby hospital, returning repeatedly to the local police station.
Two location firms, Fysical and SafeGraph, mapped people attending the 2017 presidential inauguration. On Fysical’s map, a bright red box near the Capitol steps indicated the general location of President Trump and those around him, cellphones pinging away. Fysical’s chief executive said in an email that the data it used was anonymous. SafeGraph did not respond to requests for comment.
More than 1,000 popular apps contain location-sharing code from such companies, according to 2018 data from MightySignal, a mobile analysis firm. Google’s Android system was found to have about 1,200 apps with such code, compared with about 200 on Apple’s iOS.
The most prolific company was Reveal Mobile, based in North Carolina, which had location-gathering code in more than 500 apps, including many that provide local news. A Reveal spokesman said that the popularity of its code showed that it helped app developers make ad money and consumers get free services.
To evaluate location-sharing practices, The Times tested 20 apps, most of which had been flagged by researchers and industry insiders as potentially sharing the data. Together, 17 of the apps sent exact latitude and longitude to about 70 businesses. Precise location data from one app, WeatherBug on iOS, was received by 40 companies. When contacted by The Times, some of the companies that received that data described it as “unsolicited” or “inappropriate.”
WeatherBug, owned by GroundTruth, asks users’ permission to collect their location and tells them the information will be used to personalize ads. GroundTruth said that it typically sent the data to ad companies it worked with, but that if they didn’t want the information they could ask to stop receiving it.
The Times also identified more than 25 other companies that have said in marketing materials or interviews that they sell location data or services, including targeted advertising.
The spread of this information raises questions about how securely it is handled and whether it is vulnerable to hacking, said Serge Egelman, a computer security and privacy researcher affiliated with the University of California, Berkeley.
“There are really no consequences” for companies that don’t protect the data, he said, “other than bad press that gets forgotten about.”
A Question of Awareness
Companies that use location data say that people agree to share their information in exchange for customized services, rewards and discounts. Ms. Magrin, the teacher, noted that she liked that tracking technology let her record her jogging routes.
Brian Wong, chief executive of Kiip, a mobile ad firm that has also sold anonymous data from some of the apps it works with, says users give apps permission to use and share their data. “You are receiving these services for free because advertisers are helping monetize and pay for it,” he said, adding, “You would have to be pretty oblivious if you are not aware that this is going on.”
But Ms. Lee, the nurse, had a different view. “I guess that’s what they have to tell themselves,” she said of the companies. “But come on.”
Ms. Lee had given apps on her iPhone access to her location only for certain purposes — helping her find parking spaces, sending her weather alerts — and only if they did not indicate that the information would be used for anything else, she said. Ms. Magrin had allowed about a dozen apps on her Android phone access to her whereabouts for services like traffic notifications.
But it is easy to share information without realizing it. Of the 17 apps that The Times saw sending precise location data, just three on iOS and one on Android told users in a prompt during the permission process that the information could be used for advertising. Only one app, GasBuddy, which identifies nearby gas stations, indicated that data could also be shared to “analyze industry trends.”
More typical was theScore, a sports app: When prompting users to grant access to their location, it said the data would help “recommend local teams and players that are relevant to you.” The app passed precise coordinates to 16 advertising and location companies.
A spokesman for theScore said that the language in the prompt was intended only as a “quick introduction to certain key product features” and that the full uses of the data were described in the app’s privacy policy.
The Weather Channel app, owned by an IBM subsidiary, told users that sharing their locations would let them get personalized local weather reports. IBM said the subsidiary, the Weather Company, discussed other uses in its privacy policy and in a separate “privacy settings” section of the app. Information on advertising was included there, but a part of the app called “location settings” made no mention of it.
The app did not explicitly disclose that the company had also analyzed the data for hedge funds — a pilot program that was promoted on the company’s website. An IBM spokesman said the pilot had ended. (IBM updated the app’s privacy policy on Dec. 5, after queries from The Times, to say that it might share aggregated location data for commercial purposes such as analyzing foot traffic.)
Even industry insiders acknowledge that many people either don’t read those policies or may not fully understand their opaque language. Policies for apps that funnel location information to help investment firms, for instance, have said the data is used for market analysis, or simply shared for business purposes.
“Most people don’t know what’s going on,” said Emmett Kilduff, the chief executive of Eagle Alpha, which sells data to financial firms and hedge funds. Mr. Kilduff said responsibility for complying with data-gathering regulations fell to the companies that collected it from people.
Many location companies say they voluntarily take steps to protect users’ privacy, but policies vary widely.
For example, Sense360, which focuses on the restaurant industry, says it scrambles data within a 1,000-foot square around the device’s approximate home location. Another company, Factual, says that it collects data from consumers at home, but that its database doesn’t contain their addresses.
Some companies say they delete the location data after using it to serve ads, some use it for ads and pass it along to data aggregation companies, and others keep the information for years.
Several people in the location business said that it would be relatively simple to figure out individual identities in this kind of data, but that they didn’t do it. Others suggested it would require so much effort that hackers wouldn’t bother.
It “would take an enormous amount of resources,” said Bill Daddi, a spokesman for Cuebiq, which analyzes anonymous location data to help retailers and others, and raised more than $27 million this year from investors including Goldman Sachs and Nasdaq Ventures. Nevertheless, Cuebiq encrypts its information, logs employee queries and sells aggregated analysis, he said.
There is no federal law limiting the collection or use of such data. Still, apps that ask for access to users’ locations, prompting them for permission while leaving out important details about how the data will be used, may run afoul of federal rules on deceptive business practices, said Maneesha Mithal, a privacy official at the Federal Trade Commission.
“You can’t cure a misleading just-in-time disclosure with information in a privacy policy,” Ms. Mithal said.
Following the Money
Apps form the backbone of this new location data economy.
The app developers can make money by directly selling their data, or by sharing it for location-based ads, which command a premium. Location data companies pay half a cent to two cents per user per month, according to offer letters to app makers reviewed by The Times.
Targeted advertising is by far the most common use of the information.
Google and Facebook, which dominate the mobile ad market, also lead in location-based advertising. Both companies collect the data from their own apps. They say they don’t sell it but keep it for themselves to personalize their services, sell targeted ads across the internet and track whether the ads lead to sales at brick-and-mortar stores. Google, which also receives precise location information from apps that use its ad services, said it modified that data to make it less exact.
Smaller companies compete for the rest of the market, including by selling data and analysis to financial institutions. This segment of the industry is small but growing, expected to reach about $250 million a year by 2020, according to the market research firm Opimas.
Apple and Google have a financial interest in keeping developers happy, but both have taken steps to limit location data collection. In the most recent version of Android, apps that are not in use can collect locations “a few times an hour,” instead of continuously.
Apple has been stricter, for example requiring apps to justify collecting location details in pop-up messages. But Apple’s instructions for writing these pop-ups do not mention advertising or data sale, only features like getting “estimated travel times.”
A spokesman said the company mandates that developers use the data only to provide a service directly relevant to the app, or to serve advertising that met Apple’s guidelines.
Apple recently shelved plans that industry insiders say would have significantly curtailed location collection. Last year, the company said an upcoming version of iOS would show a blue bar onscreen whenever an app not in use was gaining access to location data.
The discussion served as a “warning shot” to people in the location industry, David Shim, chief executive of the location company Placed, said at an industry event last year.
