And the SpaceX/Cursor deal is exposing just how in demand GPU clusters are.
Even the favorite shoe brand of every tech bro in 2017 is looking to get into the compute game…
Tracy Alloway@tracyalloway
Allbirds, the shoe brand, now says it’s an AI compute company.
2:31 PM · Apr 15, 2026 · 4,29 MIO. Views
376 Replies · 692 Reposts · 9760 Likes
All of this is real. The scarcity is real. And the companies capitalizing on it are posting incredible numbers and building meaningful businesses. But here’s the thing: every prior technology cycle had a scarce resource at its center, and every time, that scarcity eventually broke. When it did, the value map reshuffled dramatically – and the companies that looked unassailable during the scarcity era often weren’t the long-term winners.
Our view: the venture landscape is dramatically overweighting what is in demand today versus what is going to be in demand for the next ten years.
We’ve Seen This Before
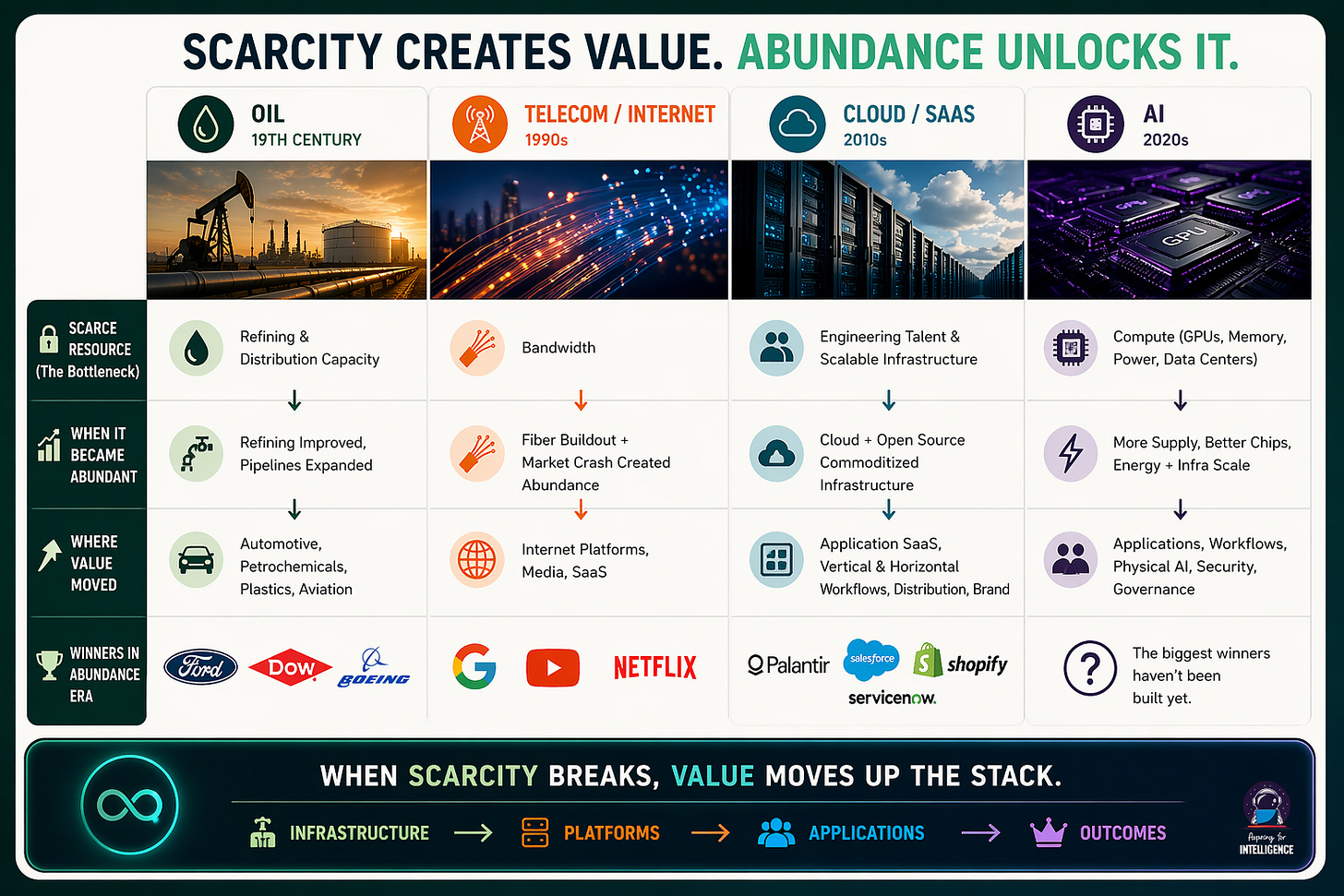
Every prior innovation cycle started with a scarce resource that eventually became abundant.
Oil in the 19th century
In the late 1800s, crude was actually plentiful. Wildcatters kept finding more of it. The real bottleneck was refining capacity and distribution, which is why John D. Rockefeller built Standard Oil around those layers rather than drilling. But once refining technology matured and pipeline networks expanded, that bottleneck broke too. And the interesting thing is what came next: the automotive economy, petrochemicals, plastics, commercial aviation. Ford’s Model T only made sense because fuel was getting cheap. The plastics revolution required abundant petroleum feedstocks. These were entire industries that nobody was really thinking about during the scarcity era, and they ended up dwarfing the value of oil extraction and refining combined.
Telecom in the 1990s
The telecom boom of the late ’90s followed a similar arc, with a twist. Bandwidth was the scarce resource, and telecoms raised hundreds of billions to control it. Then the bubble burst; and the bust created the abundance. All that fiber didn’t disappear when Global Crossing and WorldCom went bankrupt. It got bought at pennies on the dollar. What happened next is instructive. Google, YouTube, Netflix, Spotify — none of these businesses were economically viable at 1999 bandwidth prices. They needed cheap bandwidth to exist at all. Meanwhile, the companies that had been valuable specifically because bandwidth was expensive got crushed. RealNetworks, once worth over $30 billion for its streaming compression tech, became irrelevant almost overnight. Why bother with clever compression when you can just send the full stream? CDN technology went from a high-margin standalone business to a feature baked into cloud platforms. Even Salesforce and the broader SaaS model were downstream beneficiaries of cheap, reliable connectivity.
The winners weren’t the ones who owned the scarce resource or built optimization tricks around it. They were the ones who built for the world where it was cheap.
Cloud / SaaS in the 2010s
Cloud and SaaS repeated the pattern one more time. Through the 2010s, the bottleneck was engineering talent and scalable infrastructure. Engineer salaries soared. Companies fought viciously over hiring. A legendary show satirizing Silicon Valley culture became required viewing. SaaS pricing reflected the genuine cost of building and maintaining good software. Then AWS, Azure, and GCP commoditized infrastructure, open source commoditized components, and value migrated again — from horizontal platforms to vertical SaaS with deep domain knowledge, from engineering as the moat to distribution as the moat, from building software to configuring it. Some of the most valuable late-stage SaaS companies weren’t particularly technically impressive. They just had the best go-to-market and the deepest workflow integration. Same story: when the scarce resource got cheap, value moved up the stack toward whoever was closest to the end user and the actual problem being solved.
These prior waves prove that as the scarce resource becomes abundant, value migrates UP THE STACK. Applications, workflows, and things that touch the user accrue value; “optimization” layers that were valuable during scarcity get squeezed.
Bandwidth prices in the 90s and early 2000s got cheap fast
What’s Priced For Scarcity Today?
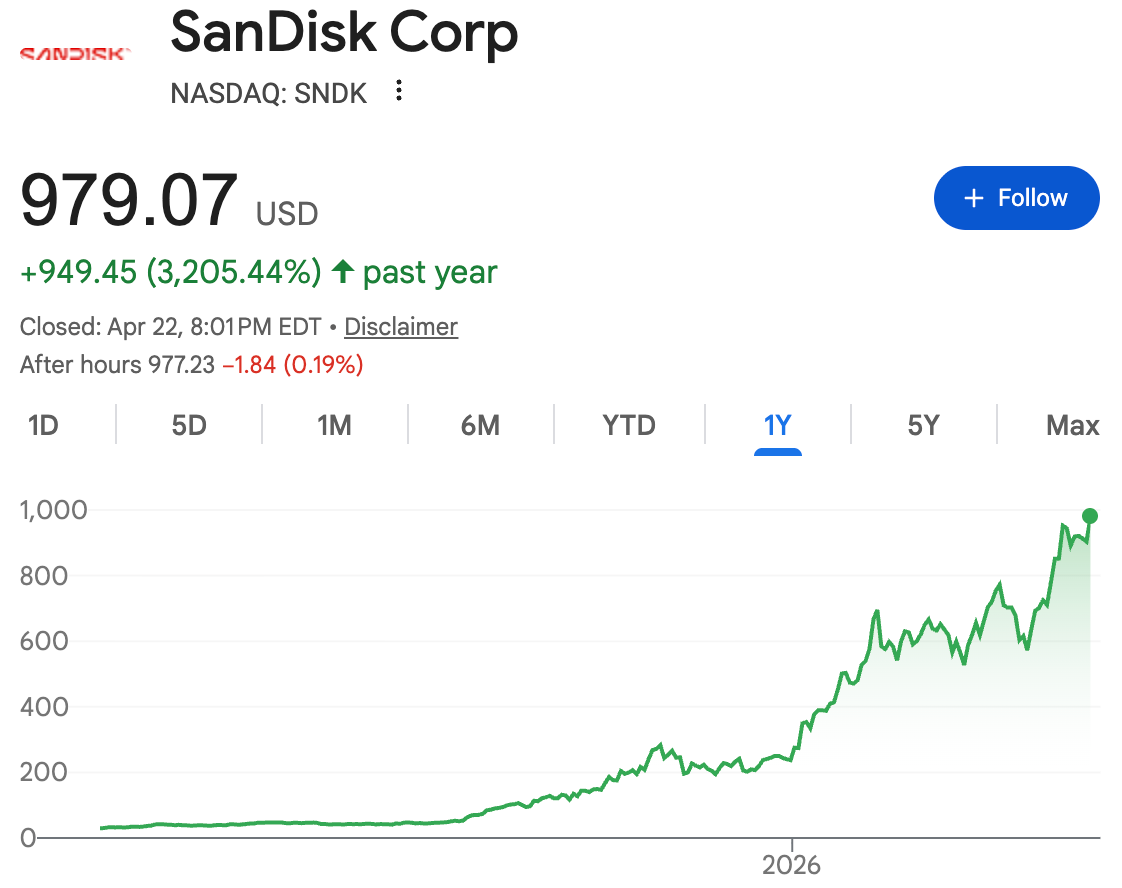
It feels like fundraising and commercialization in the AI market today is heavily skewed towards companies capitalizing on the compute shortages. On the public side, chip companies like Nvidia have been making hay for the past few years, but nearly every company across memory (Sandisk, SK Hynix), semis (TSMC, AMD), and power (Bloom Energy, Vistra) have been seeing record revenues, profits, and a ripping stock. This makes sense — during scarcity, the resource providers always have the best economics. The question is how much of this is structural versus cyclical.
When a 35 year old company has what everyone wants
We’re seeing the same dynamic play out across the private markets. Heavy funding, rapid ARR growth, and massive valuations in categories that are fundamentally downstream of expensive compute include:
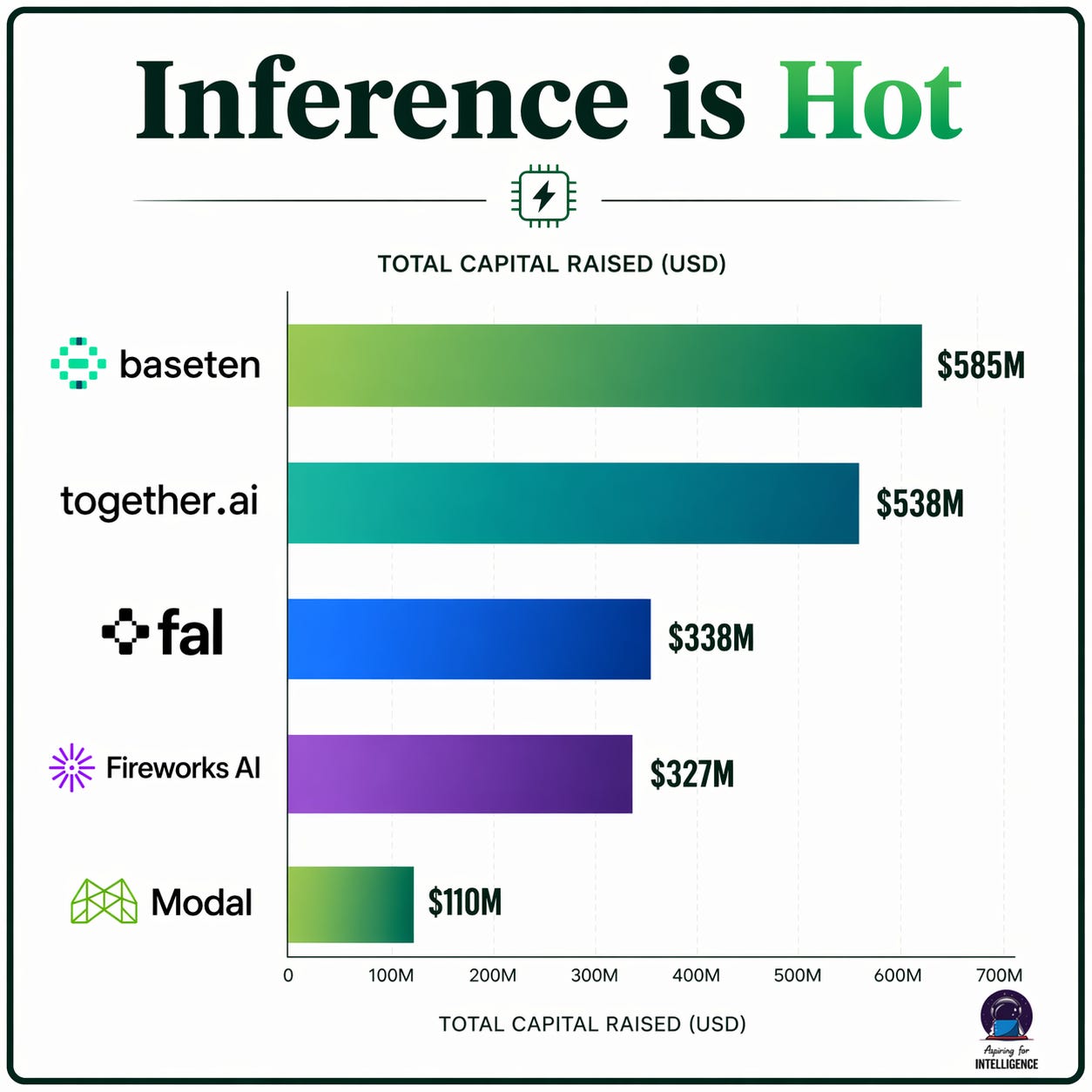
Inference optimization and RL reasoning. Companies like Together AI, Baseten, and Fireworks are building real, fast-growing businesses around making inference faster and cheaper. This is a fantastic category to be in when compute is expensive and generating more intelligence per dollar absolutely matters. On the other end, think about what happened to RealNetworks, or to Akamai’s pricing power once bandwidth got cheap. You don’t need clever compression tricks when you can just send the full stream. When compute gets cheap, you can brute-force a lot of what these techniques achieve — run a bigger model, run multiple passes, throw more inference at the problem and pick the best answer. The techniques won’t disappear, but core pricing will likely commoditize. So the question becomes whether these businesses will have to refactor to maintain durable pricing power in a world with abundant compute.
GPU access and compute brokering. CoreWeave is probably the most prominent example, but there’s a whole cohort of GPU cloud companies — Lambda Labs, Crusoe, and others — that have raised significant capital on the back of GPU scarcity. The core (dumbed down) value proposition for most of these companies is “we have allocation.” That is a terrific in a supply-constrained world. The question is how sustainable that moat is when that constraint goes away. What happens when the arb goes away?
Model training and tooling. When a single frontier training run costs tens or hundreds of millions of dollars and a failed run is a catastrophe, the willingness to pay for anything that makes that process more reliable and efficient is enormous. That math changes pretty quickly if compute costs drop by an order of magnitude.
None of this means these are bad companies or bad technologies. In fact sometimes its the exact opposite. The pattern from prior cycles isn’t that the scarce-resource companies go to zero — Exxon is still enormous, Akamai still exists, AWS still prints money.
The point is that during scarcity, the market tends to OVERVALUE these layers and UNDERVALUE what comes next. The best returns in the oil era didn’t come from refining. The best returns in the internet era didn’t come from owning fiber. And the best returns in AI might not come from the layers that look most valuable right now.
Where Will Value Migrate In The Abundance Era?
When compute and infrastructure are no longer the bottleneck, AI goes from supply-constrained to demand-constrained. And in demand-constrained markets, the moats that have always mattered reassert themselves: user attention, distribution, brand, workflow integration, and switching costs.
So what areas do we think will flourish in an era of cheap compute?
Vertical applications that own the user relationship. Companies embedded in real workflows with proprietary data accumulated through thousands of customer interactions — legal AI built on real contract negotiations, security platforms with proprietary threat data, healthcare AI woven into clinical decisions. The test: if every model becomes equally capable and cheap tomorrow, does your company still matter? If yes because you own the distribution or you’re too embedded to rip out, you’re on the right side. These companies‘ margins actually expand as compute gets cheaper, which is the opposite of what happens to the optimization layer.
Physical AI, robotics, and space. When compute is cheap, the constraint shifts from „can we run the model“ to „can we interact with the physical world.“ Companies like Physical Intelligence, Starcloud, Echodyne, and the wave of autonomous systems startups are building in a domain where the moats look nothing like software AI — manufacturing, hardware design, regulatory approval, and supply chains. You can’t GitHub clone a robot factory. There’s a version of this story where the pure-software AI crowd gets caught off guard by how much value migrates toward the intersection of intelligence and atoms, precisely because that’s where the unglamorous barriers to entry still exist.
Security, safety, and governance. This category is still in its infancy today, which is the point. When every company goes from a handful of AI tools to dozens of agents, the pain shifts from access to control — governing agent behavior, auditing outputs, managing security and compliance. Think about what happened in cloud: nobody cared about cloud security when companies had three workloads. When cloud became ubiquitous, Palo Alto Networks and CrowdStrike built massive businesses around securing it. AI governance — companies building the equivalent of model-level audit trails, agent access controls, output monitoring — is on that same curve, just earlier.
Categories that don’t even exist yet i.e the big question mark. Automobiles and commercial aviation came 30+ years after oil was struck. Radio and TV arrived decades after Edison’s first power station opened. The internet took more than a decade to explode. The truth is, the categories that will generate the most value in the age of AI haven’t even been discovered yet. Which makes this whole era even more exciting!
What Are You Building For?
Today, the most scarce resource in the AI supercycle is compute – spanning GPUs, memory, bandwidth, data centers, and energy. That single bottleneck is driving billions in record profits and soaring stock prices for public companies building around this layer, as well as the many private inference and GPU optimization startups collectively growing like a weed. But if prior cycles teach us any lessons, its that patterns in early innovation waves are temporary. Oil refining was scarce until it wasn’t. Bandwidth was scarce until the telecom bust accidentally created the abundance. Cloud infrastructure was scarce until AWS turned it into a utility.
When the scarcity breaks, the effects are real. Pricing power shifts. Margins compress at the resource layer. Value moves up the stack. None of this means the compute companies disappear — Exxon is still enormous and the hyperscalers print money. But the outsized returns tend to come from the companies that were building for what abundance makes possible, not from the ones optimizing around what scarcity made painful.
The question for founders and investors is a simple one: are you building for the scarcity era, or the abundance era? Because the flip is coming.
The rebirth of advertisements and AdTech in the age of AI
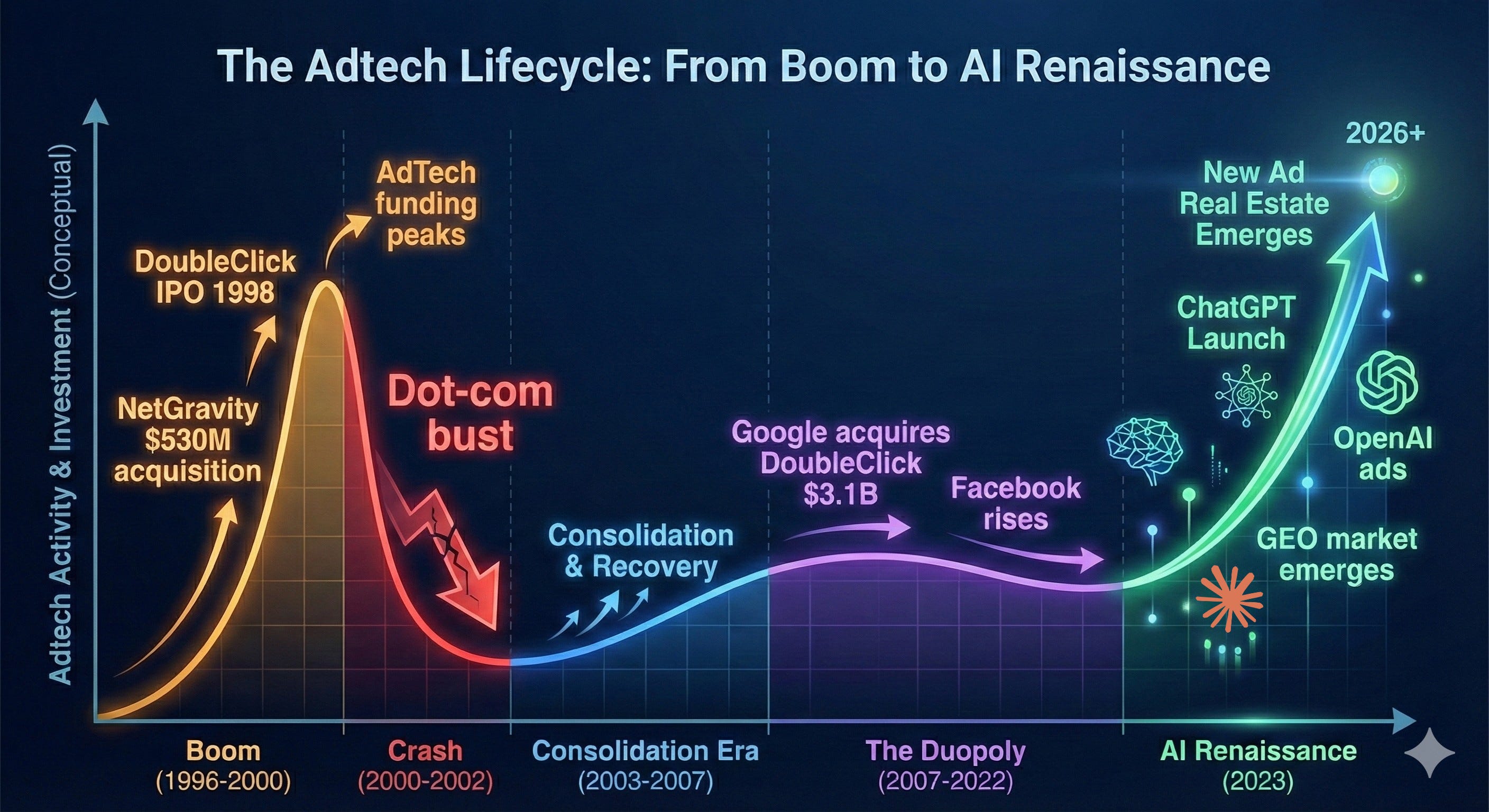
AdTech used to matter. In the early 2000s, it was one of the hottest areas in tech – hundreds of startups, billions in VC funding, genuine innovation in targeting and formats. Then Google bought DoubleClick in 2007 for $3.1 billion, Facebook launched its ad platform, and the game was over. The duopoly that emerged didn’t just dominate—at their peak, Google and Meta controlled nearly 80% of U.S. digital ad growth. Everyone else was left fighting for scraps. For the past 15 years, „AdTech startup“ became practically an oxymoron as the industry consolidated into irrelevance.
But now, in the age of AI, we are starting to see a resurgence of advertising as a booming revenue source for companies. OpenAI announced last week that they would be testing ads in ChatGPT in a “bid to boost revenue”, and the healthcare AI startup OpenEvidence recently surpassed $100M annualized run-rate revenue (and doubled their valuation to $12B!), largely on an ad-supported revenue model. And around this, the market for AI tools in advertising optimization is growing quickly.
So why are we seeing such a sharp resurgence in a field that just a few years ago was essentially dead?
Three fundamental shifts are driving this renaissance:
First, AI platforms have created the first genuinely new advertising surface since social media. ChatGPT’s 800+ million weekly active users and Claude’s ~20 million monthly active users represent massive, engaged audiences that didn’t exist two years ago. Unlike the incremental improvements of the past decade – slightly better targeting, marginally improved attribution – these platforms represent entirely new real estate where the old duopoly rules don’t apply.
Second, intent signals are dramatically more sharply defined than anything we’ve seen before. When someone types “best CRM for startups” into Google, you get a decent intent signal. But when someone has a 20-message conversation with ChatGPT about their specific sales team structure, pain points, budget constraints, and technical requirements? That’s intent data at a resolution advertisers have only dreamed about. The conversational nature of AI interactions creates a richness of context that search queries simply can’t match.
Third, entirely new infrastructure is required—and being built at breakneck speed. The old AdTech stack was built for display ads, search results, and social feeds. None of it works for conversational AI. How do you measure attribution when there’s no “click”? How do you bid on inventory that’s generated dynamically in response to natural language? What does “viewability” even mean in a text-based conversation? This infrastructure gap is spawning entirely new categories like Generative Engine Optimization (GEO), with dozens of startups raising millions to solve problems that didn’t exist 18 months ago.
So should we be heralding the rebirth of AdTech in the age of AI?
Let’s dig in.
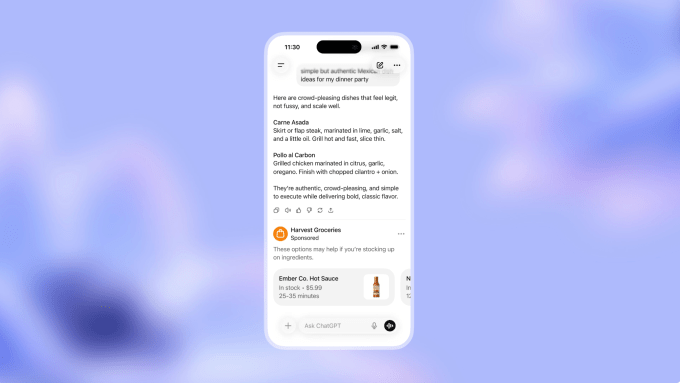
AI is Creating New Real Estate for Ads
The rapid growth of foundation models with “chatbot-style interfaces” has brought forward what we believe is the first new real estate for advertisements since the emergence of social networks. Google and Meta were able to establish dominance in ad models by aggregating eyeballs; Google in search and Meta in social. (And to a lesser extent other social media platforms like Snap, Pinterest, etc.). As an advertiser, why would I place my ads anywhere other than where consumers are aggregating to get most bang for my buck?
Now in the Age of AI, consumers are no longer flocking to the traditional platforms but increasingly to places like ChatGPT (>800M WAUs) and Claude (~20M MAUs). And these consumers are not just making simple search queries but having full-blown conversations on every topic under the sun. This is an advertiser’s dream: a wide-scale canvas with rich, user-generated intent. And advertisers are no longer limited to traditional search displays with sponsored results but can embed more natural advertisements within AI-generated responses. While the consumer may not love this (more on that below), it certainly makes sense for the advertisers.
Beyond consumer-facing platforms, AI development tools are creating a quieter but equally significant advertising opportunity. When developers use tools like Lovable, Replit, or Cursor to build applications, these platforms make dozens of architectural decisions on their behalf—which database to use, where to host, which payment processor to integrate.
Each of these decisions represents potential advertising inventory. Supabase could sponsor recommendations in database selection flows. Vercel could appear as a ‘suggested deployment option’ when a developer’s app is ready to ship. Stripe could surface contextual offers when payment processing code is being written.
The key difference from traditional developer advertising (think Stack Overflow banner ads) is that these aren’t interruptions—they’re recommendations at the exact moment of intent. A developer isn’t being shown a database ad while reading about React hooks; they’re being offered database options precisely when their AI agent is about to scaffold database code. The conversion potential is orders of magnitude higher.
Vertical AI Is Creating Specialized Inventory
It’s not just the large model providers themselves that are benefiting from ads.
The rise of vertical AI providers is creating a new, specialized inventory for high-intent, high-value ads. Verticals like healthcare, legal, finance, real estate, and other professional services are becoming the new adtech frontier, offering advertisers direct access to high-value audiences outside the Google-Meta duopoly for the first time in over a decade.
One great example here is OpenEvidence, which has quickly grown into the leading “AI-powered medical search engine” for clinicians. The company recently said that 40% of physicians across the US across 10K hospitals and medical centers now use OpenEvidence on a daily basis. What else is interesting and unique is its business model: OpenEvidence is free to use for verified medical professionals, and generates revenue largely through advertising.
Per a great business breakdown from Contrary Research:
Given that pharmaceutical companies spent approximately $20 billion annually on marketing to healthcare professionals in the US as of 2019, capturing a portion of this market through digital channels could generate substantial revenue for the company. OpenEvidence’s advertising focus on contextual advertising and sponsored content while maintaining trust. For example, if a doctor submits a query about diabetes treatments, a sponsored summary from a pharmaceutical manufacturer may appear, or a banner for relevant clinical webinars could be displayed.
This advertising model has allowed OpenEvidence to reach >$100M annualized run-rate revenue in just a few short years.
We believe that other vertical AI tools will also embed this type of model, giving away the product to end users for free while generating revenue from charging advertisers. In vertical AI, the intent signals are clearer than ever—and unlike the generic search box, users are getting AI agents that actually solve their specific problems, creating a sustainable value exchange that justifies the ad-supported model.
Measurement Primitives are Changing and New Infrastructure is Emerging
Attribution in AI-native experiences is fundamentally different. The old AdTech stack was built for discrete surfaces where ads could be served, clicked, and tracked, but in conversational and agentic interfaces, there’s often no obvious “ad slot” and no click at all. Instead, influence is embedded inside multi-turn workflows: what the model recommends, what the user accepts, and what gets generated.
In next-gen AI apps, advertising is moving into the flow of work. When a developer scaffolds an app in Cursor, Lovable, or Vercel, the inventory isn’t a banner but it’s the moment an agent suggests a database, auth provider, or cloud service. In vertical AI tools, the same pattern holds: the “ad” looks like a contextual recommendation for a pharmaceutical brand, clinical resource, or specialized service. These touchpoints are integrated into the utility itself.
This shift is spawning an entirely new measurement rail. If clicks disappear, the new primitives become telemetry and adoption: logging multi-turn conversations, mapping model outputs to downstream actions, and tracking “acceptance events” like tab-to-insert, install, purchase, or integration. And because influence in a conversation is cumulative, the real challenge isn’t just attribution but it’s incrementality: did the recommendation actually change what the user would have done otherwise?
As a result of this shift, we are starting to see new ad networks emerge to serve these “in-flow” moments.
On the measurement side, companies like Profound and Bluefish are building the GEO observability layer, tracking share-of-response, competitive displacement, and brand presence across models.
On the distribution side, a new generation of AI-native ad platforms is forming across multiple surfaces: platforms like ZeroClick, OpenAds, and Nex.ad are beginning to monetize dynamic, contextually relevant recommendations inside or alongside AI conversations, while publisher-centric AI engagement platforms like Linotype.ai help site owners retain users and surface native monetization opportunities.
But unlike the old web, the “auction” can’t just pick the highest bidder. It has to operate inside generation loops, ranking units based on contextual relevance, quality, and bid while navigating trust and policy constraints in sensitive domains like healthcare and legal. Pricing models may shift as well, away from CPM/CPC and toward outcomes like cost-per-accept, cost-per-embed, or cost-per-adoption.
The biggest wildcard is walled gardens. If OpenAI, Anthropic, Google, and vertical copilots control the interface, they may also control the inventory and measurement rails, turning AI advertising into a handful of closed ecosystems rather than an open programmatic market. Time will tell!
Another key challenge is whether people will feel that the answers they are served by the LLMs are influenced by the advertisements that appear. If I ask Claude for the best recommendations for hotels in Switzerland, will I know it showing me what the model says is “best”, or which hotel is spending the most on advertising for this query result?
But here’s the interesting part: in the same study referenced above, only 28% of respondents wanted fewer ads. Which suggests that its not the brands or products being peddled they dislike, but how the ads are actually served.
This could actually be a boon to the new platforms like OpenAI and Anthropic, as well as the emerging AI Adtech tools. By finding creative, non-intrusive, intent-based, transparent, and beneficial ways to reach consumers, a new form of advertising could actually flourish.
So we’re left with the thought…
“Traditional AdTech is Dead…Long Live AdTech For AI“.