After examining maps showing the locations extracted by their apps, Ms. Lee, the nurse, and Ms. Magrin, the teacher, immediately limited what data those apps could get. Ms. Lee said she told the other operating-room nurses to do the same.
“I went through all their phones and just told them: ‘You have to turn this off. You have to delete this,’” Ms. Lee said. “Nobody knew.”
Records show a device entering Gracie Mansion, the mayor’s residence, before traveling to a Y.M.C.A. in Brooklyn that the mayor frequents.
It travels to an event on Staten Island that the mayor attended. Later, it returns to a home on Long Island.
An app on Lisa Magrin’s cellphone collected her location information, which was then shared with other companies. The data revealed her daily habits, including hikes with her dog, Lulu.Nathaniel Brooks for The New York Times
A notice that Android users saw when theScore, a sports app, asked for access to their location data.
The Weather Channel app showed iPhone users this message when it first asked for their location data.
In the data set reviewed by The Times, phone locations are recorded in sensitive areas including the Indian Point nuclear plant near New York City. By Michael H. Keller | Satellite imagery by Mapbox and DigitalGlobe
It’s onto me, anyway. I am merely one anecdata point among billions, but I’m sure I’m not the only Facebook user who has found herself shying away from the very public, often performative, and even tiring habit of posting regular updates to Facebook and Instagram. Over the past year I’ve found myself thinking not about quitting social networks, but about redefining them. For me, that process has involved a lot more private messaging.
Facebook, it seems, has noticed. Last week, The New York Times reported that Facebook chief executive Mark Zuckerberg plans to unify Facebook Messenger, WhatsApp, and Instagram messaging on the backend of the services. This would make it possible for people relying on different flavors of Facebook apps to all gorge at the same messaging table. On the one hand, the move is truly Facebookian—just try to extricate yourself from Facebook, and it will try every which way to pull you back in. On the other hand, it makes sense for Facebook for a few reasons.
My personal relationship with Facebook is multi-faceted. I have a personal account and a journalist’s page. I also use Instagram and WhatsApp. But last year, I let my professional page languish. I stopped posting to my personal feed as frequently. Instead I turned to private messaging.
During a trip to Europe last fall, I shared everything I felt compelled to share with a small group of people on Apple Messages. The excursion to see one of the largest waves ever surfed by a human? I shared the photo in a private Slack message with coworkers, instead of posting on Facebook. Wedding photos no longer go up on Instagram. During the holidays, I happily embrace my role as halfway-decent photographer, but when I share the photos with friends and family, it’s only through Messages, WhatsApp, or private photo albums.
These tools have become my preferred method of communicating. It’s not some big revelation, or even anything that’s new; peer-to-peer messaging, or at least the guise of “private” messaging, is as old as the consumer internet itself. When our worlds expand in a way that feels unmanageable, our instinct is sometimes to shrink them until we’re comfortable again, for better or worse. Remember Path, the social network limited to just your closest circle? That didn’t work out, but the entire app was built upon the Dunbar theory that our species can’t handle more than 150 close friends. There just might have been something to that.
“I think a lot of people experience this,” says Margaret Morris, a clinical psychologist and author of Left to Our Own Devices. “When you post something in such a public way, the question is: What are the motivations? But when it’s in a private thread, it’s: Why am I sharing this? Oh, it’s because I think you’ll like this. I think we’ll connect over this. The altruistic motivations can be far more clear in private messaging.”
Of course, “altruism” in this case only applies to the friends exchanging messages and not the messaging service providers. Facebook’s efforts to unify its messaging platforms are at least partly rooted in a desire to monetize our activity, whether that’s by keeping us engaged in an outward-facing News Feed or within a little chat box. And there’s a major distinction between so-called private messages and what Morris calls “Privacy with a capital P.”
“There’s one kind of privacy, which is: what does my cousin know, or what does my co-worker know,” Morris says, “And then there’s the kind of privacy that’s about the data Facebook has.” Facebook’s plan is reportedly to offer end-to-end encryption on all of its messaging apps once the backend systems have been merged. As my WIRED colleague Lily Newman writes, cryptographers and privacy advocates already see obvious hurdles in making this work.
That’s why I often use Apple’s Messages and even iCloud photo sharing. There’s an explicit agreement that exists between the service provider and user: Buy our ridiculously expensive hardware, and we won’t sell your data. (While iCloud has been hacked before, Apple swears by the end-to-end encryption between iPhone users and says it doesn’t share Messages data with third-party apps). But just using Messages isn’t realistic, either. The platform is only functional between two iPhones. Not everyone can afford Apple products, and in other parts of the world, such as China or India, apps like WeChat and WhatsApp dominate private messaging. That means you’re going to end up using other apps if you plan to communicate outside of a bubble of iPhone lovers.
But beyond privacy with a capital P—which is, for many people, the most important consideration when it comes to social media—there’s the psychology of privacy when it comes to sharing updates about our personal lives, and connecting with other humans. Social networks have made human connections infinitely more possible and also turned the whole notion upside down on its head.
Morris, for example, sees posting something publicly to a Facebook feed as a yearning for interconnectedness, while a private messaging thread is a quest for what she calls attunement, a way to strengthen a bond between two people. But, she notes, some people take a screenshot from a private message and then, having failed in their quest for attunement, publish an identity-stripped version of it to their feed. Guilty as charged. Social networking is no longer just a feed or an app or a chat box or SMS, but some amalgamation of it all.
Posting private messages publicly is not something I plan to make a habit of, but there is still the urge sometimes to share. I’m still on Twitter. I’ll likely still post to Facebook and Instagram from time to time. At some point I may be looking for a sense of community that exists beyond my own small private messaging groups, for a tantalizing blend of familiarity and anonymity in a Facebook group of like-minded hobbyists. For some people, larger social networking communities are lifelines as they struggle with health, with family, with job worries, with life.
But right now, “private” messages are the way to share my life with the people who matter most, an attempt to splinter off my social interactions into something more satisfying—especially when posting to Facebook has never seemed less appealing.
By now, everyone with an email address has seen a slew of emails announcing privacy policy updates. You have Europe’s GDPR legislation to thank for your overcrowded inbox. GDPR creates rules around how much data companies are allowed to collect, how they’re able to use that data, and how clear they have to be with consumers about it all.
Companies around the world are scrambling to get their business and its practices into compliance – a significant task for many of them. While technically, the deadline to get everything in order passed on May 25, for many companies the process will continue well into June and possibly beyond. Some companies are even shutting down in Europe for good, or for as long as it takes them to get in compliance.
Even with the deadline behind us, the GDPR continues to be a top story for the tech world and may remain so for some time to come.
2. Amazon Provides Facial Recognition Tech to Law Enforcement
Civil rights groups have called for the company to stop allowing law enforcement access to the tech out of concerns that increased government surveillance can pose a threat to vulnerable communities in the country. In spite of the public criticism, Amazon hasn’t backed off on providing the tech to authorities, at least as of this time.
3. Apple Looks Into Self-Driving Employee Shuttles
Of the many problems facing our world, the frustrating work commute is one that many of the brightest minds in tech deal with just like the rest of us. Which makes it a problem the biggest tech companies have a strong incentive to try to solve.
Apple is one of many companies that’s invested in developing self-driving cars as a possible solution, but while that goal is still (probably) years away, they’ve narrowed their focus to teaming up with VW to create self-driving shuttles just for their employees. Even that project is moving slower than the company had hoped, but they’re aiming to have some shuttles ready by the end of the year.