As of January 2, 2026, the digital landscape has reached a historic inflection point that many analysts once thought impossible. For the first time since the early 2000s, the iron grip of the traditional search engine is showing visible fractures. OpenAI’s ChatGPT Search has officially captured a staggering 17-18% of the global query market, a meteoric rise that has forced a fundamental redesign of how humans interact with the internet’s vast repository of information.
While Alphabet Inc. (NASDAQ: GOOGL) continues to lead the market with a 78-80% share, the nature of that dominance has changed. The „search war“ is no longer about who has the largest index of websites, but who can provide the most coherent, cited, and actionable answer in the shortest amount of time. This shift from „retrieval“ to „resolution“ marks the end of the „10 blue links“ era and the beginning of the age of the conversational agent.
The Technical Evolution: From Indexing to Reasoning
The architecture of ChatGPT Search in 2026 represents a radical departure from the crawler-based systems of the past. Utilizing a specialized version of the GPT-5.2 architecture, the system does not merely point users toward a destination; it synthesizes information in real-time. The core technical advancement lies in its „Citation Engine,“ which performs a multi-step verification process before presenting an answer. Unlike early generative AI models that were prone to „hallucinations,“ the current iteration of ChatGPT Search uses a retrieval-augmented generation (RAG) framework that prioritizes high-authority sources and provides clickable, inline footnotes for every claim made.
This „Resolution over Retrieval“ model has fundamentally altered user expectations. In early 2026, the technical community has lauded OpenAI’s ability to handle complex, multi-layered queries—such as „Compare the tax implications of remote work in three different EU countries for a freelance developer“—with a single, comprehensive response. Industry experts note that this differs from previous technology by moving away from keyword matching and toward semantic intent. The AI research community has specifically highlighted the model’s „Thinking“ mode, which allows the engine to pause and internally verify its reasoning path before displaying a result, significantly reducing inaccuracies.
A Market in Flux: The Duopoly of Intent
The rise of ChatGPT Search has created a strategic divide in the tech industry. While Google remains the king of transactional and navigational queries—users still turn to Google to find a local plumber or buy a specific pair of shoes—OpenAI has successfully captured the „informational“ and „creative“ segments. This has significant implications for Microsoft (NASDAQ: MSFT), which, through its deep partnership and multi-billion dollar investment in OpenAI, has seen its own search ecosystem revitalized. The 17-18% market share represents the first time a competitor has consistently held a double-digit piece of the pie in over twenty years.
For Alphabet Inc., the response has been aggressive. The recent deployment of Gemini 3 into Google Search marks a „code red“ effort to reclaim the conversational throne. Gemini 3 Flash and Gemini 3 Pro now power „AI Overviews“ that occupy the top of nearly every search result page. However, the competitive advantage currently leans toward ChatGPT in terms of deep engagement. Data from late 2025 indicates that ChatGPT Search users average a 13-minute session duration, compared to Google’s 6-minute average. This „sticky“ behavior suggests that users are not just searching; they are staying to refine, draft, and collaborate with the AI, a level of engagement that traditional search engines have struggled to replicate.
The Wider Significance: The Death of SEO as We Knew It
The broader AI landscape is currently grappling with the „Zero-Click“ reality. With over 65% of searches now being resolved directly on the search results page via AI synthesis, the traditional web economy—built on ad impressions and click-through rates—is facing an existential crisis. This has led to the birth of Generative Engine Optimization (GEO). Instead of optimizing for keywords to appear in a list of links, publishers and brands are now competing to be the cited source within an AI’s conversational answer.
This shift has raised significant concerns regarding publisher revenue and the „cannibalization“ of the open web. While OpenAI and Google have both struck licensing deals with major media conglomerates, smaller independent creators are finding it harder to drive traffic. Comparison to previous milestones, such as the shift from desktop to mobile search in the early 2010s, suggests that while the medium has changed, the underlying struggle for visibility remains. However, the 2026 search landscape is unique because the AI is no longer a middleman; it is increasingly the destination itself.
The Horizon: Agentic Search and Personalization
Looking ahead to the remainder of 2026 and into 2027, the industry is moving toward „Agentic Search.“ Experts predict that the next phase of ChatGPT Search will involve the AI not just finding information, but acting upon it. This could include the AI booking a multi-leg flight itinerary or managing a user’s calendar based on a simple conversational prompt. The challenge that remains is one of privacy and „data silos.“ As search engines become more personalized, the amount of private user data they require to function effectively increases, leading to potential regulatory hurdles in the EU and North America.
Furthermore, we expect to see the integration of multi-modal search become the standard. By the end of 2026, users will likely be able to point their AR glasses at a complex mechanical engine and ask their search agent to „show me the tutorial for fixing this specific valve,“ with the AI pulling real-time data and overlaying instructions. The competition between Gemini 3 and the GPT-5 series will likely center on which model can process these multi-modal inputs with the lowest latency and highest accuracy.
The New Standard for Digital Discovery
The start of 2026 has confirmed that the „Search Wars“ are back, and the stakes have never been higher. ChatGPT’s 17-18% market share is not just a number; it is a testament to a fundamental change in human behavior. We have moved from a world where we „Google it“ to a world where we „Ask it.“ While Google’s 80% dominance is still formidable, the deployment of Gemini 3 shows that the search giant is no longer leading by default, but is instead in a high-stakes race to adapt to an AI-first world.
The key takeaway for 2026 is the emergence of a „duopoly of intent.“ Google remains the primary tool for the physical and commercial world, while ChatGPT has become the primary tool for the intellectual and creative world. In the coming months, the industry will be watching closely to see if Gemini 3 can bridge this gap, or if ChatGPT’s deep user engagement will continue to erode Google’s once-impenetrable fortress. One thing is certain: the era of the „10 blue links“ is officially a relic of the past.
Recent exploits show iPadOS windows running on an iPhone, hinting at the future of Apple hardware and software alike—while also possibly revealing its incoming foldable phone experience.
Photo-Illustration: WIRED Staff; Getty Images; Courtesy of Apple
Hackers poking around in iOS 26 recently uncovered something Apple definitely didn’t intend anyone to see: every modern iPhone is running the operating system Apple’s upcoming “iPhone Fold” will likely use. Which means these phones are—right now—already capable of running a full, fluid desktop experience.
From a performance standpoint, that shouldn’t be surprising. At Apple’s September 2025 event, the company claimed the A19 Pro chip inside the iPhone Air and iPhone 17 Pro offers “MacBook Pro levels of compute.” And that iPhone chip is reportedly destined to power a cheaper MacBook in 2026. The line between Apple’s hardware is being further blurred, then—but what’s wild is that the software side of things has blurred completely too. It’s just that nobody realized.
For years, Apple has insisted that iOS and iPadOS are distinct, despite sharing code and habitually borrowing each other’s features. But a self-proclaimed “tech geek” on Reddit who got iPad features running on an iPhone claimed they’re not merely similar—they’re essentially the same: “Turns out iOS has all the iPadOS code (and vice versa; you can for instance enable Dynamic Island on iPad).”
TechExpert2910 revealed on Reddit that his hacked iPhone ran iPad OS “incredibly well,” making his 17 Pro Max an “insane pocket computer” with more RAM than his M4 iPad Pro.
The hack relies on an exploit that tricks the iPhone’s operating system into thinking it’s running on an iPad. That unlocks smallish tweaks such as a landscape Home Screen, an iPad-style app switcher, and more Dock items. But it also provides transformative changes such as running desktop-grade apps that aren’t available for iPhone, full windowed multitasking, and optimal external display support. All without Apple Silicon breaking a sweat.
Deskblocked
The exploit is already patched in the iOS 26.2 beta, and the Redditor accused Apple of locking out iPhone users and artificially limiting older devices to push upgrades. But are things really that simple?
It’s not like the “phone as PC” dream is new. Android’s been chasing it since DeX debuted in 2017. Barely anyone cares. So why should Apple? Perhaps the concept is a niche nerd fantasy. And there’s the longtime argument that if you want to do “proper” work, you need a “proper” computer. If even an iPad can’t replace a computer, how can an iPhone?
In June, after 15 years, the iPad got key software features, including resizable and movable windows.
Except, as WIRED demonstrated, an iPad can replace a computer for plenty of people—you just need the right accessories. It therefore follows the same is true for an iPhone running the exact same software. But where will any momentum for this future come from?
Android 16 is technically ready for another crack at desktop mode, with a new system that builds on DeX. But even now, having finally escaped beta, it’s buried in developer settings. That might be down to the grim state of big-screen Android apps, or the desktop experience itself feeling, politely, “rocky.”
Paradoxically, Apple appears to be further ahead despite never announcing any of this. It already has a deep ecosystem of desktop-grade iPad apps. And the iPad features running on iPhone already look polished. Sure, some interface quirks remain, and you might need to file your fingers to a point to hit window controls. But the performance is fast, fluid, and snappy. So if the experience is this good, why is Apple so determined to hide it?
Profit by Design
One argument is practical. Apple likes each device to be its own thing, optimized for a specific form factor. It’s keen to finesse the transition between platforms rather than have one device to rule them all. A phone lacks a big screen and a physical keyboard. Plugging those things in on a train isn’t as elegant as opening a MacBook or using an iPad connected to a Magic Keyboard. However, with imagination, you can see the outlines of a new ecosystem of profitable accessories for a more capable iPhone.
Could the bottom of your iPhone screen look more like this in the future? Apple’s current phone software certainly makes it possible.
But Apple hasn’t got where it has by selling accessories nor by making a market for others to do so. Most of its profits come from a long-running strategy to nudge people into buying more hardware that coexists. It doesn’t want you to choose between an iPhone, an iPad, a MacBook Air, and an iMac. It wants you to buy all of them.
But if an iPhone can do iPad things, maybe someone won’t buy an iPad. If iPads act too much like Macs, people might not buy as many Macs. Strategically chosen—if sometimes artificial—limits and product segmentation have pride of place in Cupertino’s rulebook. A convergence model could knock user experience and simplicity; but Apple would likely be more fearful of how it could negatively impact sales.
Hidden Potential
That all said, perhaps there is another explanation: Apple is saving this for an inflection point—the iPhone Fold. Rumors suggest that Apple has solved the “screen crease” problem and will in 2026 ship a foldable with a 7.8-inch, 4:3 display that’s similar to (but sharper than) the iPad mini’s.
A tablet-sized display that doesn’t let you multitask like on an iPad would be absurd, especially on a device likely to cost two or three times more than an actual iPad mini. Doubly so if Apple puts last year’s iPhone chip into a MacBook that will have a full desktop environment and support at least one external display.
And for anyone fretting about being forced into a more desktop-style iPhone, Apple already solved that problem. It killed the Steve Jobs vision of the iPad that sat between two computing extremes by letting users switch modes. The iPhone could follow suit, defaulting to its original purist mode while allowing power users to tap into windowing and external device support.
These hacks, then, have given us a window into the iPhone Fold operating system and other aspects of a possible Apple future. They show that iPad features on iPhone already look slick and make complete sense. And the crazy thing is they’re in your iPhone’s software right now. Next year, they’ll almost certainly be unleashed on the most expensive iPhone Apple has ever made. The question is whether Apple will let regular iPhone users have them, too.
Copywriters were one of the first to have their jobs targeted by AI firms. These are their stories, three years into the AI era.
Back in May 2025, not long after I put out the first call for AI Killed My Job stories, I received a thoughtful submission from Jacques Reulet II. Jacques shared a story about his job as the head of support operations for a software firm, where, among other things, he wrote copy documenting how to use the company’s product.
“AI didn’t quite kill my current job, but it does mean that most of my job is now training AI to do a job I would have previously trained humans to do,” he told me. “It certainly killed the job I used to have, which I used to climb into my current role.” He was concerned for himself, as well as for his more junior peers. As he told me, “I have no idea how entry-level developers, support agents, or copywriters are supposed to become senior devs, support managers, or marketers when the experience required to ascend is no longer available.”
When we checked back in with Jacques six months later, his company had laid him off. “I was actually let go the week before Thanksgiving now that the AI was good enough,” he wrote.
He elaborated:
Chatbots came in and made it so my job was managing the bots instead of a team of reps. Once the bots were sufficiently trained up to offer “good enough” support, then I was out. I prided myself on being the best. The company was actually awarded a “Best Support” award by G2 (a software review site). We had a reputation for excellence that I’m sure will now blend in with the rest of the pack of chatbots that may or may not have a human reviewing them and making tweaks.
It’s been a similarly rough year for so many other workers, as chronicled by this project and elsewhere—from artists and illustrators seeing client work plummet, to translators losing jobs en masse, to tech workers seeing their roles upended by managers eager to inject AI into every possible process.
But there haven’t been many investigations into how all that’s borne out since. How have the copywriters been faring, in a world awash in cheap AI text generators and wracked with AI adoption mania in executive circles? As always, we turn to the workers themselves. And once again, the stories they have to tell are unhappy ones. These are accounts of gutted departments, dried up work, lost jobs, and closed businesses. I’ve heard from copywriters who now fear losing their apartments, one who turned to sex work, and others, who, to their chagrin, have been forced to use AI themselves.
Readers of this series will recognize some recurring themes: The work that client firms are settling for is not better when it’s produced by AI, but it’s cheaper, and deemed “good enough.” Copywriting work has not vanished completely, but has often been degraded to gigs editing client-generated AI output. Wages and rates are in free fall, though some hold out hope that business will realize that a human touch will help them stand out from the avalanche of AI homogeneity.
As for Jacques, he’s relocated to Mexico, where the cost of living is cheaper, while he looks for new work. He’s not optimistic. As he put it, “It’s getting dark out there, man.”
Before we press on, a quick word: Many thanks for reading Blood in the Machine and AI Killed My Job. This work is made possible by readers who pitch in a small sum each month to support it. And, for the cost of $6, a decent coffee a month, or $60 a year, you can help ensure it continues, and even, hopefully, expands. Thanks again, and onwards.
The next installments will focus on education, healthcare, and journalism. If you’re a teacher, professor, administrative assistant, TA, librarian, or otherwise work in education, or a doctor, nurse, therapist, pharmacist, or otherwise work in healthcare, please get in touch at AIKilledMyJob@pm.me. Same if you’re a reporter, journalist, editor, or a creative writer. You can read more about the project in the intro post, or the installments published so far.
They let go of the all the freelancers and used AI to replace us
Social media copywriter
I believe I was among the first to have their career decimated by AI. A privilege I never asked for. I spent nearly 6 years as a freelance social media copywriter, contracting through a popular company that worked with clients—mostly small businesses—across every industry you can imagine. I wrote posts and researched topics for everything from beauty to HVAC, dentistry, and even funeral homes. I had to develop the right voice for every client and transition seamlessly between them on any given day. I was frequently called out and praised, something that wasn’t the norm, and clients loved me. I was excellent at my job, and adapting to the constantly changing social media landscape and figuring out how to best the algorithms.
In early 2022, the company I contracted to was sold, which is never a sign of something good to come. Immediately, I expressed my concerns but was told everything would continue as it was and the new owners had no intention of getting rid of freelancers or changing how things were done. As the months went by, I noticed I was getting less and less work. Clients I’d worked with monthly for years were no longer showing up in my queue. I’d ask what was happening and get shrugged off, even as my work was cut in half month after month. At the start of the summer, suddenly I had no work. Not a single client. Maybe it was a slow week? Next week will be better. Until next week I yet again had an empty queue. And the week after. Panicking, I contacted my “boss”, who hadn’t been told anything. She asked someone higher up and it wasn’t until a week later she was told the freelancers had all been let go (without being notified), and they were going to hand the work off to a few in-house employees who would be using AI to replace the rest of us.
The company transitioned to a model where clients could basically “write” the content themselves, using Mad Libs-style templates that would use AI to generate the copy they needed, with the few in-house employees helping things along with some boilerplate stuff to kick things off.
They didn’t care that the quality of the posts would go down. They didn’t care that AI can’t actually get to know the client or their needs or what works with their customers. And the clients didn’t seem to care at first either, since they were assured it would be much cheaper than having humans do the work for them.
Since then, I’ve failed to get another job in social media copywriting. The industry has been crushed by things like Copy.AI. Small clients keep being convinced that there’s no need to invest in someone who’s an expert at what they do, instead opting for the cheap and easy solution and wondering why they’re not seeing their sales or engagement increasing.
For the moment, honestly I’ve been forced to get into online sex work, which I’ve never said “out loud” to anyone. There’s no shame in doing it, because many people genuinely enjoy doing it and are empowered by it, but for me it’s not the case. It’s just the only thing I’ve been able to get that pays the bills. I’m disabled and need a lot of flexibility in the hours I work any given day, and my old work gave me that flexibility as long as I met my deadlines – which I always did.
I think that’s another aspect to the AI job killing a lot of people overlook; what kind of jobs will be left? What kind of rights and benefits will we have to give up just because we’re meant to feel grateful to have any sort of job at all when there are thousands competing for every opening?
–Anonymous
I was forced to use AI until the day I was laid off
Corporate content copywriter
I’m a writer. I’ll always be a writer when it comes to my off-hours creative pursuits, and I hope to eventually write what I’d like to write full-time. But I had been writing and editing corporate content for various companies for about a decade until spring 2023, when I was laid off from the small marketing startup I had been working at for about six months, along with most of my coworkers.
The job mostly involved writing press releases, and for the first few months I wrote them without AI. Then my bosses decided to pivot their entire operational structure to revolve around AI, and despite voicing my concerns, I was essentially forced to use AI until the day I was laid off.
Copywriting/editing and corporate content writing had unfortunately been a feast-and-famine cycle for several years before that, but after this lay-off, there were far fewer jobs available in my field, and far more competition for these few jobs. The opportunities had dried up as more and more companies were relying on AI to produce content rather than human creatives. I couldn’t compete with copywriters who had far more experience than me, so eventually, I had to switch careers. I am currently in graduate school in pursuit of my new career, and while I believe this new phase of my life was the right move, I resent the fact that I had to change careers in the first place.
—Anonymous
I had to close my business after my client started using AI
Freelance copywriter
I worked as a freelance writer for 15 years. The last five, I was working with a single client – a large online luxury fashion seller based in Dubai. My role was writing product copy, and I worked my ass off. It took up all my time, so I couldn’t handle other clients. For the majority of the time they were sending work 5 days a week, occasionally weekends too and I was handling over 1000 descriptions a month. Sometimes there would be quiet spells for a week or two, so when they stopped contacting me…I first thought it was just a normal “dip”. Then a month passed. Then two. At that point, I contacted them to ask what was happening and they gave me a vague “We have been handling more of the copy in-house”. And that was that – I have never heard from them again, they didn’t even bother to tell me that they didn’t need my services any more. I’ve seen the descriptions they use now and they are 100% AI generated. I ended up closing my business because I couldn’t afford to keep paying my country’s self employment fees while trying to find new clients who would pay enough to make it worth continuing.
-Becky
We had a staff of 8 people and made about $600,000. This year we made less than $10k
Business copywriter
I was a business copywriter for eCommerce brands and did B2B sales copywriting before 2022.
In fact, my agency employed 8 people total at our peak. But then 2022 came around and clients lost total faith in human writing. At first we were hopeful, but over time we lost everything. I had to let go of everyone, including my little sister, when we finally ran out of money.
I was lucky, I have some friends in business who bought a resort and who still value my marketing expertise – so they brought me on board in the last few months, but 2025 was shaping up to be the worst year ever as a freelancer. I was looking for other jobs when my buddies called me.
At our peak, we went from making something like $600,000 a year and employing 8 people… To making less than $10K in 2025 before I miraculously got my new job.
Being repeatedly told subconsciously if not directly that your expertise is not valued or needed anymore – that really dehumanizes you as a person. And I’m still working through the pain of the two-year-long process that demolished my future in that profession.
It’s one of those rare times in life when a man cries because he is just feeling so dehumanized and unappreciated despite pouring his life, heart and soul into something.
I’ve landed on my feet for now with people who value me as more than a words-dispensing machine, and for that I’m grateful. But AI is coming for everyone in the marketing space.
Designers are hardly talked about any more. My leadership is looking forward to the day when they can generate AI videos for promotional materials instead of paying a studio $8K or more to film and produce marketing videos. And Meta is rolling out AI media buying that will replace paid ads agencies.
What jobs will this create? I can see very little. I currently don’t have any faith that this will get better at any point in the future.
I think the reason why is that I was positioned towards the “bottom” of the market, in the sense that my customers were nearly all startups and new businesses that people were starting in their spare time.
I had a partner Jake and together we basically got most of our clients through Fiverr. Fiverr customers are generally not big institutions or multi-nationals, although you do get some of that on Fiverr… It’s mostly people trying to start small businesses from the ground up.
I remember actually, when I was first starting out in writing, thinking “I can’t believe this is a job!” because writing has always come naturally to me. But the truth is, a lot of people out there go to start a business and what’s the first thing you do? You get a website, you find a template, and then you’re staring at a blank page thinking “what should I write about it?” And for them, that’s not an easy question to answer.
So that’s essentially where we fit in – and there’s more to it, as well, such as Conversion Rate Optimization on landing pages and so forth. When you boil it all down, we were helping small businesses find their message, find their market, and find their media – the way they were going to communicate with their market. And we had some great successes!
But nothing affected my business like ChatGPT did. All through Covid we were doing great, maybe even better because there were a lot of people staying home trying to start a new business – so we’d be helping people write the copy for their websites and so forth.
AI is really dehumanizing, and I am still working through issues of self-worth as a result of this experience. When you go from knowing you are valuable and valued, with all the hope in the world of a full career and the ability to provide other people with jobs… To being relegated to someone who edits AI drafts of copy at a steep discount because “most of the work is already done” …
2022-2023 was a weird time, for two reasons.
First, because I’m a very aware person – I remember that AI was creeping up on our industry before ChatGPT, with Jasper and other tools. I was actually playing with the idea of creating my own AI copywriting tool at the time.
When ChatGPT came out, we were all like “OK, this is a wake up call. We need to evolve…” Every person I knew in my industry was shaken.
Second, because the economy wasn’t that great. It had already started to downturn in 2022, and I had already had to let a few people go at that point, I can’t remember exactly when.
The first part of the year is always the slowest. So January through March, you never know if that’s an indication of how bad the rest of the year is going to be.
In our case, it was. But I remember thinking “OK, the stimulus money has dried up. The economy is not great.” So I wasn’t sure if it was just broad market conditions or ChatGPT specifically.
But even the work we were doing was changing rapidly. We’d have people come to us like “hey, this was written by ChatGPT, can you clean it up?”
And we’d charge less because it was just an editing job and not fully writing from scratch.
The drop off from 2022 to 2023 was BAD. The drop off from 2023 to 2024 was CATASTROPHIC.
By the end of that year, the company had lost the remaining staff. I had one last push before November 2023 (the end of the year has historically been the best time for our business, with Black Friday and Christmas) but I only succeeded in draining my bank account, and I was forced to let go of our last real employee, my sister, in early 2024. My brother and his wife were also doing some contract work for me at the time, and I had to end that pretty abruptly after our big push failed.
I remember, I believed that things were going to turn around again once people realized that even having a writing machine was not enough to create success like a real copywriter can. After all, the message is only one part of it – and divorced from the overall strategy of market and media, it’s never as effective as it can be.
In other words, there’s a context in which all marketing messages are seen, and it takes a human to understand what will work in that context.
But instead, what happened is that the pace of adoption was speeding up and all of those small entrepreneurs who used to rely on us, now used AI to do the work.
The technological advancements of GPT-4, and everyone trying to build their own AI, dominated the airwaves throughout 2023 and 2024. And technology adoption skyrocketed.
The thing is, I can’t even blame people. To be honest, when I’m writing marketing copy I use AI to speed up the process.
I still believe you need intelligence and strategy behind your ideas, or they will simply be meaningless words on a screen – but I can’t blame people for using these very cheap tools instead of paying an expert hundreds of dollars to get their website written.
Especially in my end of the market, where we were working with startup entrepreneurs who are bootstrapping their way to success.
When I officially left the business a few months ago, that left just my partner manning the Fiverr account we started with over 8 years ago.
I think the account is active enough to support a single person now, but I wouldn’t be so sure about next year. The drop off from 2022 to 2023 was BAD. The drop off from 2023 to 2024 was CATASTROPHIC.
Normally there are signs of life around April – in 2025, May had come and there was hardly a pulse in the business.
I still believe there may be a space for copywriters in the future, but much like tailors and seamstresses, it will be a very, very niche market for only the highest-end clients.
—Marcus Wiesner
My hours have been cut from nearly full time to 4-5 a month
Medical writer
I’m a medical writer; I work as a contract writer for a large digital marketing platform, adapting content from pharma companies to fit our platform. Medical writers work in regulatory, clinical, and marketing fields and I’m in marketing. I got my current contract job just 2 years ago, back when you could get this job with just a BA/BS.
In the last 2 years the market has changed drastically. My hours have been cut from nearly full time up to March ‘24 to 4-5 a month now if I’m lucky. I’ve been applying for new jobs for over a year and have had barely a nibble.
The trend now seems to be to have AI produce content, and then hire professionals with advanced degrees to check it over. And paying them less per hour than I make now when I actually work.
I am no longer qualified to do the job I’ve been doing, which is really frustrating. I’m trying to find a new career, trying to start over at age 50.
—Anonymous
We learned our work had been used to train LLMs and our jobs were outsourced to India
Editor for Gracenotes
So I lost my previous job to AI, and a lot of other things. I always joke that the number of historical trends that led to me losing it is basically a summary of the recent history of Western Civilization.
I used to be a schedule editor for Gracenote (the company that used to find metadata for CDs that you ripped into iTunes). They got bought by Nielsen, the TV ratings company, and then tasked with essentially adding metadata to TV guide listings. When you hit the info button on your remote, or when you Google a movie and get the card, a lot of that is Gracenote. The idea was that we could provide accurate, consistent, high-quality text metadata that companies could buy to add to their own listings. There’s a specific style of Gracenote Description Writing that still sticks out to me every time I see it.
So, basically from when I joined the company in late 2021 things were going sideways. I’m based in the Netherlands and worker protections are good, but we got horror stories of whole departments in the US showing up, being called into a “town hall” and laid off en-masse, so the writing was on the wall. We unionised, but they seemed to be dragging their feet on getting us a CAO (Collective Labour Agreement) that would codify a lot of our benefits.
The way the job worked was each editor would have a group of TV channels they would edit the metadata for. My team worked on the UK market, and a lot of us were UK transplants living in the NL. During my time there I did a few groups but, being Welsh, I eventually ended up with the Welsh, Irish and Scottish channels like S4C, RTE, BBC Alba. The two skills we were selling to the company were essentially: knowledge of the UK TV market used to prioritise different shows, and a high degree of proficiency in written English (and I bet you think you know why I lost the job to AI, but hold on).
Around January 2024 they introduced a new tool in the proprietary database we used, that totally changed how our work was done. Instead of channel groups that we prioritised ourselves, instead we were given an interface that would load 10 or so show records from any channel group, which had been auto-sorted by priority. It was then revealed to us that for the last two years or so, every single bit of our work in prioritisation had been fed into machine learning to try and work out how and why we prioritised certain shows over others.
“Hold on” we said, “this kind of seems like you’ve developed a tool to replace us with cheap overseas labour and are about to outsource all our jobs”
“Nonsense,” said upper management, “ignore the evidence of your lying eyes.”
That is, of course, what they had done.
They had a business strategy they called “automation as a movement” and we assumed they would be introducing LLMs into our workflow. But, as they openly admitted when they eventually told us what they were doing, LLMs simply weren’t (and still aren’t) good enough to do the work of assimilating, parsing and condensing the many different sources of information we needed to do the job. Part of it was accuracy, we would often have to research show information online and a lot of our job amounted to enclosing the digital commons by taking episode descriptions from fanwikis and rewriting them; part of it was variety, the information for the descriptions was ingested into our system in many different ways including press sites, press packs from the channels, emails, spreadsheets, etc etc and “AI” at the time wasn’t up to the task. The writing itself would have been entirely possible, it was already very formulaic, but getting the information to the point it was writable by an LLM was so impractical as to be impossible.
So they automated the other half of the job, the prioritisation. The writing was outsourced to India. As I said at the start, there’s a lot of historical currents at play here. Why are there so many people in India who speak and write English to a high standard? Don’t worry about it!
And, the cherry on the cake, both the union and the works council knew this would be happening, but were legally barred from telling us because of “competitive advantage”. They negotiated a pretty good severance package for those of us on “vastcontracts” (essentially permanent employees, as opposed to time-limited contracts) but it still saw a team of 10 reduced to 2 in the space of a month.
—Anonymous
Coworkers told me to my face that AI could and maybe should be doing all my work
Nonprofit communications worker
I currently work in nonprofit communications, and worked as a radio journalist for about four years before that. I graduated college in 2020 with a degree in music and broadcasting.
In my current job, I hear about the benefits of AI on a weekly basis. Unfortunately, those benefits consist of doing tasks that are a part of my direct workload. I’m already struggling to handle the amount of downtime that I have, as I had worked in the always-behind-schedule world of journalism before this (in fact, I am writing this on the clock right now). My duties consist mainly of writing for and putting together weekly and quarterly newsletters and writing our social media.
After a volunteer who recorded audio versions of our newsletters passed away suddenly, it was brought up in a meeting two hours after we heard the news that AI should be the one to create the audio versions going forward. I had to remind them that I am in fact an award-winning radio journalist and audio producer (I produce a few podcasts on a freelance basis, some of which are quite popular) and that I already have little work to do and would be able to take over those duties. After about two weeks of fighting, it was decided that I would be recording those newsletters. I also make sure our website is up-to-date on all of our events and community outings. At some point, I stopped being asked to write blurbs about the different events and I learned that this task was now being done by our IT Manager using AI to write those blurbs instead. They suck, but I don’t get to make that distinction. It has been brought up more than once that our social media is usually pretty fact-forward, and could easily be written by AI. That might be true, but it is also about half of my already very light workload. If I lost that, I would have very little to do. This has not yet been decided.
I have been told (to my face!) by my coworkers that AI could and maybe should be doing all of my work. People who are otherwise very progressive leaning seem to see no problem with me being out of work. While it was a win for me to be able to record the audio newsletters, I feel as if I am losing the battle for the right to do what I have spent the last five years of my life doing. I am 30 and making pennies, barely able to afford a one-bedroom apartment, while logging three-to-four hours of solitaire on my phone every day. This isn’t what I signed up for in life. My employers have given me some new work to do, but that is mostly planning parties and spreading cheer through the workplace, something I loathe and was never asked to do. There are no jobs in my field in my area.
If things keep progressing at this rate… I’ll be nothing but a party planner. I don’t even like parties. Especially not for people who think I should be out of a job.
I have seen two postings in the past six months for communications jobs that pay enough for me to continue living in my apartment. I got neither of them.
While I am still able to write my newsletter articles, those give me very little joy and if things keep progressing at this rate I won’t even have those. I’ll be nothing but a party planner. I don’t even like parties. Especially not for people who think I should be out of a job.
At this rate, I have seen little pushback from my employer about having AI do my entire job. Even if I think this is a horrible idea, as the topics I write about are often sensitive and personal, I have no faith that they will not go in this direction. At this point, I am concerned about layoffs and my financial future.
[We checked in with the contributor a few weeks after he reached out to us and he gave us this update:]
I am now being sent clearly AI written articles from heads of other departments (on subjects that I can and will soon be writing about) for publication on our website. And when I say “clearly AI,” I mean I took one look and knew immediately and was backed up by an online AI checker (which I realize is not always accurate but still). The other change is that the past several weeks have taught me that I don’t want to be a part of this field any longer. I can find another comms job, and actually have an interview with another company tomorrow, but have no reason to believe that they won’t also be pushing for AI at every turn.
—Anonymous
I’m a copywriter by trade. These days I do very little
Copywriter
I’m a copywriter by trade. These days I do very little. The market for my services is drying up rapidly and I’m not the only one who is feeling it. I’ve spoken to many copywriters who have noticed a drop in their work or clients who are writing with ChatGPT and asking copywriters to simply edit it.
I have clients who ask me to use AI wherever I can and to let them know how long it takes. It takes me less time and that means less money.
Some copywriters have just given up on the profession altogether.
I have been working with AI for a while. I teach people how to use it. What I notice is a move towards becoming an operator.
I craft prompts, edit through prompts and add my skills along the way (I feel my copywriting skills mean I can prompt and analyse output better than a non-writer). But writing like this doesn’t feel like it used to. I don’t go through the full creative process. I don’t do the hard work that makes me feel alive afterwards. It’s different, more clinical and much less rewarding.
I don’t want to be a skilled operator. I want to be a human copywriter. Yet, I think these days are numbered.
—Anonymous
I did “adapt or die” using AI, but I’m still in a precarious position
Ghostwriter
From 2010-today I worked as a freelance writer in two capacities: freelance journalism for outlets like Cannabis Now, High Times, Phoenix New Times, and The Street, and ghostwriting through a variety of marketplaces (elance, fiverr, WriterAccess, Scripted, Crowd Content) and agencies (Volume 9, Influence & Co, Intero Digital, Cryptoland PR).
The freelance reporting market still exists but is extremely competitive and pretty poorly paid. So I largely made my living ghostwriting to supplement income. The marketplaces all largely dried up unless you have a highly ranked account. I do not because I never wanted to grind through the low paid work long enough. I did attempt to use ChatGPT for low-paid WriterAccess jobs but got declined.