4. Court Weighs in on President’s Tendency to Block Critics on Twitter
Three years ago no one would have imagined that Twitter would be a president’s go-to source for making announcements, but today it’s used to that effect more frequently than official press conferences or briefings.
In a court battle that may sound surreal to many of us, a judge just found that the president can no longer legally block other users on Twitter. The court asserted that blocking users on a public forum like Twitter amounts to a violation of their First Amendment rights. The judgment does still allow for the president and other public officials to mute users they don’t agree with, though.
5. YouTube Launches Music Streaming Service
YouTube joined the ranks of Spotify, Pandora, and Amazon this past month with their own streaming music service. Consumers can use a free version of the service that includes ads, or can pay $9.99 for the ad-free version.
With so many similar services already on the market, people weren’t exactly clamoring for another music streaming option. But since YouTube is likely to remain the reigning source for videos, it doesn’t necessarily need to unseat Spotify to still be okay. And with access to Google’s extensive user data, it may be able to provide more useful recommendations than its main competitors in the space, which is one way the service could differentiate itself.
6. Facebook Institutes Political Ad Rules
Facebook hasn’t yet left behind the controversies of the last election. The company is still working to proactively respond to criticism of its role in the spread of political propaganda many believe influenced election results. One of the solutions they’re trying is a new set of rules for any political ads run on the platform.
Any campaign that intends to run Facebook ads is now required to verify their identity with a card Facebook mails to their address that has a verification code. While Facebook has been promoting these new rules for a few weeks to politicians active on the platform, some felt blindsided when they realized, right before their primaries no less, that they could no longer place ads without waiting 12 to 15 days for a verification code to come in the mail. Politicians in this position blame the company for making a change that could affect their chances in the upcoming election.
Even in their efforts to avoid swaying elections, Facebook has found themselves criticized for doing just that. They’re probably feeling at this point like they just can’t win.
7. Another Big Month for Tech IPOs
This year has seen one tech IPO after another and this month is no different. Chinese smartphone company Xiaomi has a particularly large IPO in the works. The company seeks to join the Hong Kong stock exchange on June 7 with an initial public offering that experts anticipate could reach $10 billion.
The online lending platform Greensky started trading on the New York Stock Exchange on May 23 and sold 38 million shares in its first day, 4 million more than expected. This month continues 2018’s trend of tech companies going public, largely to great success.
8. StumbleUpon Shuts Down
In the internet’s ongoing evolution, there will always be tech companies that win and those that fall by the wayside. StumbleUpon, a content discovery platform that had its heyday in the early aughts, is officially shutting down on June 30.
Since its 2002 launch, the service has helped over 40 million users “stumble upon” 60 billion new websites and pieces of content. The company behind StumbleUpon plans to create a new platform that serves a similar purpose that may be more useful to former StumbleUpon users called Mix.
9. Uber and Lyft Invest in Driver Benefits
In spite of their ongoing success, the popular ridesharing platforms Uber and Lyft have faced their share of criticism since they came onto the scene. One of the common complaints critics have made is that the companies don’t provide proper benefits to their drivers. And in fact, the companies have fought to keep drivers classified legally as contractors so they’re off the hook for covering the cost of employee taxes and benefits.
Recently both companies have taken steps to make driving for them a little more attractive. Uber has begun offering Partner Protection to its drivers in Europe, which includes health insurance, sick pay, and parental leave – so far nothing similar in the U.S. though. For its part, Lyft is investing $100 million in building driver support centers where their drivers can stop to get discounted car maintenance, tax help, and customer support help in person from Lyft staff. It’s not the same as getting full employee benefits (in the U.S. at least), but it’s something.
Cambridge Analytica may have usedFacebook’s data to influence your political opinions. But why does least-liked tech company Facebook have all this data about its users in the first place?
Let’s put aside Instagram, WhatsApp and other Facebook products for a minute. Facebook has built the world’s biggest social network. But that’s not what they sell. You’ve probably heard the internet saying “if a product is free, it means that you are the product.”
And it’s particularly true in this case because Facebook is the world’s second biggest advertising company in the world behind Google. During the last quarter of 2017, Facebook reported $12.97 billion in revenue, including $12.78 billion from ads.
That’s 98.5 percent of Facebook’s revenue coming from ads.
Ads aren’t necessarily a bad thing. But Facebook has reached ad saturation in the newsfeed. So the company has two options — creating new products and ad formats, or optimizing those sponsored posts.
Facebook has reached ad saturation in the newsfeed
This isn’t a zero-sum game — Facebook has been doing both at the same time. That’s why you’re seeing more ads on Instagram and Messenger. And that’s also why ads on Facebook seem more relevant than ever.
If Facebook can show you relevant ads and you end up clicking more often on those ads, then advertisers will pay Facebook more money.
So Facebook has been collecting as much personal data about you as possible — it’s all about showing you the best ad. The company knows your interests, what you buy, where you go and who you’re sleeping with.
You can’t hide from Facebook
Facebook’s terms and conditions are a giant lie. They are purposely misleading, too long and too broad. So you can’t just read the company’s terms of service and understand what it knows about you.
That’s why some people have been downloading their Facebook data. You can do it too, it’s quite easy. Just head over to your Facebook settings and click the tiny link that says “Download a copy of your Facebook data.”
In that archive file, you’ll find your photos, your posts, your events, etc. But if you keep digging, you’ll also find your private messages on Messenger (by default, nothing is encrypted).
And if you keep digging a bit more, chances are you’ll also find your entire address book and even metadata about your SMS messages and phone calls.
All of this is by design and you agreed to it. Facebook has unified terms of service and share user data across all its apps and services (except WhatsApp data in Europe for now). So if you follow a clothing brand on Instagram, you could see an ad from this brand on Facebook.com.
Messaging apps are privacy traps
But Facebook has also been using this trick quite a lot with Messenger. You might not remember, but the on-boarding experience on Messenger is really aggressive.
On iOS, the app shows you a fake permission popup to access your address book that says “Ok” or “Learn More”. The company is using a fake popup because you can’t ask for permission twice.
There’s a blinking arrow below the OK button.
If you click on “Learn More”, you get a giant blue button that says “Turn On”. Everything about this screen is misleading and Messenger tries to manipulate your emotions.
“Messenger only works when you have people to talk to,” it says. Nobody wants to be lonely, that’s why Facebook implies that turning on this option will give you friends.
Even worse, it says “if you skip this step, you’ll need to add each contact one-by-one to message them.” This is simply a lie as you can automatically talk to your Facebook friends using Messenger without adding them one-by-one.
The next time you pay for a burrito with your credit card, Facebook will learn about this transaction and match this credit card number with the one you added in Messenger
If you tap on “Not Now”, Messenger will show you a fake notification every now and then to push you to enable contact syncing. If you tap on yes and disable it later, Facebook still keeps all your contacts on its servers.
On Android, you can let Messenger manage your SMS messages. Of course, you guessed it, Facebook uploads all your metadata. Facebook knows who you’re texting, when, how often.
Even if you disable it later, Facebook will keep this data for later reference.
But Facebook doesn’t stop there. The company knows a lot more about you than what you can find in your downloaded archive. The company asks you to share your location with your friends. The company tracks your web history on nearly every website on earth using embedded JavaScript.
But my favorite thing is probably peer-to-peer payments. In some countries, you can pay back your friends using Messenger. It’s free! You just have to add your card to the app.