Meanwhile, my steadiest ghostwriting client was Influence & Co/Intero Digital. Through this agency, I have ghostwritten articles for nearly everyone you can think of (except Vox/Verge): NYT, LA Times, WaPo, WSJ, Harvard Business Review, Venture Beat, HuffPost, AdWeek, and so many more. And I’ve done it for execs for large tech companies, politicians, and more. The reason it works is because they have guest posts down to a science.
They built a database of all publisher’s guidelines. If I wanted to be in HBR, I knew the exact submission guidelines and could pitch relevant topics based on the client. Once the pitch is accepted, an outline is written, and the client is interviewed. This interview is crucial because it’s where we tap into the source and gain firsthand knowledge that can’t be found online. It also gets the client’s natural voice. I then combine the recorded interview with targeted online research to find statistics and studies to back up what the client says, connect it to recent events, and format to the publisher’s specs.
So ChatGPT came along December 2022, and for most of 2023 things were fine, although Influence & Co was bought by Intero, so internal issues were arising. I was with this company from the start when they were emailing word docs through building the database and selling the company several times. I can go on and on about how it all works.
We as writers don’t use ChatGPT, but it still seeped into the workflow from the client. The client interview I mentioned above as being vital because it gets info you can’t get online and their voice and everything you need to do it right—well those clients started using ChatGPT. By the end of 2023, I couldn’t handle it anymore because my job fundamentally changed. I was no longer learning anything. That vital mix that made it work was gone, and it was all me combining ChatGPT and the internet to try and make it fit into those publications above, many of which implemented AI detection, started publishing their own AI articles, and stopped accepting outside contributions.
I could probably write a book about the backend of all this stuff and how guest posts end up on every media outlet on the planet. Either way, ChatGPT ruined it
The thing about writing in this instance is that it doesn’t matter how many drafts you write, if it doesn’t get published in an acceptable publication, then it looks like we did nothing. What was steady work for over a decade slowed to a trickle, and I was tired of the work that was coming in because it was so bad.
Last summer, I emailed them and quit. I could no longer depend on the income. It was $1500-$3000 a month for over a decade and then by 2024 was $100 a month. And I hated doing it. It was the lowest level bs work I hated so much. I loved that job because I learned so much and I was challenged trying to get into all those publications, even if it was a team effort and not just me. I wrote some killer articles that ChatGPT could never. And the reason AI took my job is because clients who hired me for hundreds to thousands of dollars a month decided it’s not worth their time to follow our process and instead use ChatGPT.
That is why I think it’s important to talk about. I probably could still be working today in what became a content mill. And the reason it ultimately became no longer worth it isn’t all the corporate changes. It wasn’t my boss who was using AI—it was our customers. Working with us was deemed not important, and it’s impossible to explain to someone in an agency environment that they’re doing it to themselves. They will just go to a different agency and keep trying, and many of the unethical ones will pull paid tricks that make it look more successful than it is, like paying Entrepreneur $3000 for a year in their leadership network. (Comes out to paying $150 per published post, which is wild considering the pay scale above).
The whole YEC publishing conglomerate is another rabbit hole. Forbes, CoinTelegraph, Newsweek, and others have the same paid club structure that happens to come with guest post access. And those publishers allow paid marketing in the guise of editorials.
I could probably write a book about the backend of all this stuff and how guest posts end up on every media outlet on the planet. Either way, ChatGPT ruined it, and I’m largely retired now. I am still doing some ghostwriting, but it’s more in the vein of PR and marketing work for various agencies I can find that need writers. The market still exists, even if I have to work harder for clients.
And inexplicably, the reason we met originally was because I was involved in the start of Adobe Stock accepting AI outputs from contributors. I now earn $2500 per month consistently from that and have a lot of thoughts about how as a writer with deep inside knowledge of the writing industry, I couldn’t find a single way to “adapt or die” and leverage ChatGPT to make money. I could probably put up a website and build some social media bots. But plugging AI into the existing industry wasn’t possible. It was already competitive. Yet I somehow managed to build a steady recurring residual income stream selling Midjourney images on Adobe stock for $1 a piece. I’m on track to earn $30,000 this year from that compared to only $12,000 from writing. I used to earn $40,000-$50,000 a year doing exclusively writing from 2011-2022.
I did “adapt or die” using AI, but I’m still in a precarious position. If Adobe shut down or stopped accepting AI, I’ll be screwed. It doesn’t help that I’m very vocally against Adobe and called them out last year via Bloomberg for training firefly on Midjourney outputs when I’m one of the people making money from it. I’m fascinated to learn how the court cases end up and how it impacts my portfolio. I’m currently working to learn photography and videography well enough to head to Vegas and LA for conferences next year to build a real editorial stock portfolio across the other sites.
So my human writing job was reduced below a living wage, and I have an AI image portfolio keeping me afloat while I try to build a human image/video portfolio faster than AI images are banned. Easy peasy right?
–Brian Penny
The agency was begging me to take on more work. Then it had nothing for me
Freelance copywriter
I was a freelance copywriter. I am going to be fully transparent and say I was never one of those people that hustled the best, but I had steady work. Then AI came and one of the main agencies that I worked for went from begging me to take on more work to having 0 work for me in just 6-8 months. I struggled to find other income, found another agency that had come out of the initial AI hype and built a base of clients that had realized AI was slop, only for their customer base to be decimated by Trump’s tariffs about a month after I joined.
What I think people fail to realize when they talk about AI is that this is coming on the tail end of a crisis in employment for college grads for years. I only started freelancing because I applied to hundreds of jobs after winding up back at my mom’s house during COVID-19. Anecdotally, most of my friends that I graduated with (Class of 2019) spent years struggling to find stable, full-time jobs with health insurance, pre-AI. Add AI to the mix, and getting your foot in the door of most white collar industries just got even harder.
As I continue airing my grievances in your email, I remember when ChatGPT first came out a lot of smug literary types on Twitter were saying “if your writing can be replaced by AI then it wasn’t good to begin with,” and that made me want to scream. The writing that I’m actually good at was the writing that nobody was going to pay me for because the media landscape is decimated!
Content writing/copywriting was supposed to be the way you support yourself as an artist, and now even that’s gone.
—Rebecca Duras
My biggest client replaced me with a custom GPT. They surely trained it using my work
Copywriter and Marketing Consultant
I am a long-time solopreneur and small business owner, who got into the marketing space about 8 years ago. This career shift was quite the surprise to me, as for most of my career I didn’t like marketing…or marketers. But here we are ;p
While I don’t normally put it in these terms, what shifted everything for me was realizing that copywriting was a thing — it could make a huge difference in my business and for other businesses, too. With a BA in English, and after doing non-marketing writing projects on the side for years, it just made a ton of sense to me that the words we use to talk about our businesses can make a big difference. I was hooked.
After pursuing some training, I had a lucrative side-hustle doing strategic messaging work and website copy for a few years before jumping into full-time freelancing in 2021. The work was fun, the community of marketers I was a part of was amazing, and I was making more money than I ever could have in my prior business.
And while the launch of ChatGPT in Nov ‘22 definitely made many of us nervous — writing those words brings into focus how stressful the existential angst has actually been since that day — for me and many of my copywriting friends, the good times just kept rolling. 2023 was my best year ever in business — by a whopping 30%. I wasn’t alone. Many of my colleagues were also killing it.
All of that changed in 2024.
Early that year, the AI propaganda seemed to hit its full crescendo, and it started significantly impacting my business. I quickly noticed leads were down, and financially, things started feeling tight. Then, that spring, my biggest retainer client suddenly gave me 30-days notice that they wouldn’t renew my contract — which made up half of what I needed to live on. The decision caught everyone, including the marketing director, off guard. She loved what I was doing for them and cried when she told me the news. I later found out through the grapevine that the CEO and his right hand guy were hoping to replace me with a custom GPT they had created. They surely trained it using my work.
The AI-related hits kept coming. The thriving professional community I enjoyed pretty much imploded that summer – largely because of some unpopular leadership decisions around AI. Almost all of my skilled copywriter friends left the organization — and while I’ve lost touch with most, the little I have heard is that almost all of them have struggled. Many have found full-time employment elsewhere.
I won’t go into all the ins-and-outs of what has happened to me since, and I’ll leave my rant about getting AI slop from my clients to “edit” alone. (Briefly, that task is beyond miserable.)
But I will say from May of 2024 to now, I’ve gone from having a very healthy business and amazing professional community, to feeling very isolated and struggling to get by. Financially, we’ve burned through $20k in savings and almost $30k in credit cards at this point. We’re almost out of cash and the credit cards are close to maxed. Full-time employment that’d pay the bills (and get us out of our hole) just isn’t there. Truthfully, if it wasn’t for a little help from some family – and basically being gifted two significant contracts through a local friend – we’d be flat broke with little hope on the horizon. Despite our precarious position, continuing to risk freelance work seems to be our best and pretty much only option.
I do want to say, though, that even though it’s bleak, I see some signs for hope. In the last few months, in my experience many business owners are waking up to the fact that AI can’t do what it claims it can. Moreover, with all of the extra slop around, they’re feeling even more overwhelmed – which means if you can do any marketing strategy and consulting, you might make it.
But while I see that things might be starting to turn, the pre-AI days of junior copywriting roles and freelancers being able making lots of money writing non-AI content seem to be long gone. I think those writers who don’t lean on AI and find a way to make it through will be in high-demand once the AI-illusion starts to lift en masse. I just hope enough business owners who need marketing help wake up before then so that more of us writers don’t have to starve.
In China, parents are buying smartwatches for children as young as 5, connecting them to a digital world that blends socializing with fierce competition.
Photo-Illustration: WIRED Staff; Getty Images
At what age should a kid ideally get a smartwatch? In China, parents are buying them for children as young as five. Adults want to be able to call their kids and track their location down to a specific building floor. But that’s not why children are clamoring for the devices, specifically ones made by a company called Xiaotiancai, which translates to Little Genius in English.
The watches, which launched in 2015 and cost up to $330, are a portal into an elaborate world that blends social engagement with relentless competition. Kids can use the watches to buy snacks at local shops, chat and share videos with friends, play games, and, sure, stay in touch with their families. But the main activity is accumulating as many “likes” as possible on their watch’s profile page. On the extreme end, Chinese media outlets have reported on kids who buy bots to juice their numbers, hack the watches to dox their enemies, and sometimes even find romantic partners. According to tech research firm Counterpoint Research, Little Genius accounts for nearly half of global market share for kids’ smartwatches.
Status Games
Over the past decade, Little Genius has found ways to gamify nearly every measurable activity in the life of a child—playing ping pong, posting updates, the list goes on. Earning more experience points boosts kids to a higher level, which increases the number of likes they can send to friends. It’s a game of reciprocity—you send me likes, and I’ll return the favor. One 18-year-old recently told Chinese media that she had struggled to make friends until four years ago when a classmate invited her into a Little Genius social circle. She racked up more than one million likes and became a mini-celebrity on the platform. She said she met all three of her boyfriends through the watch, two of whom she broke up with because they asked her to send erotic photos.
High like counts have become a sort of status symbol. Some enthusiastic Little Genius users have taken to RedNote (or Xiaohongshu), a prominent Chinese social media app, to hunt for new friends so as to collect more likes and badges. As video tutorials on the app explain, low-level users can only give out five likes a day to any one friend; higher-ranking users can give out 20. Because the watch limits its owner to a total of 150 friends, kids are therefore incentivized to maximize their number of high-level friends. Lower-status kids, in turn, are compelled to engage in competitive antics so they don’t get dumped by higher-ranking friends.
“They feel this sense of camaraderie and community,” said Ivy Yang, founder of New York-based consultancy Wavelet Strategy, who has studied Little Genius. “They have a whole world.” But Yang expressed reservations about the way the watch seems to commodify friendship. “It’s just very transactional,” she adds.
Engagement Hacks
On RedNote/Xiaohongshu, people post videos on circumventing Little Genius’s daily like limits, with titles such as “First in the world! Unlimited likes on Little Genius new homepage!” The competitive pressure has also spawned businesses that promise to help kids boost their metrics. Some high-ranking users sell their old accounts. Others sell bots that send likes or offer to help keep accounts active while the owner of a watch is in class.
Get enough likes—say, 800,000—and you become a “big shot” in the Little Genius community. Last month, a Chinese media outlet reported that a 17-year-old with more than 2 million likes used her online clout to sell bots and old accounts, earning her more than $8,000 in a year. Though she enjoyed the fame that the smartwatch brought her, she said she left the platform after getting into fights with other Little Genius “big shots” and facing cyberbullying.
In September, a Beijing-based organization called China’s Child Safety Emergency Response warned parents that children with Little Genius watches were at risk of developing dangerous relationships or falling victim to scams. Officials have also raised alarms about these hidden corners of the Little Genius universe. The Chinese government has begun drafting national safety standards for children’s watches, following growing concerns over internet addiction, content unfit for children, and overspending via the watch payment function. The company did not respond to requests for comment.
I talked to one parent who had been reluctant to buy the watch. Lin Hong, a 48-year-old mom in Beijing, worried that her nearsighted daughter, Yuanyuan, would become obsessed with its tiny screen. But once Yuanyuan turned 8, Lin relented and splurged on the device. Lin’s fears quickly materialized.
Yuanyuan loved starting her day by customizing her avatar’s appearance. She regularly sent likes to her friends and made an effort to run and jump rope to earn more points. “She would look for her smartwatch first thing every morning,” Lin said. “It was like adults, actually, they’re all a bit addicted.”
To curb her daughter’s obsession, Lin limited Yuanyuan’s time on the watch. Now she’s noticing that her daughter, who turns 9 soon, chafes at her mother’s digital supervision. “If I call her three times, she’ll finally pick up to say, ‘I’m still out, stop calling. I’m not done playing yet,’ and hang up,” Lin said. “If it’s like this, she probably won’t want to keep wearing the watch for much longer.”
AI isn’t coming—it’s here. Today’s STEM students aren’t fighting it; they’re learning to read it, question it, and use it. The new skill isn’t coding the machine, but understanding its logic well enough to steer it.
A degree in computer science used to promise a cozy career in tech. Now, students’ ambitions are shaped by AI, in fields that blend computing with analysis, interpretation, and data.
In the early 2010s, nearly every STEM-savvy college-bound kid heard the same advice: Learn to code. Python was the new Latin. Computer science was the ticket to a stable, well-paid, future-proof life.
But in 2025, the glow has dimmed. “Learn to code” now sounds a little like “learn shorthand.” Teenagers still want jobs in tech, but they no longer see a single path to get there. AI seems poised to snatch up coding jobs, and there aren’t a plethora of AP classes in vibe coding. Their teachers are scrambling to keep up.
“There’s a move from taking as much computer science as you can to now trying to get in as many statistics courses” as possible, says Benjamin Rubenstein, an assistant principal at New York’s Manhattan Village Academy. Rubenstein has spent 20 years in New York City classrooms, long enough to watch the “STEM pipeline” morph into a network of branching paths instead of one straight line. For his students, studying stats feels more practical.
Forty years ago, students inspired by NASA dreamed of becoming physicists or engineers. Twenty years after that, the allure of jobs at Google or other tech giants sent them into computer science. Now, their ambitions are shaped by AI, leading them away from the stuff AI can do (coding) and toward the stuff it still struggles with. As the number of kids seeking computer science degrees falters, STEM-minded high schoolers are looking at fields that blend computing with analysis, interpretation, and data.
Rubenstein still requires every student to take computer science before graduation, “so they can understand what’s going on behind the scenes.” But his school’s math department now pairs data literacy with purpose: an Applied Mathematics class where students analyze New York Police Department data to propose policy changes, and an Ethnomathematics course linking math to culture and identity. “We don’t want math to feel disconnected from real life,” he says.
It’s a small but telling shift—one that, Rubenstein says, isn’t happening in isolation. After a long boom, universities are seeing the computer-science surge cool. The number of computer science, computer engineering, and information degrees awarded in the 2023–2024 academic year in the US and Canada fell by about 5.5 percent from the previous year, according to a survey by the nonprofit Computing Research Association.
At the high school level, the appetite for data is visible. AP Statistics logged 264,262 exam registrations in 2024, making it one of the most-requested AP tests, per Education Week. AP computer-science exams still draw big numbers—175,261 students took AP Computer Science Principles, and 98,136 took AP Computer Science A in 2024—but the signal is clear: Data literacy now sits alongside coding, not beneath it.
“Students who see themselves as STEM people will pursue whatever they think makes them a commodity, something valued in the workplace,” Rubenstein says. “The workplace can basically shift education if it wants to by saying, ‘Here’s what we need from students.’ K–12 will follow suit.”
Amid all this, AI’s rise leaves teachers in a difficult position. They’re trying to prepare students for a future defined by machine learning while managing how easily those same tools can short-circuit the learning process.
Yet Rubenstein believes AI could become a genuine ally for STEM educators, not a replacement. He imagines classrooms where algorithms help teachers identify which students grasp a concept and which need more time, or suggest data projects aligned with a student’s interests—ways to make learning more individualized and applied.
It’s part of the same shift he’s seen in his students: a move toward learning how to interpret and use technology, not just build it. Other educators are starting to think along similar lines, exploring how AI tools might strengthen data literacy or expand access to personalized STEM instruction.
At the University of Georgia, science education researcher Xiaoming Zhai is already testing what that could look like. His team builds what he calls “multi-agent classroom systems,” AI assistants that interact with teachers and students to model the process of scientific inquiry.
Zhai’s projects test a new kind of literacy: not just how to use AI but how to think with it. He tells the story of a visiting scholar who had never written a line of code yet used generative AI to build a functioning science simulation.
“The bar for coding has been lowered,” he says. “The real skill now is integrating AI with your own discipline.”
Zhai believes AI shouldn’t be treated as an amalgamation of STEM disciplines but as part of its core. The next generation of scientists, he says, will use algorithms the way their predecessors used microscopes—to detect patterns, test ideas, and push the boundaries of what can be known. Coding is no longer the frontier; the real skill is learning how to interpret and collaborate with machine intelligence. As chair of a national committee on AI in science education, Zhai is pushing to make that shift explicit, urging schools to teach students to harness AI’s precision while staying alert to its blind spots.
“AI can do some work humans can’t,” he says, “but it also fails spectacularly outside its training data. We don’t want students who think AI can do everything or who fear it completely. We want them to use it responsibly.”
That balance between fluency and skepticism, ambition and identity, is quietly rewriting what STEM means in schools like Rubenstein’s. Computer-science classes aren’t going away, but they’re sharing the stage with forensics electives, science-fiction labs and data-ethics debates.
“Students can’t think of things as compartmentalized anymore,” Rubenstein says. “You need multiple disciplines to make good decisions.”
AI isn’t coming—it’s here. Today’s STEM students aren’t fighting it; they’re learning to read it, question it, and use it. The new skill isn’t coding the machine, but understanding its logic well enough to steer it.
OpenAI said it will allow users in the U.S. to make purchases directly through ChatGPT using a new Instant Checkout feature powered by a payment protocol for AI co-developed with Stripe.
The new chatbot shopping feature is a big step toward helping OpenAI monetize its 700 million weekly users, many of whom currently pay nothing to interact with ChatGPT, as well as a move that could eventually steal significant market share from traditional Google search advertising.
The rollout of chatbot shopping features—including the possibility of AI agents that will shop on behalf of users—could also upend e-commerce, radically transforming the way businesses design their websites and try to market to consumers.
OpenAI said it was rolling out its Instant Checkout feature with Etsy sellers today, but would begin adding over a million Shopify merchants, including brands such as Glossier, Skims, Spanx, and Vuori “soon.”
The company also said it was open-sourcing the Agentic Commerce Protocol, a payment standard developed in partnership with payments processor Stripe that powers the Instant Checkout feature, so that any retailer or business could decide to build a shopping integration with ChatGPT. (Stripe’s and OpenAI’s commerce protocol, in turn, supports the open-source Model Context Protocol, or MCP, that was originally developed by AI company Anthropic last year. MCP is designed to allow AI models to directly hook into the backend systems of businesses and retailers. The new Agentic Commerce Protocol also supports more conventional API calls too.)
OpenAI will take what it described as small fee from the merchant on each purchase, helping to bolster the company’s revenue at a time when it is burning through many billions of dollars each year to train and support the running of its AI models.
How it works
OpenAI had previously launched a shopping feature in ChatGPT that helped users find products that were best suited to them, but the suggested results then linked out to merchants’ websites, where a user had to complete the purchase—analogous to the way a Google search works.
When a ChatGPT user asks a shopping-related question—such as “the best hiking boots for me that cost under $150” or “possible birthday gifts for my 10-year old nephew”—the chatbot will still respond with product suggestions. Under the new system, if a user likes one of the suggestions and Instant Checkout is enabled, they will be able to click a “Buy” button in the chatbot response and confirm their order, shipping, and payment details without ever leaving the chat.
OpenAI said its “product results are organic and unsponsored, ranked purely on relevance to the user.” The company also emphasized that the results are not affected by the fee the merchant pays it to support Instant Checkout.
Then, to determine which merchants that carry that particular product should be surfaced for the user, “ChatGPT considers factors like availability, price, quality, whether a merchant is the primary seller, and whether Instant Checkout is enabled,” when displaying results, the company said.
OpenAI said that ChatGPT subscribers, who pay a monthly fee for premium features, would be able to use the same credit or debit card to which they charge their subscription or store alternate payment methods to use.
OpenAI’s decision to launch the shopping feature using Stripe’s Agentic Commerce Protocol will be a big boost for that payment standard, which can be used across different AI platforms and also works with different payment processors—although it is easier to integrate for existing Stripe customers. The protocol works by creating an encrypted token for payment details and other sensitive data.
Currently, OpenAI says that the user remains in control, having to explicitly agree to each step of the purchasing process before any action is taken. But it is easy to imagine that in the future, users may be able to authorize ChatGPT or other AI models to act more “agentically” and actually make purchases for the user based on a prompt, without having to check back in with a user.
The fact that users never have to leave the chat interface to make the purchase may pose a challenge to Alphabet’s Google, which makes most of its money by referring users to companies’ websites. Although Google may be able to roll out similar shopping features within its Gemini chatbot or “AI Mode” in Google Search, it’s unclear whether what it could charge for transactions completed in these AI-native ways would compensate for any loss in referral revenue and what the opportunities would be for the display of other advertising around chatbot queries.
Googles search engine and the Browser Google Chrome could have been far better products if it wasn’t beholden to Google’s other business interests:
They allege that Google blocked the introduction of user-friendly features because they would have harmed the company’s advertising revenue, which depends on people clicking ads in their search results. “Why isn’t autocomplete better? Why isn’t the ‘new tab’ page more effective? Why isn’t browser history better?” says the ex-leader, who also spoke on the condition of anonymity. The answer: “There’s all these incentives to get users to search.”
Google Selling Chrome Won’t Be Enough to End Its Search Monopoly
To dismantle Google’s illegal monopoly over how Americans search the web, the US Department of Justice wants the tech giant to end its lucrative partnership with Apple, share a trove of proprietary data with competitors and advertisers, and “promptly and fully divest Chrome,” Google’s browser that controls more than half of the US market. The government also wants approval regarding who takes over Chrome.
The recommendations are part of a detailed plan that government attorneys submitted Wednesday to US district judge Amit Mehta in Washington, DC, as part of a federal antitrust case against Google that started back in 2020. By next August, Mehta is expected to decide which of the possible remedies Google will be required to carry out to loosen its stranglehold on the search market.
AI Lab Newsletter by Will Knight
WIRED’s resident AI expert Will Knight takes you to the cutting edge of this fast-changing field and beyond—keeping you informed about where AI and technology are headed. Delivered on Wednesdays.
But the tech giant could still appeal, delaying enforcement of the judge’s order years into the future. On Wednesday, Google president Kent Walker characterized the government’s proposals as “staggering,” “extreme,” “a radical interventionist agenda,” and “wildly overbroad.” He wrote in a blog post that the changes being sought “would break a range of Google products—even beyond Search—that people love and find helpful in their everyday lives.” He also asserted the privacy and security of Google’s users would be put at risk.
Among people who have worked for Google or partnered closely with the company, there’s little agreement on whether any of the proposed remedies would significantly shift user behavior or make the search engine market more competitive. Four former Google executives who oversaw teams working on Chrome, Search, and Ads told WIRED that innovation by rivals, not interventions by the government, remains the surest way to unseat Google as the nation’s dominant internet search provider. “You can’t ram an inferior product down people’s throats,” says one former Chrome business leader, speaking on the condition of anonymity to protect professional relationships.
But a former Chrome engineering leader acknowledged that the search engine could have been a better product if it wasn’t beholden to Google’s other business interests. They allege that Google blocked the introduction of user-friendly features because they would have harmed the company’s advertising revenue, which depends on people clicking ads in their search results. “Why isn’t autocomplete better? Why isn’t the ‘new tab’ page more effective? Why isn’t browser history better?” says the ex-leader, who also spoke on the condition of anonymity. The answer: “There’s all these incentives to get users to search.” Google didn’t respond to a request for comment on the assertion.
Still, competitors that stand to benefit from even a minor reduction in Google’s power are optimistic about the expected remedies. “I can see strong benefits in putting [Chrome] back in the hands of the community,” says Guillermo Rauch, CEO of Vercel, a company that develops tools for websites, many of which depend on search traffic and advertising revenue controlled by Google. “Moderating that relationship to the corporate overlords is always going to be a healthy thing,” Rauch says.
Gabriel Weinberg, CEO of the rival search engine DuckDuckGo, said in a statement that the government’s proposed remedies “would free the search market from Google’s illegal grip and unleash a new era of innovation, investment, and competition.”
Google’s antitrust battle with the Department of Justice began under the first Trump administration in 2020. The federal government, as well as a number of states, accused the tech giant of using anticompetitive tactics to dominate the search market, suppressing Americans’ access to other search providers. The Biden administration moved forward with the case and filed another of its own—accusing Google of illegally monopolizing advertising technologies that millions of websites and apps use to generate revenue. Closing arguments in that case are scheduled for Monday.
Both cases remain unresolved, and it’s unclear to what extent the Justice Department will keep up the pressure on Google after Donald Trump returns to the White House. On the campaign trail, Trump made mixed comments about the tech giant. In October, he expressed concerns about its power, but suggested that imposing onerous conditions on the company could hamper US efforts to achieve tech supremacy over China.
Judge Mehta has set aside nearly two weeks starting in April to hear arguments from the government and Google about the proposed punishments. The new Trump administration’s approach toward Google should become more apparent at that point, and it’s possible that government attorneys will be less willing to defend the proposals released Wednesday.
Walker’s blog on Wednesday highlighted possible ramifications of the proposals that Trump may view as concerning, including the chilling of AI investment and the appointment of a five-expert Technical Committee to monitor Google’s compliance with remedies. “And that’s just a small part of it,” Walker wrote about the proposed panel. “We wish we were making this up.”
The government is seeking to provide users with more choice over what search engines they use. It wants to end Google’s partnership with Apple, which receives tens of billions of dollars in search ad revenue for making Google the default search engine on iPhones. Google has similar deals with other companies, which also would be scuttled.
Google would also have to make changes to how it preferences its own services on Android or else sell, or be forced to sell, Android. The proposals call for Google to give advertisers a stream of data to help them study their purchases.
To give competitors a leg up, the government wants Google to share its search index and the data it collects about users when determining which results to show. The argument is that potential rivals would then be able to match the information advantage Google has amassed over decades studying the behavior patterns of its billions of users. In addition, Colorado’s attorney general proposed in Wednesday’s filing that Google fund “reasonable, short-term incentive payments” to users who opt for non-Google default search engines.
On top of having to divest of Chrome, Google would be banned from launching a new browser or investing in search, ad tech, and AI rivals for five to 10 years. The government says the restrictions would enable “fostering innovation and transforming the general search and search text ads markets over the next decade.”
Rauch, the Vercel CEO, believes that Google is unfairly using Chrome to direct people toward its AI chatbot, Gemini, as well as other services it owns, such as Google Docs, through a mix of nudges and incentives built into its search engine. “Google is stacking every advantage that they can by monopolizing this very important piece of software infrastructure,” Rauch says.
Turning over Chrome to a neutral steward like a nonprofit organization or an academic institution, Rauch says, would burst open the search box on the world’s most popular browser and give people access to a plethora of alternatives. Chrome already allows users to change their default search provider, but Google still nudges users back through alerts as they browse. “I could imagine, in a world where people are more equipped to choose rather than default, a lot of consumers might end up choosing Perplexity or ChatGPT, whereas today it’s a very roundabout thing,” Rauch says.
But financial and legal analysts have expressed doubts about how much the government’s proposals could really achieve. The former Google executives who spoke with WIRED are just as skeptical. Rajen Sheth, who oversaw parts of the Chrome business and now runs a software startup for building online courses, says users are gravitating toward what they are used to in what he believes is already an open marketplace. “Given the technology landscape and the different levers, are there things that will make a difference? It will be tough,” he says.
Getting access to Google’s proprietary data and having the opportunity to court iPhone users may help increase the odds that people turn to alternative search engines. But Google also has unmatched computing infrastructure, unique data from sibling services such as Maps, and more than a quarter-century of brand recognition with consumers. “No matter how much you level the playing field, people are going to go to the best product for the job,” the former Chrome business leader says.
Former Google executives say that what will supplant the company one day isn’t another traditional search engine, but something akin to ChatGPT that presents content to users in a more interactive way. That new technology isn’t fully developed yet, but it might be by the time the government’s lawsuit against Google is finally settled. That means Google’s place in the market could look vastly different before enforcement of the judge’s order even begins.
“I was too poor,” he said. “And then I was too rich.”
In fact, Mr. Karp, a co-founder and the C.E.O. of Palantir Technologies, the mysterious and powerful data analytics firm, doesn’t trust himself to drive. Or ride a bike. Or ski downhill.
“I’m a dreamer,” he said. “I’ll start dreaming and then I fall over. I started doing tai chi to prevent that. It’s really, really helped with focusing on one thing at a time. If you had met me 15 years ago, two-thirds of the conversation, I’d just be dreaming.”
What would he dream about?
“Literally, it could be a walk I did five years ago,” he said. “It could be some conversation I had in grad school. Could be my family member annoyed me. Something a colleague said, like: ‘Why did they say this? What does it actually mean?’”
Mr. Karp is a lean, extremely fit billionaire with unruly salt-and-pepper curls. He is introvert-charming (something I aspire to myself). He has A.D.H.D. and can’t hide it if he is not interested in what someone is saying. After a hyper spurt of talking, he loses energy and has to recharge on the stationary bike or by reading. Even though he thinks of himself as different, he seems to like being different. He enjoys being a provocateur onstage and in interviews.
“I’m a Jewish, racially ambiguous dyslexic, so I can say anything,” he said, smiling.
Unlike many executives in Silicon Valley, Mr. Karp backed President Biden, cutting him a big check, despite skepticism about his handling of the border and his overreliance on Hollywood elites like Jeffrey Katzenberg. Now he is supporting Vice President Kamala Harris, but he still has vociferous complaints about his party.
When he donates, he said, he does it in multiples of 18 because “it’s mystical — 18 brings good luck in the tradition of kabbalah. I gave Biden $360,000.”
The 56-year-old is perfectly happy hanging out in a remote woodsy meadow alone — except for his Norwegian ski instructor, his Swiss-Portuguese chef, his Austrian assistant, his American shooting instructor and his bodyguards. (Mr. Karp, who has never married, once complained that bodyguards crimp your ability to flirt.)
“This is like introverts’ heaven,” he said, looking at his red barn from the porch of his Austrian-style house with a mezuza on the door. “You can invite people graciously. No one comes.”
The house is sparse on furniture, but Mr. Karp still worries that it is too cluttered. “I do have a Spartan thing,” he said. “I definitely feel constrained and slightly imprisoned when I have too much stuff around me.”
Asked about the dangers of artificial intelligence, Mr. Karp said, “The only solution to stop A.I. abuse is to use A.I.”Credit…Ryan David Brown for The New York Times
So how did a daydreaming doctoral student in German philosophy wind up leading a shadowy data analytics firm that has become a major American defense contractor, one that works with spy services as it charts the future of autonomous warfare?
He’s not a household name, and yet Mr. Karp is at the vanguard of what Mark Milley, the retired general and former chairman of the Joint Chiefs of Staff, has called “the most significant fundamental change in the character of war ever recorded in history.” In this new world, unorthodox Silicon Valley entrepreneurs like Mr. Karp and Elon Musk are woven into the fabric of America’s national security.
Mr. Karp is also at the white-hot center of ethical issues about whether firms like Palantir are too Big Brother, with access to so much of our personal data as we sign away our privacy. And he is in the middle of the debate about whether artificial intelligence is friend or foe, whether killer robots and disembodied A.I. will one day turn on us.
Mr. Karp’s position is that we’re hurtling toward this new world whether we like it or not. Do we want to dominate it, or do we want to be dominated by China?
Critics worry about what happens when weapons are autonomous and humans become superfluous to the killing process. Tech reflects the values of its operators, so what if it falls into the hands of a modern Caligula?
“I think a lot of the issues come back to ‘Are we in a dangerous world where you have to invest in these things?’” Mr. Karp told me, as he moved around his living room in a tai chi rhythm, wearing his house shoes, jeans and a tight white T-shirt. “And I come down to yes. All these technologies are dangerous.” He adds: “The only solution to stop A.I. abuse is to use A.I.”