It turns out that Facebook also buys data about your offline purchases. The next time you pay for a burrito with your credit card, Facebook will learn about this transaction and match this credit card number with the one you added in Messenger.
In other words, Messenger is a great Trojan horse designed to learn everything about you.
And the next time an app asks you to share your address book, there’s a 99-percent chance that this app is going to mine your address book to get new users, spam your friends, improve ad targeting and sell email addresses to marketing companies.
I could say the same thing about all the other permission popups on your phone. Be careful when you install an app from the Play Store or open an app for the first time on iOS. It’s easier to enable something if a feature doesn’t work without it than to find out that Facebook knows everything about you.
GDPR to the rescue
There’s one last hope. And that hope is GDPR. I encourage you to read TechCrunch’s Natasha Lomas excellent explanation of GDPR to understand what the European regulation is all about.
Many of the misleading things that are currently happening at Facebook will have to change. You can’t force people to opt in like in Messenger. Data collection should be minimized to essential features. And Facebook will have to explain why it needs all this data to its users.
If Facebook doesn’t comply, the company will have to pay up to 4 percent of its global annual turnover. But that doesn’t stop you from actively reclaiming your online privacy right now.
You can’t be invisible on the internet, but you have to be conscious about what’s happening behind your back. Every time a company asks you to tap OK, think about what’s behind this popup. You can’t say that nobody told you.
European Union lawmakers proposed a comprehensive update to the bloc’s data protection and privacy rules in 2012.
Their aim: To take account of seismic shifts in the handling of information wrought by the rise of the digital economy in the years since the prior regime was penned — all the way back in 1995 when Yahoo was the cutting edge of online cool and cookies were still just tasty biscuits.
Here’s the EU’s executive body, the Commission, summing up the goal:
The objective of this new set of rules is to give citizens back control over of their personal data, and to simplify the regulatory environment for business. The data protection reform is a key enabler of the Digital Single Market which the Commission has prioritised. The reform will allow European citizens and businesses to fully benefit from the digital economy.
For an even shorter the EC’s theory is that consumer trust is essential to fostering growth in the digital economy. And it thinks trust can be won by giving users of digital services more information and greater control over how their data is used. Which is — frankly speaking — a pretty refreshing idea when you consider the clandestine data brokering that pervades the tech industry. Mass surveillance isn’t just something governments do.
It’s set to apply across the 28-Member State bloc as of May 25, 2018. That means EU countries are busy transposing it into national law via their own legislative updates (such as the UK’s new Data Protection Bill — yes, despite the fact the country is currently in the process of (br)exiting the EU, the government has nonetheless committed to implementing the regulation because it needs to keep EU-UK data flowing freely in the post-brexit future. Which gives an early indication of the pulling power of GDPR.
Meanwhile businesses operating in the EU are being bombarded with ads from a freshly energized cottage industry of ‘privacy consultants’ offering to help them get ready for the new regs — in exchange for a service fee. It’s definitely a good time to be a law firm specializing in data protection.
GDPR is a significant piece of legislation whose full impact will clearly take some time to shake out. In the meanwhile, here’s our guide to the major changes incoming and some potential impacts.
Data protection + teeth
A major point of note right off the bat is that GDPR does not merely apply to EU businesses; any entities processing the personal data of EU citizens need to comply. Facebook, for example — a US company that handles massive amounts of Europeans’ personal data — is going to have to rework multiple business processes to comply with the new rules. Indeed, it’s been working on this for a long time already.
Last year the company told us it had assembled “the largest cross functional team” in the history of its family of companies to support GDPR compliance — specifying this included “senior executives from all product teams, designers and user experience/testing executives, policy executives, legal executives and executives from each of the Facebook family of companies”.
“Dozens of people at Facebook Ireland are working full time on this effort,” it said, noting too that the data protection team at its European HQ (in Dublin, Ireland) would be growing by 250% in 2017. It also said it was in the process of hiring a “top quality data protection officer” — a position the company appears to still be taking applications for.
The new EU rules require organizations to appoint a data protection officer if they process sensitive data on a large scale (which Facebook very clearly does). Or are collecting info on many consumers — such as by performing online behavioral tracking. But, really, which online businesses aren’t doing that these days?
The extra-territorial scope of GDPR casts the European Union as a global pioneer in data protection — and some legal experts suggest the regulation will force privacy standards to rise outside the EU too.
Sure, some US companies might prefer to swallow the hassle and expense of fragmenting their data handling processes, and treating personal data obtained from different geographies differently, i.e. rather than streamlining everything under a GDPR compliant process. But doing so means managing multiple data regimes. And at very least runs the risk of bad PR if you’re outed as deliberately offering a lower privacy standard to your home users vs customers abroad.
Ultimately, it may be easier (and less risky) for businesses to treat GDPR as the new ‘gold standard’ for how they handle all personal data, regardless of where it comes from.
And while not every company harvests Facebook levels of personal data, almost every company harvests some personal data. So for those with customers in the EU GDPR cannot be ignored. At very least businesses will need to carry out a data audit to understand their risks and liabilities.
Privacy experts suggest that the really big change here is around enforcement. Because while the EU has had long established data protection standards and rules — and treats privacy as a fundamental right — its regulators have lacked the teeth to command compliance.
But now, under GDPR, financial penalties for data protection violations step up massively.
The maximum fine that organizations can be hit with for the most serious infringements of the regulation is 4% of their global annual turnover (or €20M, whichever is greater). Though data protection agencies will of course be able to impose smaller fines too. And, indeed, there’s a tiered system of fines — with a lower level of penalties of up to 2% of global turnover (or €10M).
This really is a massive change. Because while data protection agencies (DPAs) in different EU Member States can impose financial penalties for breaches of existing data laws these fines are relatively small — especially set against the revenues of the private sector entities that are getting sanctioned.
In the UK, for example, the Information Commissioner’s Office (ICO) can currently impose a maximum fine of just £500,000. Compare that to the annual revenue of tech giant Google (~$90BN) and you can see why a much larger stick is needed to police data processors.
It’s not necessarily the case that individual EU Member States are getting stronger privacy laws as a consequence of GDPR (in some instances countries have arguably had higher standards in their domestic law). But the beefing up of enforcement that’s baked into the new regime means there’s a better opportunity for DPAs to start to bark and bite like proper watchdogs.
GDPR inflating the financial risks around handling personal data should naturally drive up standards — because privacy laws are suddenly a whole lot more costly to ignore.
More types of personal data that are hot to handle
So what is personal data under GDPR? It’s any information relating to an identified or identifiable person (in regulatorspeak people are known as ‘data subjects’).
While ‘processing’ can mean any operation performed on personal data — from storing it to structuring it to feeding it to your AI models. (GDPR also includes some provisions specifically related to decisions generated as a result of automated data processing but more on that below).
A new provision concerns children’s personal data — with the regulation setting a 16-year-old age limit on kids’ ability to consent to their data being processed. However individual Member States can choose (and some have) to derogate from this by writing a lower age limit into their laws.
GDPR sets a hard cap at 13-years-old — making that the defacto standard for children to be able to sign up to digital services. So the impact on teens’ social media habits seems likely to be relatively limited.
The new rules generally expand the definition of personal data — so it can include information such as location data, online identifiers (such as IP addresses) and other metadata. So again, this means businesses really need to conduct an audit to identify all the types of personal data they hold. Ignorance is not compliance.