Inspired by Tolkien
Palantir’s name is derived from palantíri, the seeing stones in the J.R.R. Tolkien fantasies. The company’s office in Palo Alto, Calif., features “Lord of the Rings” décor and is nicknamed the Shire.
After years under the radar, Mr. Karp is now in the public eye. He has joked that he needs a coach to teach him how to be more normal.
Born in New York and raised outside Philadelphia in a leftist family, Mr. Karp has a Jewish father who was a pediatrician and a Black mother who is an artist. They were social activists who took young Alex to civil rights marches and other protests. His uncle, Gerald D. Jaynes, is an economics and African American studies professor at Yale; his brother, Ben, is an academic who lives in Japan.
“I just think I’ve always viewed myself as I don’t fit in, and I can’t really try to,” Mr. Karp said. “My parents’ background just gave me a primordial subconscious bias that anything that involves ‘We fit in together’ does not include me.
“Yes, I think the way I explain it politically is like, if fascism comes, I will be the first or second person on the wall.”
Mr. Karp has his own unique charisma. “He’s one of a kind, to say the least,” said the Democratic strategist James Carville, who is an informal adviser to Palantir.
When I visited the Palo Alto office, Mr. Karp accidentally knocked down a visitor while demonstrating a tai chi move. He apologized, then ran off to get a printout of Goethe’s “Faust” in German, which he read aloud in an effort to show that it was better than the English translation.
“If you were to do a sitcom on Palantir, it’s equal parts Larry David, a philosophy class, tech and James Bond,” he said.
Mr. Karp at the Senate building in Washington last year. He was among the tech industry titans, including Bill Gates, Elon Musk and Sam Altman, who took part in a discussion of A.I. with lawmakers.Credit…Haiyun Jiang for The New York Times
Palantir was founded in 2003 by a gang of five, including Karp and his old Stanford Law School classmate Peter Thiel (now the company’s chairman). It was backed, in part, by nearly $2 million from In-Q-Tel, the C.I.A.’s venture capital arm.
“Saving lives and on occasion taking lives is super interesting,” Mr. Karp told me.
He described what his company does as “the finding of hidden things” — sifting through mountains of data to perceive patterns, including patterns of suspicious or aberrant behavior.
Mr. Karp does not believe in appeasement. “You scare the crap out of your adversaries,” he said. He brims with American chauvinism, boasting that we are leagues ahead of China and Russia on software.
“The tech scene in America is like the jazz scene in the 1950s,” he said in one forum. He told me: “I’m constantly telling people 86 percent of the top 50 tech companies in the world just by market cap are American — and people fall out of their chair. It’s hard for us to understand how dominant we are in certain industries.”
In the wake of 9/11, the C.I.A. bet on Palantir’s maw gobbling up data and auguring where the next terrorist attacks would come from. Palantir uses multiple databases to find the bad guy, even, as Mr. Karp put it, “if the bad guy actually works for you.”
The company is often credited with helping locate Osama bin Laden so Navy SEALs could kill him, but it’s unclear if that is true. As with many topics that came up in the course of our interviews in Washington, Palo Alto and New Hampshire, Mr. Karp zips his lips about whether his company was involved in dispatching the fiend of 9/11.
“If you have a reputation for talking about what the pope says when you meet him,” Mr. Karp explained, “you’ll never meet the pope again.”
He does crow a little about Western civilization’s resting on Palantir’s slender shoulders, noting that without its software, “you would’ve had massive terror attacks in Europe already, like Oct. 7 style.” And those attacks, he believes, would have propelled the far right to power.
Palantir does not do business with China, Russia or other countries that are opposed to the West. Mr. Thiel said the company tries to work with “more allied” and “less corrupt” governments, noting dryly that aside from their ideological stances, “with corrupt countries, you never get paid.”
“We have a consistently pro-Western view that the West has a superior way of living and organizing itself, especially if we live up to our aspirations,” Mr. Karp said. “It’s interesting how radical that is, considering it’s not, in my view, that radical.”
He added: “If you believe we should appease Iran, Russia and China by saying we’re going to be nicer and nicer and nicer, of course you’ll look at Palantir negatively. Some of these places want you to do the apology show for what you believe in, and we don’t apologize for what we believe in. I’m not going to apologize for defending the U.S. government on the border, defending the Special Ops, bringing the people home. I’m not apologizing for giving our product to Ukraine or Israel or lots of other places.”
As one Karp acquaintance put it: “Alex is principled. You just may not like his principles.”
Kara Swisher, the author of “Burn Book: A Tech Love Story,” told me: “While Palantir promises a more efficient and cost-effective way to conduct war, should our goal be to make it less expensive, onerous and painful? After all, war is not a video game, nor should it be.”
Mr. Karp’s friend Diane von Furstenberg told me that he sees himself as Batman, believing in the importance of choosing sides in a parlous world. (The New York office is called Gotham and features a statue and prints of Batman.) But some critics have a darker view, worrying about Palantir creating a “digital kill chain” and seeing Mr. Karp less as a hero than as a villain.
Back in 2016, some Democrats regarded Palantir as ominous because of Mr. Thiel’s support for former President Donald J. Trump. Later, conspiracy theories sprang up around the company’s role in OperationWarp Speed, the federal effort pushing the Covid-19 vaccine program from clinical trials to jabs in arms.
In December 2016, Donald J. Trump, then the president-elect, met with tech executives including the Palantir co-founder Peter Thiel.Credit…Drew Angerer/Getty Images
Some critics focused on Palantir’s work at the border, which helped U.S. Immigration and Customs Enforcement track down undocumented migrants for deportation. In 2019, about 70 demonstrators blocked access to the cafeteria outside the Palo Alto office. “Immigrants are welcome here, time to cancel Palantir,” they shouted.
The same year, over 200 Palantir employees, in a letter to Mr. Karp, outlined their concerns about the software that had helped ICE. And there was a campaign inside Palantir — in vain — to get him to donate the proceeds of a $49 million ICE contract to charity.
I asked Mr. Karp if Mr. Thiel’s public embrace of Mr. Trump the first time around had made life easier — in terms of getting government contracts — or harder.
“I didn’t enjoy it,” he said. “There’s a lot of reasons I cut Biden a check. I do not enjoy being protested every day. It was completely ludicrous and ridiculous. It was actually the opposite. Because Peter had supported Mr. Trump, it was actually harder to get things done.”
Did they talk about it?
“Peter and I talk about everything,” Mr. Karp said. “It’s like, yes, I definitely informed Peter, ‘This is not making our life easier.’”
Mr. Thiel did not give money to Mr. Trump or speak at his convention this time around, although he supports JD Vance, his former protégé at his venture capital firm. He said he might get more involved now because of Mr. Vance.
Palantir got its start in intelligence and defense — it now works with the Space Force — and has since sprouted across the government through an array of contracts. It helps the I.R.S. to identify tax fraud and the Food and Drug Administration to prevent supply chain disruptions and to get drugs to market quicker.
It has assisted Ukraine and Israel in sifting through seas of data to gather relevant intelligence in their wars — on how to protect special forces by mapping capabilities, how to safely transport troops and how to target drones and missiles more accurately.
In 2022, Mr. Karp took a secret trip to war-ravaged Kyiv, becoming the first major Western C.E.O. to meet with Ukraine’s president, Volodymyr Zelensky, and offering to supply his country with the technology that would allow it to be David to Russia’s Goliath. Time magazine ran a cover on Ukraine as a lab for A.I. warfare, and Palantir operatives embedded with the troops.
A Ukrainian government handout image of Mr. Karp meeting with President Volodymyr Zelensky of Ukraine and Deputy Prime Minister Mykhailo Fedorov in 2022.Credit…Office of the President of Ukraine
While Palantir’s role in helping Ukraine was heralded, its work with Israel, where targeting is more treacherous, because the enemy is parasitically entangled with civilians, is far more controversial.
“I think there’s a huge dichotomy between how the elite sees Ukraine and Israel,” Mr. Karp said. “If you go into any elite circle, pushing back against Russia is obvious, and Israel is complicated. If you go outside elite circles, it’s exactly the opposite.”
Independent analysts have said that Israel, during an April operation, could not have shot down scores of Iranian missiles and drones in mere minutes without Palantir’s tech. But Prime Minister Benjamin Netanyahu’s scorched-earth campaign in Gaza, the starving and orphaned children and the deaths of tens of thousands of civilians have drawn outrage, including some aimed at Mr. Karp and Mr. Thiel.
In May, protesters trapped Mr. Thiel inside a student building at the University of Cambridge. In recent days, senior U.S. officials have expressed doubts about Israel’s conduct of the war.
Mr. Karp’s position on backing Israel is adamantine. The company took out a full-page ad in The New York Times last year stating that “Palantir stands with Israel.”
“It’s like we have a double standard on Israel,” he told me. If the Oct. 7 attack had happened in America, he said, we would turn the hiding place of our enemies “into a parking lot. There would be no more tunnels.”
As Mr. Karp told CNBC in March: “We’ve lost employees. I’m sure we’ll lose more employees. If you have a position that does not cost you ever to lose an employee, it’s not a position.”
He told me, “If you believe that the West should lose and you believe that the only way to defend yourself is always with words and not with actions, you should be skeptical of us.”
He added: “I always think it’s hard because where the critics are right is what we do is morally complex. If you’re supporting the West with products that are used at war, you can’t pretend that there’s a simple answer.”
Does he have any qualms about what his company does?
“I’d have many more qualms if I thought our adversaries were committed to anything like the rule of law,” he said, adding: “A lot of this does come down to, do you think America is a beacon of good or not? I think a lot of the critics, what they actually believe is America is not a force for good.” His feeling is this: “Without being Pollyannaish, idiotic or pretending like any country’s been perfect or there’s not injustice, at the margin, would you want a world where America is stronger, healthy and more powerful, or not?”
In 2019, demonstrators protested the role of Palantir Technologies in aiding U.S. Immigration and Customs Enforcement.Credit…Shannon Stapleton/Reuters
Asked about the impending TikTok ban, he said he’s “very in favor.”
“I do not think you should allow an adversary to control an algorithm that is specifically designed to make us slower, more divided and arguably less cognitively fit,” he said.
He considered the anti-Israel demonstrations such “an infection inside society,” reflecting “a pagan religion of mediocrity and discrimination and intolerance, and violence,” that he offered 180 jobs to students who were fearful of staying in college because of a spike in antisemitism on campuses.
“Palantir is a much better diploma,” he told me. “Honestly, it’s helping us, because there are very talented people at the Ivy League, and they’re like, ‘Get me out of here!’”
Mr. Karp sometimes gets emotional in his defense of Palantir. In June, when he received an award named in honor of Dwight Eisenhower at a D.C. gala for national security executives, he teared up. He said that when he lived in Germany, he often thought about the young men from Iowa and Kansas who risked their lives “to free people like me” during World War II. He said he was honored to receive an award named after the president who had integrated schools by force.
Claiming that his products “changed the course of history by stopping terror attacks,” Mr. Karp said that Palantir had also “protected our men and women on the battlefield” and “taken the lives of our enemies, and I don’t think that’s something to be ashamed of.”
He told the gala audience about being “yelled at” by people who “call themselves progressives.”
“I actually am a progressive,” he said. “I want less war. You only stop war by having the best technology and by scaring the bejabers — I’m trying to be nice here — out of our adversaries. If they are not scared, they don’t wake up scared, they don’t go to bed scared, they don’t fear that the wrath of America will come down on them, they will attack us. They will attack us everywhere.”
He added that “we in the corporate world” have “to grow a spine” on issues like the Ivy League protesters: “If we do not win the battle of ideas and reassert basic norms and the basic, obvious idea that America is a noble, great, wonderful aspiration of a dream that we are blessed to be part of, we will have a much, much worse world for all of us.”
How It Started
Mr. Karp practicing tai chi at his home in New Hampshire.Credit…Ryan David Brown for The New York Times
The wild origin story of Palantir plays like a spy satire.
After graduating from Haverford College, Mr. Karp went to Stanford Law School, which he called “the worst three years of my adult life.”
He wasn’t interested in his classmates’ obsession with landing prestigious jobs at top law firms. “I learned at law school that I cannot do something I do not believe in,” he said, “even if it’s just turning a wrench.”
He met Mr. Thiel, a fellow student, and they immediately hit it off, trash-talking law school and, over beers, debating socialism vs. capitalism. “We argued like feral animals,” Mr. Karp told Michael Steinberger in a New York Times Magazine piece.
The liberal Heidegger fan and the conservative René Girard fan made strange bedfellows, but that’s probably what drew them together.
“I think we bonded on this intellectual level where he was this crazy leftist and I was this crazy right-wing person,” Mr. Thiel told me, “but we somehow talked to each other.”
“Alex did the Ph.D. thing,“ he continued, “which was, in some ways, a very, very insane thing to do after law school, but I was positive on it, because it sounded more interesting than working at a law firm.”
Mr. Karp received his doctorate in neoclassical social theory from Goethe University Frankfurt. He reconnected with Mr. Thiel in 2002, while working at the Jewish Philanthropy Partnership in San Francisco. The two began doing “vague brainstorming,” as Mr. Thiel put it, about a business they could start.
Mr. Thiel thought he could figure out how to find terrorists by using some of the paradigms developed at PayPal, which he helped found, to uncover patterns of fraud.
“I was just always super annoyed when, every time you go to the airport, you had to take off a shoe or you had to go through all this security theater, which was both somewhat taxing but probably had very little to do with actual security,” Mr. Thiel said.
They brought in some software engineers.
“It was two and a half years after 9/11, and you’re starting a software company with people who know nothing about the C.I.A. or any of these organizations,” Mr. Thiel recalled.
It was all very cloak-and-dagger, in an Inspector Clouseau way. They decided to seek out John Poindexter, a retired rear admiral who was dubbed the godfather of modern surveillance; Admiral Poindexter had been forced to resign as President Ronald Reagan’s national security adviser after the Iran-Contra scandal broke. After 9/11, he worked at the Pentagon on a surveillance program called Total Information Awareness.
During the meeting, Mr. Thiel said he felt he was in the presence of a medal-festooned, Machiavelli-loving member of the military brass out of “Dr. Strangelove,” with “a LARPing vibe.”
“We had a hunch that there was a room marked ‘Super-Duper Computer,’ and if you went inside, it was just an empty room,” Mr. Thiel said. They feared their budding algorithm “would end up in a broom closet in the Pentagon,” so they moved on.
In 2005, Mr. Thiel asked Mr. Karp to be the frontman of a company with few employees, no contracts, no investors, no office and no functional tech. “It charitably could have been described as a work in progress,” Mr. Thiel said.
Palantir’s headquarters in Palo Alto, Calif.Credit…Jim Wilson/The New York Times
Mr. Karp and his motley crew got a bunch of desks and explained to clients that they were unmanned because the (fictional) engineers were coming in later.
“God knows why Peter picked me as co-founder,” said Mr. Karp, who had to learn about coding on the job. “It was, in all modesty, a very good choice.”
Mr. Thiel explained: “In some ways, Alex doesn’t look like a salesperson from central casting you would send to the C.I.A. The formulation I always have is that if you’re trying to sell something to somebody, the basic paradox is you have to be just like them, so they can trust you — but you have to be very different from them so that they think you have something they don’t have.”
He said that Mr. Karp would not be suited to running Airbnb or Uber “or some mass consumer product.” But Palantir, he said, “is connected with this great set of geopolitical questions about the Western world versus the rising authoritarian powers. So if we can get our governments to function somewhat better, it’s a way to rebalance things in the direction of the West.”
“Normally,” Mr. Thiel continued, “these are bad ideas to have as a company. They’re too abstract, too idealistic. But I think something like this was necessary in the Palantir case. If you didn’t get some energy from thinking about these things, man, we would’ve sold the company after three years.”
Mr. Karp could not have been more of an outsider, to Silicon Valley and to Washington. He and his engineers had to buy suits for their visits to the capital. “We had no believers,” he said. “I kept telling Palantirians to call me Alex, and they kept calling me Dr. Karp. Then I realized the only thing they could believe in was that I had a Ph.D.”
The first few years, when tech investors were more interested in programs that let you play games on your phone, were rough. “We were like pariahs,” Mr. Karp said. “We couldn’t get meetings. If they did, it was a favor to Peter.”
With administrators in Washington, Mr. Karp recalled: “It was like, What is this Frankenstein monster doing in my office, making these wild claims that he can do better on things I have a huge budget for? How can it be that a freak-show motley crew of 12-year-old-looking mostly dudes, led by a pretty unique figure, from their perspective, would be able to do something with 1 percent of the money that we can’t do with billions and billions of dollars?”