GDPR also encourages the use of pseudonymization — such as, for example, encrypting personal data and storing the encryption key separately and securely — as a pro-privacy, pro-security technique that can help minimize the risks of processing personal data. Although pseudonymized data is likely to still be considered personal data; certainly where a risk of reidentification remains. So it does not get a general pass from requirements under the regulation.
Data has to be rendered truly anonymous to be outside the scope of the regulation. (And given how often ‘anonymized’ data-sets have been shown to be re-identifiable, relying on any anonymizing process to be robust enough to have zero risk of re-identification seems, well, risky.)
To be clear, given GDPR’s running emphasis on data protection via data security it is implicitly encouraging the use of encryption above and beyond a risk reduction technique — i.e. as a way for data controllers to fulfill its wider requirements to use “appropriate technical and organisational measures” vs the risk of the personal data they are processing.
The incoming data protection rules apply to both data controllers (i.e. entities that determine the purpose and means of processing personal data) and data processors (entities that are responsible for processing data on behalf of a data controller — aka subcontractors).
Indeed, data processors have some direct compliance obligations under GDPR, and can also be held equally responsible for data violations, with individuals able to bring compensation claims directly against them, and DPAs able to hand them fines or other sanctions.
So the intent for the regulation is there be no diminishing in responsibility down the chain of data handling subcontractors. GDPR aims to have every link in the processing chain be a robust one.
For companies that rely on a lot of subcontractors to handle data operations on their behalf there’s clearly a lot of risk assessment work to be done.
As noted above, there is a degree of leeway for EU Member States in how they implement some parts of the regulation (such as with the age of data consent for kids).
Consumer protection groups are calling for the UK government to include an optional GDPR provision on collective data redress to its DP bill, for example — a call the government has so far rebuffed.
But the wider aim is for the regulation to harmonize as much as possible data protection rules across all Member States to reduce the regulatory burden on digital businesses trading around the bloc.
On data redress, European privacy campaigner Max Schrems — most famous for his legal challenge to US government mass surveillance practices that resulted in a 15-year-old data transfer arrangement between the EU and US being struck down in 2015 — is currently running a crowdfunding campaign to set up a not-for-profit privacy enforcement organization to take advantage of the new rules and pursue strategic litigation on commercial privacy issues.
Schrems argues it’s simply not viable for individuals to take big tech giants to court to try to enforce their privacy rights, so thinks there’s a gap in the regulatory landscape for an expert organization to work on EU citizen’s behalf. Not just pursuing strategic litigation in the public interest but also promoting industry best practice.
The proposed data redress body — called noyb; short for: ‘none of your business’ — is being made possible because GDPR allows for collective enforcement of individuals’ data rights. And that provision could be crucial in spinning up a centre of enforcement gravity around the law. Because despite the position and role of DPAs being strengthened by GDPR, these bodies will still inevitably have limited resources vs the scope of the oversight task at hand.
Some may also lack the appetite to take on a fully fanged watchdog role. So campaigning consumer and privacy groups could certainly help pick up any slack.
Privacy by design and privacy by default
Another major change incoming via GDPR is ‘privacy by design’ no longer being just a nice idea; privacy by design and privacy by default become firm legal requirements.
This means there’s a requirement on data controllers to minimize processing of personal data — limiting activity to only what’s necessary for a specific purpose, carrying out privacy impact assessments and maintaining up-to-date records to prove out their compliance.
Consent requirements for processing personal data are also considerably strengthened under GDPR — meaning lengthy, inscrutable, pre-ticked T&Cs are likely to be unworkable. (And we’ve sure seen a whole lot of those hellish things in tech.) The core idea is that consent should be an ongoing, actively managed process; not a one-off rights grab.
As the UK’s ICO tells it, consent under GDPR for processing personal data means offering individuals “genuine choice and control” (for sensitive personal data the law requires a higher standard still — of explicit consent).
There are other legal bases for processing personal data under GDPR — such as contractual necessity; or compliance with a legal obligation under EU or Member State law; or for tasks carried out in the public interest — so it is not necessary to obtain consent in order to process someone’s personal data. But there must always be an appropriate legal basis for each processing.
Transparency is another major obligation under GDPR, which expands the notion that personal data must be lawfully and fairly processed to include a third principle of accountability. Hence the emphasis on data controllers needing to clearly communicate with data subjects — such as by informing them of the specific purpose of the data processing.
The obligation on data handlers to maintain scrupulous records of what information they hold, what they are doing with it, and how they are legally processing it, is also about being able to demonstrate compliance with GDPR’s data processing principles.
But — on the plus side for data controllers — GDPR removes the requirement to submit notifications to local DPAs about data processing activities. Instead, organizations must maintain detailed internal records — which a supervisory authority can always ask to see.
It’s also worth noting that companies processing data across borders in the EU may face scrutiny from DPAs in different Member States if they have users there (and are processing their personal data).
Although the GDPR sets out a so-called ‘one-stop-shop’ principle — that there should be a “lead” DPA to co-ordinate supervision between any “concerned” DPAs — this does not mean that, once it applies, a cross-EU-border operator like Facebook is only going to be answerable to the concerns of the Irish DPA.
Indeed, Facebook’s tactic of only claiming to be under the jurisdiction of a single EU DPA looks to be on borrowed time. And the one-stop-shop provision in the GDPR seems more about creating a co-operation mechanism to allow multiple DPAs to work together in instances where they have joint concerns, rather than offering a way for multinationals to go ‘forum shopping’ — which the regulation does not permit (per WP29 guidance).
Another change: Privacy policies that contain vague phrases like ‘We may use your personal data to develop new services’ or ‘We may use your personal data for research purposes’ will not pass muster under the new regime. So a wholesale rewriting of vague and/or confusingly worded T&Cs is something Europeans can look forward to this year.
Add to that, any changes to privacy policies must be clearly communicated to the user on an ongoing basis. Which means no more stale references in the privacy statement telling users to ‘regularly check for changes or updates’ — that just won’t be workable.
The onus is firmly on the data controller to keep the data subject fully informed of what is being done with their information. (Which almost implies that good data protection practice could end up tasting a bit like spam, from a user PoV.)
The overall intent behind GDPR is to inculcate an industry-wide shift in perspective regarding who ‘owns’ user data — disabusing companies of the notion that other people’s personal information belongs to them just because it happens to be sitting on their servers.
“Organizations should acknowledge they don’t exist to process personal data but they process personal data to do business,” is how analyst Gartner research director Bart Willemsen sums this up. “Where there is a reason to process the data, there is no problem. Where the reason ends, the processing should, too.”
The data protection officer (DPO) role that GDPR brings in as a requirement for many data handlers is intended to help them ensure compliance.
This officer, who must report to the highest level of management, is intended to operate independently within the organization, with warnings to avoid an internal appointment that could generate a conflict of interests.
Which types of organizations face the greatest liability risks under GDPR? “Those who deliberately seem to think privacy protection rights is inferior to business interest,” says Willemsen, adding: “A recent example would be Uber, regulated by the FTC and sanctioned to undergo 20 years of auditing. That may hurt perhaps similar, or even more, than a one-time financial sanction.”
“Eventually, the GDPR is like a speed limit: There not to make money off of those who speed, but to prevent people from speeding excessively as that prevents (privacy) accidents from happening,” he adds.
Another right to be forgotten
Under GDPR, people who have consented to their personal data being processed also have a suite of associated rights — including the right to access data held about them (a copy of the data must be provided to them free of charge, typically within a month of a request); the right to request rectification of incomplete or inaccurate personal data; the right to have their data deleted (another so-called ‘right to be forgotten’ — with some exemptions, such as for exercising freedom of expression and freedom of information); the right to restrict processing; the right to data portability (where relevant, a data subject’s personal data must be provided free of charge and in a structured, commonly used and machine readable form).
All these rights make it essential for organizations that process personal data to have systems in place which enable them to identify, access, edit and delete individual user data — and be able to perform these operations quickly, with a general 30 day time-limit for responding to individual rights requests.
GDPR also gives people who have consented to their data being processed the right to withdraw consent at any time. Let that one sink in.
Data controllers are also required to inform users about this right — and offer easy ways for them to withdraw consent. So no, you can’t bury a ‘revoke consent’ option in tiny lettering, five sub-menus deep. Nor can WhatsApp offer any more time-limit opt-outs for sharing user data with its parent multinational, Facebook. Users will have the right to change their mind whenever they like.
The EU lawmakers’ hope is that this suite of rights for consenting consumers will encourage respectful use of their data — given that, well, if you annoy consumers they can just tell you to sling yer hook and ask for a copy of their data to plug into your rival service to boot. So we’re back to that fostering trust idea.
Add in the ability for third party organizations to use GDPR’s provision for collective enforcement of individual data rights and there’s potential for bad actors and bad practice to become the target for some creative PR stunts that harness the power of collective action — like, say, a sudden flood of requests for a company to delete user data.
Data rights and privacy issues are certainly going to be in the news a whole lot more.
Getting serious about data breaches
But wait, there’s more! Another major change under GDPR relates to security incidents — aka data breaches (something else we’ve seen an awful, awful lot of in recent years) — with the regulation doing what the US still hasn’t been able to: Bringing in a universal standard for data breach disclosures.
GDPR requires that data controllers report any security incidents where personal data has been lost, stolen or otherwise accessed by unauthorized third parties to their DPA within 72 hours of them becoming aware of it. Yes, 72 hours. Not the best part of a year, like er Uber.
If a data breach is likely to result in a “high risk of adversely affecting individuals’ rights and freedoms” the regulation also implies you should ‘fess up even sooner than that — without “undue delay”.
Only in instances where a data controller assesses that a breach is unlikely to result in a risk to the rights and freedoms of “natural persons” are they exempt from the breach disclosure requirement (though they still need to document the incident internally, and record their reason for not informing a DPA in a document that DPAs can always ask to see).
“You should ensure you have robust breach detection, investigation and internal reporting procedures in place,” is the ICO’s guidance on this. “This will facilitate decision-making about whether or not you need to notify the relevant supervisory authority and the affected individuals.”
The new rules generally put strong emphasis on data security and on the need for data controllers to ensure that personal data is only processed in a manner that ensures it is safeguarded.
Here again, GDPR’s requirements are backed up by the risk of supersized fines. So suddenly sloppy security could cost your business big — not only in reputation terms, as now, but on the bottom line too. So it really must be a C-suite concern going forward.
Nor is subcontracting a way to shirk your data security obligations. Quite the opposite. Having a written contract in place between a data controller and a data processor was a requirement before GDPR but contract requirements are wider now and there are some specific terms that must be included in the contract, as a minimum.
Breach reporting requirements must also be set out in the contract between processor and controller. If a data controller is using a data processor and it’s the processor that suffers a breach, they’re required to inform the controller as soon as they become aware. The controller then has the same disclosure obligations as per usual.
Essentially, data controllers remain liable for their own compliance with GDPR. And the ICO warns they must only appoint processors who can provide “sufficient guarantees” that the regulatory requirements will be met and the rights of data subjects protected.
tl;dr, be careful who and how you subcontract.
Right to human review for some AI decisions
Article 22 of GDPR places certain restrictions on entirely automated decisions based on profiling individuals — but only in instances where these human-less acts have a legal or similarly significant effect on the people involved.
There are also some exemptions to the restrictions — where automated processing is necessary for entering into (or performance of) a contract between an organization and the individual; or where it’s authorized by law (e.g. for the purposes of detecting fraud or tax evasion); or where an individual has explicitly consented to the processing.
In its guidance, the ICO specifies that the restriction only applies where the decision has a “serious negative impact on an individual”.
Suggested examples of the types of AI-only decisions that will face restrictions are automatic refusal of an online credit application or an e-recruiting practices without human intervention.
Having a provision on automated decisions is not a new right, having been brought over from the 1995 data protection directive. But it has attracted fresh attention — given the rampant rise of machine learning technology — as a potential route for GDPR to place a check on the power of AI blackboxes to determine the trajectory of humankind.
The real-world impact will probably be rather more prosaic, though. And experts suggest it does not seem likely that the regulation, as drafted, equates to a right for people to be given detailed explanations of how algorithms work.
Though as AI proliferates and touches more and more decisions, and as its impacts on people and society become ever more evident, pressure may well grow for proper regulatory oversight of algorithmic blackboxes.
In the meanwhile, what GDPR does in instances where restrictions apply to automated decisions is require data controllers to provide some information to individuals about the logic of an automated decision.
They are also obliged to take steps to prevent errors, bias and discrimination. So there’s a whiff of algorithmic accountability. Though it may well take court and regulatory judgements to determine how stiff those steps need to be in practice.
Individuals do also have a right to challenge and request a (human) review of an automated decision in the restricted class.
Here again the intention is to help people understand how their data is being used. And to offer a degree of protection (in the form of a manual review) if a person feels unfairly and harmfully judged by an AI process.
The regulation also places some restrictions on the practice of using data to profile individuals if the data itself is sensitive data — e.g. health data, political belief, religious affiliation etc — requiring explicit consent for doing so. Or else that the processing is necessary for substantial public interest reasons (and lies within EU or Member State law).
While profiling based on other types of personal data does not require obtaining consent from the individuals concerned, it still needs a legal basis and there is still a transparency requirement — which means service providers will need to inform users they are being profiled, and explain what it means for them.
And people also always have the right to object to profiling activity based on their personal data.