“There’s nothing that we did at Palantir in building our software company that’s in any M.B.A.-made playbook,” Mr. Karp said. “Not one. That’s why we have been doing so well.”
He said that “the single most valuable education I had for business was sitting at the Sigmund Freud Institute, because I spent all my time with analysts.” When he worked at the institute in Frankfurt while getting his doctorate, Mr. Karp said, he would smoke cigars and think about “the conscious subconscious.”
“You’d be surprised how much analysts talk about their patients,” he said. “It’s disconcerting, actually. You just learn so much about how humans actually think.” This knowledge helps him motivate his engineers, he said.
How It’s Going
Mr. Karp said he likes to think of Palantir’s workers as part of an artists’ colony or a family; he doesn’t use the word “staff.” He enjoys interviewing prospective employees personally and prides himself on making hires in under two minutes. (He likes to have a few people around who can talk philosophy and literature with him, in German and French.)
“A lot of my populist-left politics actually bleed into my hiring stuff,” he said. “If you ask the question that the Stanford, Harvard, Yale person has answered a thousand times, all you’re learning is that the Stanford, Harvard, Yale person has learned to play the game.”
Even if he gets a good answer from a “privileged” candidate and a bad answer from “the child of a mechanic,” he might prefer the latter if “I have that feeling like I’m in the presence of talent.”
He views Palantirians like the Goonies, underdogs winning in the end. “Most people at Palantir didn’t get to do a lot of winning in high school,” Mr. Karp said at a company gathering in Palo Alto, to laughter from the audience.
He thinks the United States is “very likely” to end up in a three-front war with China, Russia and Iran. So, he argues, we have to keep going full-tilt on autonomous weapons systems, because our adversaries will — and they don’t have the same moral considerations that we do.
“I think we’re in an age when nuclear deterrent is actually less effective because the West is very unlikely to use anything like a nuclear bomb, whereas our adversaries might,” he said. “Where you have technological parity but moral disparity, the actual disparity is much greater than people think.”
“In fact,” he added, “given that we have parity technologically but we don’t have parity morally, they have a huge advantage.”
Mr. Karp, who said he supports Vice President Kamala Harris in the 2024 election, described his politics as “populist-left.”Credit…Ryan David Brown for The New York Times
Mr. Karp said that we are “very close” to terminator robots and at the threshold of “somewhat autonomous drones and devices like this being the most important instruments of war. You already see this in Ukraine.”
Palantir has learned from some early setbacks.
In 2011, the hacker group Anonymous showed that Palantir employees were involved in a proposed misinformation campaign to discredit WikiLeaks and smear some of its supporters, including the journalist Glenn Greenwald. (Mr. Karp apologized to Mr. Greenwald.) Then, at least one Palantir employee helped Cambridge Analytica collect the Facebook data that the Trump campaign used ahead of the 2016 election.
A pro bono contract with the New Orleans Police Department starting in 2012 was dropped after six years amid criticism that its “predictive policing” eroded privacy and had a disparate impact on people of color.
“We reduced the rates of Black-on-Black death in New Orleans,” Mr. Karp said, “and we have these critics who are like, ‘Palantir is racist.’ I don’t know. The hundreds of people that are alive now don’t think we’re racist.”
Mr. Carville, a New Orleans pooh-bah, asserted that the partnership ended because of “left-wing conspiracy theories.”
Palantir’s rough start in Silicon Valley came about, in part, because many objected to its work with the Department of Defense.
In 2017, Google won a Pentagon contract, Project Maven, to help the military use the company’s A.I. to analyze footage from drones. Employees protested, sending a letter to the C.E.O., Sundar Pichai: “Google should not be in the business of war,” it read. Soon after, Google backed away from the project.
In response, Palantir shaded Google in a tweet that quoted Mr. Karp: “Silicon Valley is telling the average American ‘I will not support your defense needs’ while selling products that are adversarial to America. That is a loser position.” Palantir picked up the contract in 2019.
That same year, Mr. Thiel said that Google had a “treasonous” relationship with China. When Google opened an A.I. lab in 2017 in China, where there’s little distinction between the civilian and the military, he argued, it was de facto helping China while refusing to help America. (That lab closed in 2019, but Google still does business with China, as does Apple.)
“When you have people working at consumer internet companies protesting us because we help the Navy SEALs and the U.S. military and were pro-border — and you’re becoming incredibly, mind-bogglingly rich, in part because America protects your right to export — to me, you’ve lost the sheet of music,” Mr. Karp said. “I don’t think that’s good for America.”
Scott Galloway, a professor at New York University and an authority on tech companies, agrees that many Silicon Valley C.E.O.s have been virtue-signaling and pretending to care about the progressive political views of employees, but really would sell “their mother for a nickel.”
“They’re not there to save the whales,” Mr. Galloway said. “They’re there to make money.”
He added: “Some of these big tech companies seem to be engaged in raising a generation of business leaders that just don’t like America, who are very focused on everything that’s wrong with America.
“Alex Karp is like, ‘No, we’ll cash the Pentagon’s check and we’ll collect data on our enemies.’ He’s gone the entirely opposite way, and I think it was a smart move.”
Palantir’s “spooky connotations,” as one executive put it, dissipated quite a bit when the company went public in 2020 and took on more commercial business; its clients include Airbus, J.P. Morgan, IBM and Amazon.
Mr. Thiel said that while Palantir had a brief stint working on a pilot program for the National Security Agency, the company would not want to do any more work there: “The N.S.A., it hoovers up all the data in the world. As far as I can tell, there are incredible civil liberties violations where they’re spying on everybody outside the U.S., basically. Then they’re fortunately too incompetent to do much with the data.”
The company has started turning a profit, and the stock has climbed. After a triumphant earnings report this month, Palantir’s stock price jumped again.
“The share price gives us more street cred,” Mr. Karp said.
In 2020, after 17 years in Silicon Valley, Mr. Karp moved Palantir’s headquarters to Denver. “I was fleeing Silicon Valley because of what I viewed as the regressive side of progressive politics,” he said.
He thinks that the valley has intensified class divisions in America.
“I don’t believe you would have a Trump phenomenon without the excesses of Silicon Valley,” he said. “Very, very wealthy people who support policies where they don’t have to absorb the cost at all. Just also the general feeling that these people are not tethered to our society, and simultaneously are becoming billionaires.“
“Not supporting the U.S. military,” he said, in a tone of wonder. “I don’t even know how you explain to the average American that you’ve become a multibillionaire and you won’t supply your product to the D.O.D. It’s jarringly corrosive. That’s before you get to all the corrosive, divisive things that are on these platforms.”
Akshay Krishnaswamy, Palantir’s chief architect, agreed on their Silicon Valley critics: “You live in the liberal democratic West because of reasons, and those reasons don’t come for free. They act like it doesn’t have to be fought for or defended rigorously.”
Mr. Karp’s workout room.Credit…Ryan David Brown for The New York TimesA few of his favorite things.Credit…Ryan David Brown for The New York Times
Mr. Karp said things had evolved. “I think there’s a different perception of us now a little bit. A lot of that was tied to Trump, ICE work. It built up and we were definitely outsiders. We’re still outsiders, but I feel less resistance for sure. And people have a better idea of what we do, maybe.” He added, “Defense tech is a big part of Silicon Valley now.”
The A.I. revolution, he said, will come with a knotty question: “How do you make sure the society’s fair when the means of production have become means that only 1 percent of the population actually knows how to navigate?”
I asked if he agrees with Elon Musk that A.I. is eventually going to take everyone’s jobs.
“I think what’s actually dangerous,” Mr. Karp replied, “is that people who understand how to use this are going to capture a lot of the value of the market and everyone else is going to feel left behind.”
Mr. Karp’s iconoclastic style and ironclad beliefs have inspired memes and attracted a flock of online acolytes — some call him Papa Karp or Daddy Karp. He has no social media presence, but his online fans treat him like a mystic, obsessing over the tight white T-shirts he wears for earnings reports, his Norwegian ski outfits, his corkscrew hair, his Italian jeans and sunglasses and his extreme candor. (In a recent earnings report, Mr. Karp dismissed his rivals as “self-pleasuring” and engaging in “self-flagellation.”)
He is not, as one colleague puts it, “a wife, kids and dog person.”
“I tend to have long-term relationships,” he told me. “And I tend to end up with very high IQ women,” including some who tell him he’s talking nonsense.
He prefers what he calls a German attitude toward relationships, where “you have a much greater degree of privacy,” he said, with separate bedrooms and “your own world, your own thoughts, and you get to be alone a lot.” There is much less requirement to “micro-lie” about where you were or whom you were with.
I asked Mr. Karp about his 2013 quote to Forbes that “the only time I’m not thinking about Palantir is when I’m swimming, practicing qigong or during sexual activity.”
He frowned, noting: “It should be tai chi. I don’t know why people always conflate tai chi with qigong. Yes, that was in my early days, when we were a pre-public company and I was allowed to admit I had sexual activity.”
So it’s true that the notion of settling down and raising a family gives him hives?
“There’s some truth in that,” he said. “This is how I like to live. See, I’m sitting here doing my freedom thing. I train. I do distance shooting.” He reads. “Who else has a Len Deighton spy novel next to a book on Confucian philosophy?”
Many of the doyennes of Washington society would love to snag the eligible Mr. Karp for a dinner party. He told me he has “a great social life.” But when I asked him what that is, he replied, “First of all, I’m a cross-country skier, so then I do all this training.”
He continued, “To have an elite VO2 max, an elite level of strength, it’s just consistency and the Norwegian-style training method.”
Some who know Mr. Karp said that the happiest they had ever seen him was last year when Mike Allen reported for Axios that the C.E.O.’s body fat was an impressive 7 percent.
Mr. Karp may be able to do more than 20 miles of cross-country skiing without being out of breath, but there are some sports at which, he admitted, he’s “a complete zero. For example, ball sports. I really suck at them.”
Unlike Mr. Musk and other tech lords, Mr. Karp is not into micro-dosing ketamine or any other drug. “My drug is athletics,” he said. “I love drinking, but now I’ve moved to drinking very little because what I’ve noticed is if you’re traveling all the time, the alcohol, it really affects your brain.” He’s on the road about 240 days a year.
Mr. Musk and Mr. Karp at the forum on A.I. in Washington last year.Credit…Haiyun Jiang for The New York Times
Mr. Karp said of his dyslexia: “I think this is not getting less, it’s likely getting more. In 40 years, I’ll be unable to read.”
In New Hampshire, we had a lunch of lobster pasta — he kept his panic button on the table — and then went shooting on his property. He expertly hit targets with a 9-millimeter pistol from 264 yards. When an aide suggested that a photographer not shoot Mr. Karp in the act of shooting, he overruled the idea.
“Actually, honestly, guns would be much better regulated if you had someone who knows guns,” he said. “I’m not a hunter. I’m an artist with a gun.”
(Later, Mr. Karp pointed out that he had been shooting at targets that were about twice as far from him as Mr. Trump was from his would-be assassin. “There’s something really wrong with security for our future president, or maybe not future president,” he said. “All these people need a different level of security.”)
Mr. Karp believes the Democrats need to project more strength: “Are we tough enough to scare our adversaries so we don’t go to war? Do the Chinese, Russians and Persians think we’re strong? The president needs to tell them if you cross these lines, this is what we’re going to do, and you have to then enforce it.”
He thinks that in America and in Europe, the inability or unwillingness to secure borders fuels authoritarianism.
“I see it as pretty simple: You have an open border, you get the far right,” he said. “And once you get them, you can’t get rid of them. We saw it in Brexit, we see it with Le Pen in France, you see it across Europe. Now you see it in Germany.”
“They should be much stricter,” he continued. That, he said, “is the only reason we have the rise of the right, the only reason. When people tell you we need an open border, then they should also tell you why they’re electing right-wing politicians, because they are.”
“The biggest mistake — and it’s not one politician, it’s a generation — was believing there was something bigoted about having a border, and there are just a lot of people who believe that,” he said.
Weeks later, we were back in the Washington office, which is dubbed Rivendell, after a valley in Tolkien’s Middle-earth, and is filled with tech goodies like a Ping-Pong table, a pool table and a towering replica of Chewbacca.
We picked up our conversation about politics, talking about the swap of President Biden and Vice President Harris, the rise of JD Vance, the assassination attempt and the changed political landscape.
Mr. Karp concurred with his friend Mr. Carville on the problem of drawing men to the Democratic Party, saying, “If this is going to be a party complaining about guys and to guys all the time, it’s not going to succeed.”
At the shooting range on his property in New Hampshire. “I’m an artist with a gun,” Mr. Karp said.Credit…Ryan David Brown for The New York Times
He continued: “The biggest problem with hard political correctness is it makes it impossible to deal with unfortunate facts. The unfortunate fact here is that this election is really going to turn on ‘What percentage of males can the Democrats still get?’”
Describing himself as “progressive but not woke,” he said, “We are so unwilling to talk to the actual constituents that are voting for the Democratic Party who would probably strongly prefer policies that are more moderate.”
Given Mr. Karp’s blended racial identity, I wondered how he felt about Mr. Trump’s attack on the vice president’s heritage.
“I think people are most fascinated by the fact of this whole Black-Jewish thing,” he said. “I tend to be less fascinated by that.”
He added: “I think that people always expect me somehow to see the world in one way or another, and I don’t really understand what that means. I see the world the way I see it. I think, at the end of the day, if people want to choose what their identity is, then they choose it, and that’s their definition.”
I note that he recently made an elite list of Black billionaires.
He shrugged. “Some Black people think I’m Black, some don’t,” he said. “I view me as me. And I’m very honored to be honored by all groups that will have me.”
He added: “I do not believe racism is the most important issue in this country. I think class is determinate, and I’m mystified by how often we talk about race. I’m not saying it doesn’t exist. I’m not saying people don’t have biases. Of course, we all do, but the primary thing that’s bad for you in this culture is to be born poor of any color.”
He said he would support class-based affirmative action and declared himself “pro draft.”
“I think part of the reason we have a massive cleavage in our culture is, at the end of the day, by and large, only people who are middle- and working-class do all the fighting,” he said.
Since I had last seen him, Mr. Karp had gotten caught between two of the battling billionaires of Silicon Valley, lords of the cloud vituperously fighting in public over the possible restoration of Donald Trump.
According to an account in Puck, Mr. Karp was onstage with the LinkedIn co-founder Reid Hoffman at a conference last month in Sun Valley, Idaho, sponsored by the investment bank Allen & Company, when Mr. Hoffman called Mr. Thiel’s support for Mr. Trump “a moral issue.” Speaking up from his seat in the audience, Mr. Thiel sarcastically thanked Mr. Hoffman for funding lawsuits against Mr. Trump, which allowed the candidate to claim that he is “a martyr.”
Mr. Hoffman snapped back, “Yeah, I wish I had made him an actual martyr” — an unfortunate comment given what would later happen in Butler, Pa.
I asked Mr. Karp whether the encounter was as uncomfortable as it seemed.
“Well, I’m used to being uncomfortable,” he said. “I’m going to stick with my friends. I just feel the same way I always feel when Peter is under attack, which is: ‘This is my friend. I feel that my friend is being attacked, and I will defend him.’”
The fancy digital clock behind Mr. Karp’s desk, which tells time in German, had gone from “Es ist zehn nach drei” to “Es ist halb vier.”
It was time to go.
Mr. Karp said that while working at the Sigmund Freud Institute in Frankfurt, he learned things that were helpful to him later as a business leader.Credit…Ryan David Brown for The New York Times
Confirm or Deny
Maureen Dowd: You run the Twitter account Alex Karp’s Hair.
Alex Karp: I wish.
Your favorite movie is the classic kung fu flick “The 36th Chamber of Shaolin.”
One of my favorite movies.
You have 10 houses around the world, from Alaska to Vermont, from Norway to New Hampshire.
You have to reframe that as I have 10 cross-country ski huts.
You love the idea of Peter Thiel backing Olympic-style games where the athletes will dope out in the open.
Deny. I want the best cross-country skiers to win without doping.
You love to watch spy shows and German movies, and one of your favorite filmmakers is Rainer Werner Fassbinder.
Confirm.
You have 20 identical pairs of swim goggles in your office.
No longer. I used to. I gave up swimming. There’s an emptiness to it.
You commissioned a French comic book, “Palantir: L’Indépendance,” with yourself as the protagonist.
Oui!
You starred in a movie by Hanna Laura Klar in 1998, “I Have Two Faces,” where you looked like a young Woody Allen.
I look better than Woody Allen.
Your dissertation is about how people transmit aggression subconsciously in language, presaging the rise of the right in America and Europe.
Often, the more charismatic ideologies were, the more irrational they were.
The dissertation touched on expressing taboo wishes. Do you want to share some of those?
I would love to express taboo wishes with you, but not to your audience.