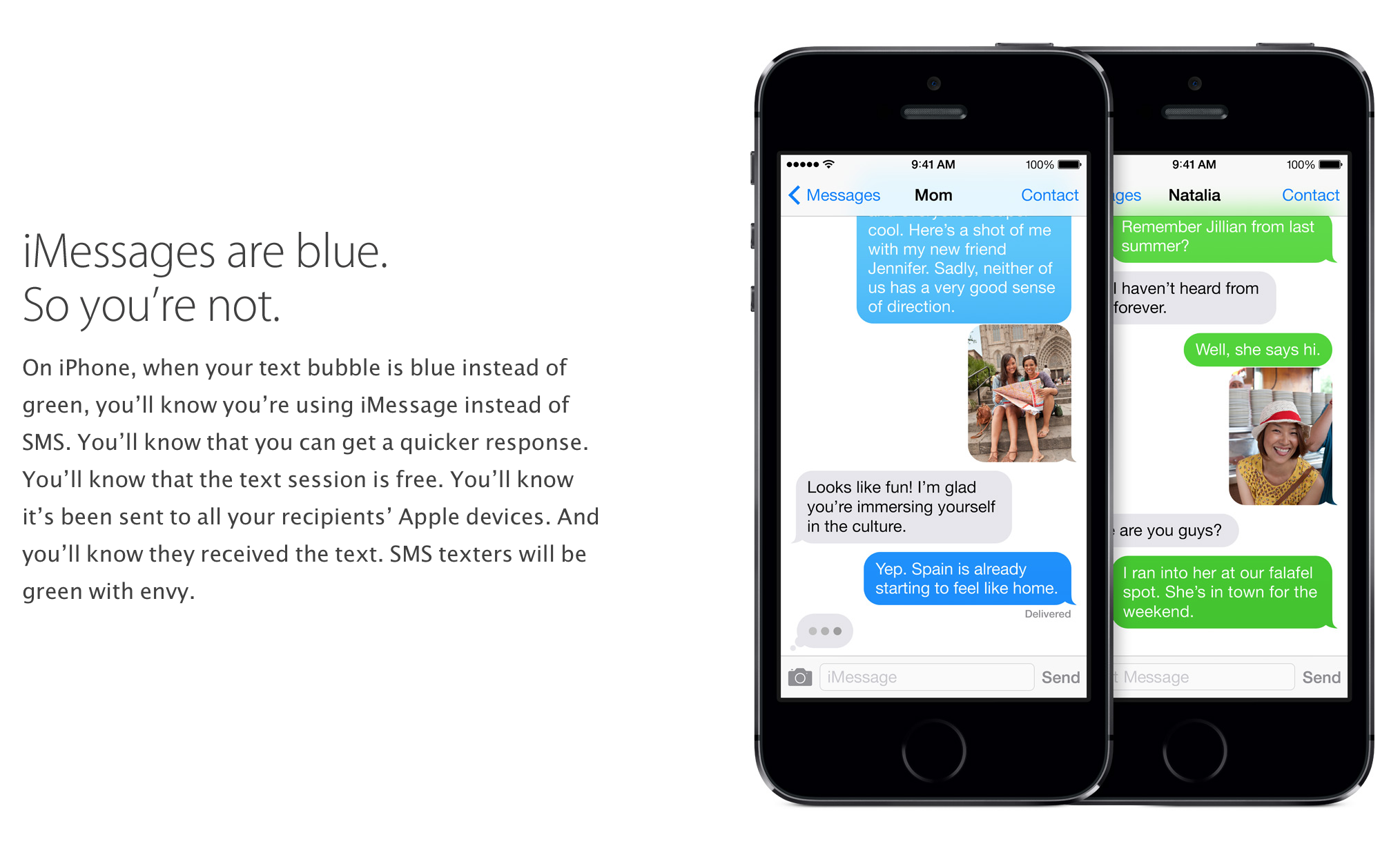

 When Adele Lowitz, left, experimented with using an Android smartphone instead of an iPhone, one friend asked: ‘Who’s green?’ PHOTO: STEVE KOSS FOR THE WALL STREET JOURNAL
When Adele Lowitz, left, experimented with using an Android smartphone instead of an iPhone, one friend asked: ‘Who’s green?’ PHOTO: STEVE KOSS FOR THE WALL STREET JOURNAL How Apple’s iPhone and Apps Trap You in a Walled GardenApple’s hardware, software and services work so harmoniously that it is often called a “walled garden.” The idea is central to recent antitrust scrutiny and the Epic vs. Apple case. WSJ’s Joanna Stern went to a real walled garden to explain it all. Photo illustration: Adele Morgan/The Wall Street Journal
How Apple’s iPhone and Apps Trap You in a Walled GardenApple’s hardware, software and services work so harmoniously that it is often called a “walled garden.” The idea is central to recent antitrust scrutiny and the Epic vs. Apple case. WSJ’s Joanna Stern went to a real walled garden to explain it all. Photo illustration: Adele Morgan/The Wall Street Journal




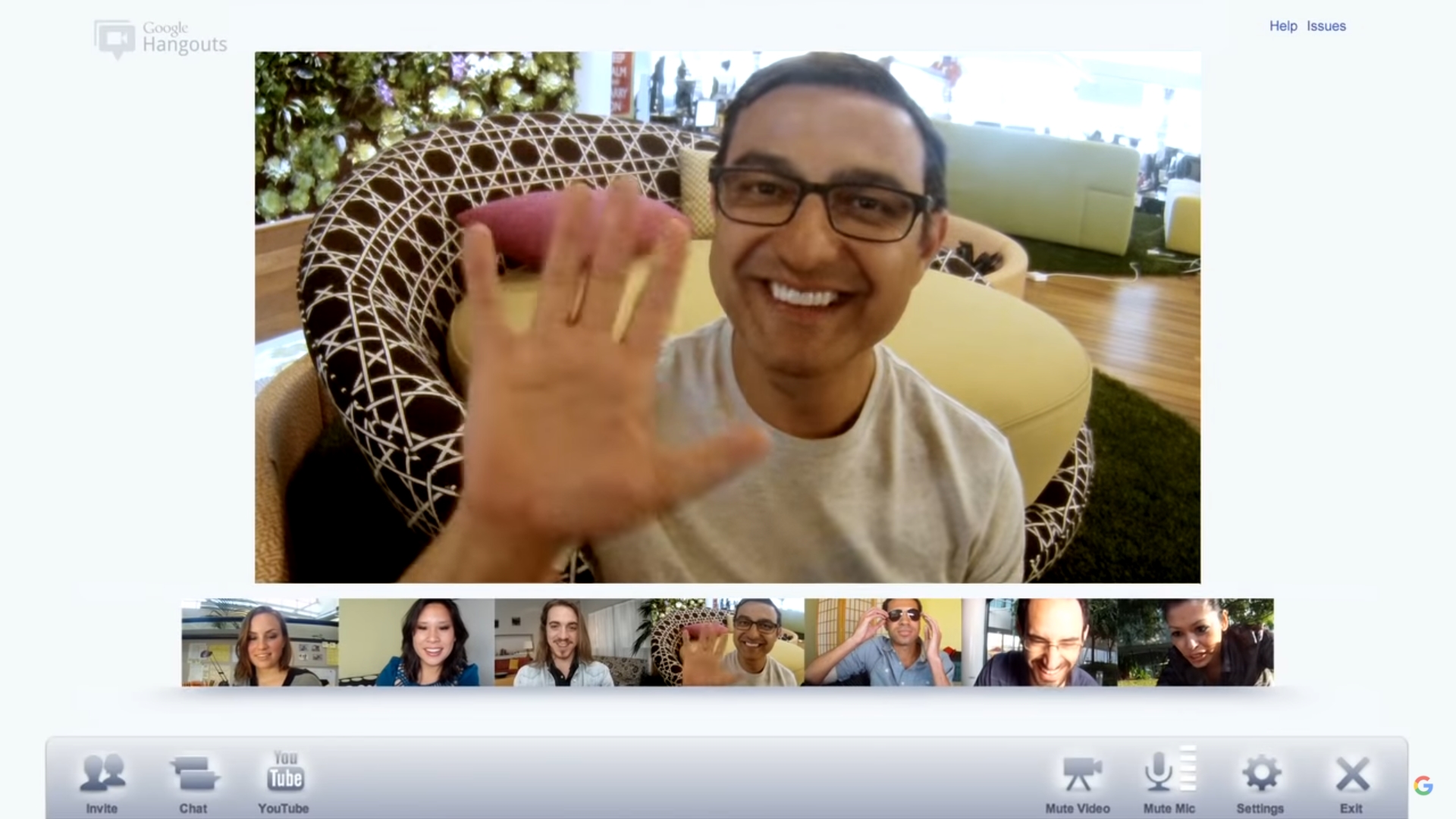


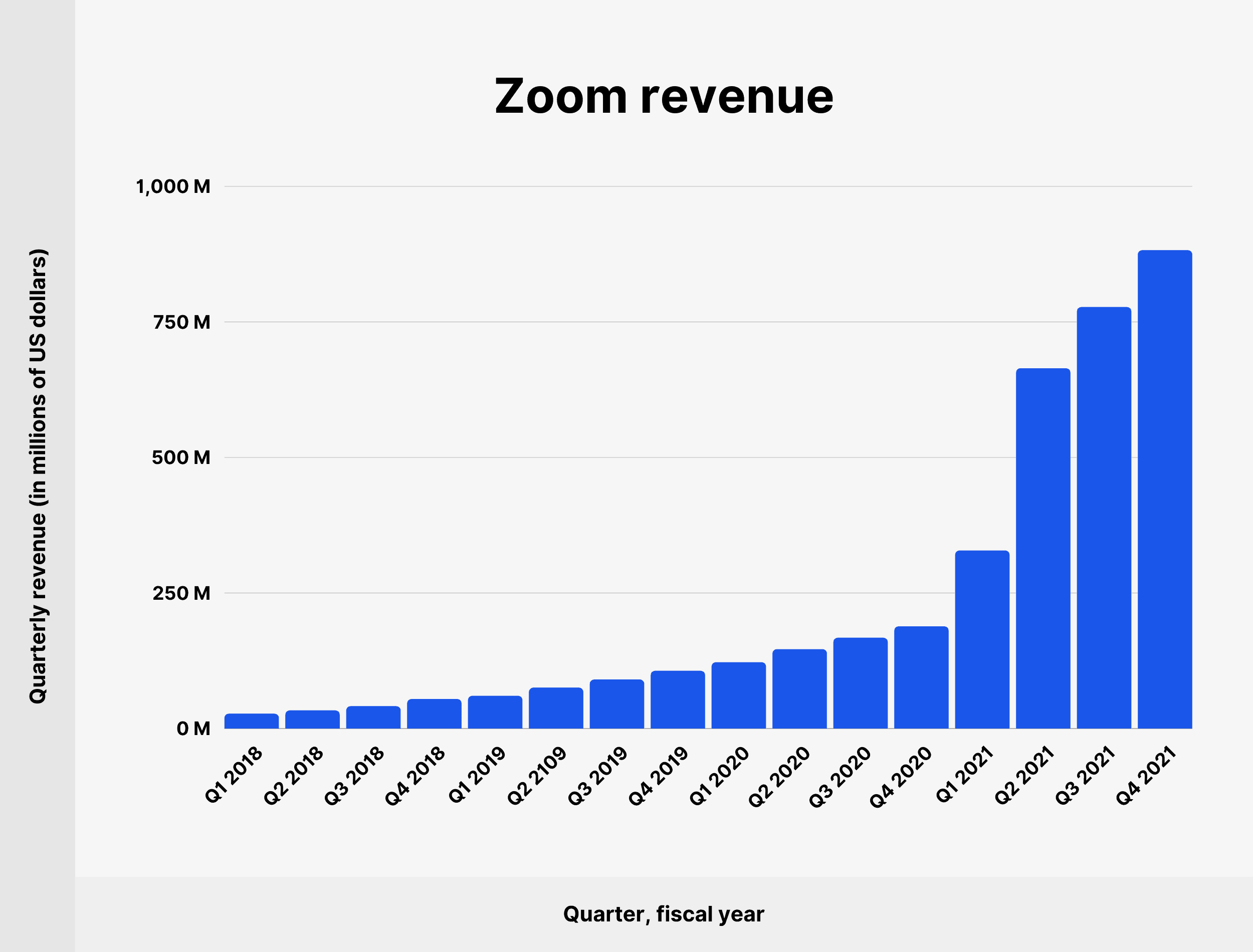










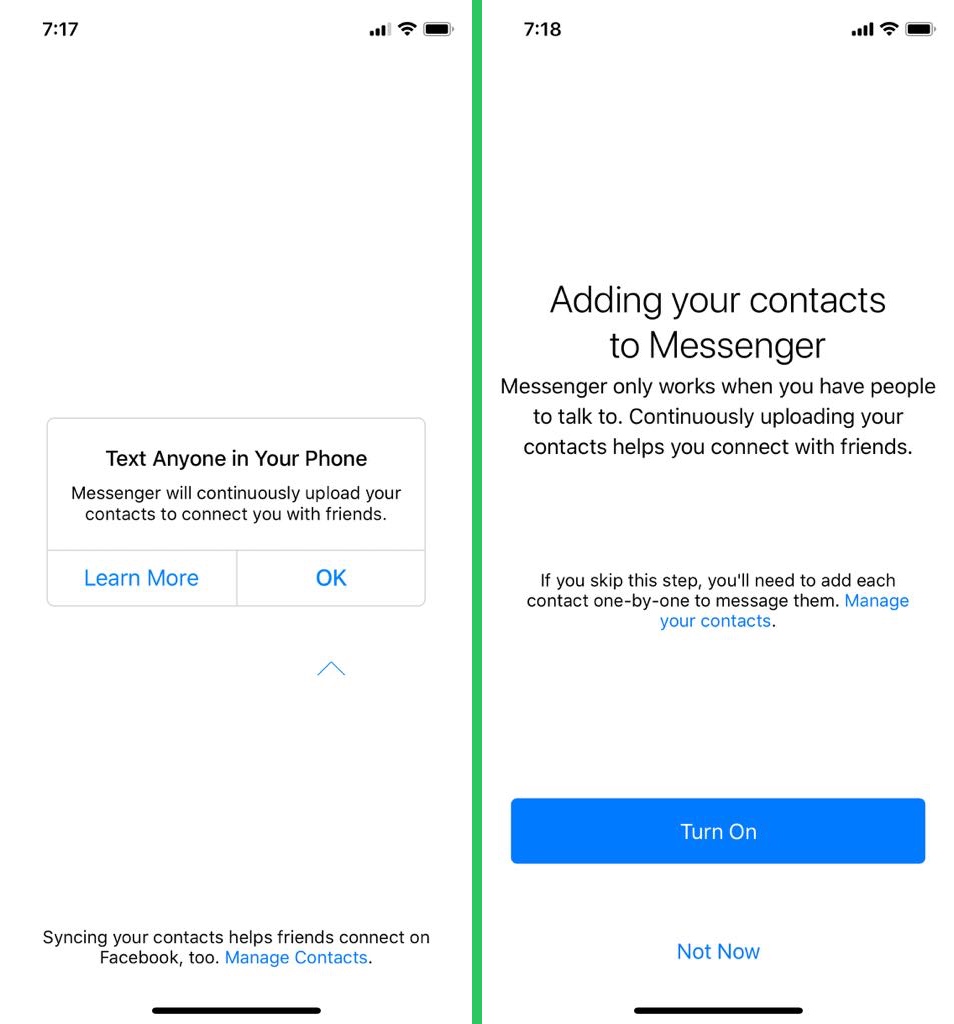


{kind=link}
{kind=link}