Source: https://www.wired.com/story/phone-data-us-soldiers-spies-nuclear-germany/
by Dhruv Mehrotra Dell Cameron
Nearly every weekday morning, a device leaves a two-story home near Wiesbaden, Germany, and makes a 15-minute commute along a major autobahn. By around 7 am, it arrives at Lucius D. Clay Kaserne—the US Army’s European headquarters and a key hub for US intelligence operations.
The device stops near a restaurant before heading to an office near the base that belongs to a major government contractor responsible for outfitting and securing some of the nation’s most sensitive facilities.
For roughly two months in 2023, this device followed a predictable routine: stops at the contractor’s office, visits to a discreet hangar on base, and lunchtime trips to the base’s dining facility. Twice in November of last year, it made a 30-minute drive to the Dagger Complex, a former intelligence and NSA signals processing facility. On weekends, the device could be traced to restaurants and shops in Wiesbaden.
The individual carrying this device likely isn’t a spy or high-ranking intelligence official. Instead, experts believe, they’re a contractor who works on critical systems—HVAC, computing infrastructure, or possibly securing the newly built Consolidated Intelligence Center, a state-of-the-art facility suspected to be used by the National Security Agency.
Whoever they are, the device they’re carrying with them everywhere is putting US national security at risk.
A joint investigation by WIRED, Bayerischer Rundfunk (BR), and Netzpolitik.org reveals that US companies legally collecting digital advertising data are also providing the world a cheap and reliable way to track the movements of American military and intelligence personnel overseas, from their homes and their children’s schools to hardened aircraft shelters within an airbase where US nuclear weapons are believed to be stored.
A collaborative analysis of billions of location coordinates obtained from a US-based data broker provides extraordinary insight into the daily routines of US service members. The findings also provide a vivid example of the significant risks the unregulated sale of mobile location data poses to the integrity of the US military and the safety of its service members and their families overseas.
We tracked hundreds of thousands of signals from devices inside sensitive US installations in Germany. That includes scores of devices within suspected NSA monitoring or signals-analysis facilities, more than a thousand devices at a sprawling US compound where Ukrainian troops were being being trained in 2023, and nearly 2,000 others at an air force base that has crucially supported American drone operations.
A device likely tied to an NSA or intelligence employee broadcast coordinates from inside a windowless building with a metal exterior known as the “Tin Can,” which is reportedly used for NSA surveillance, according to agency documents leaked by Edward Snowden. Another device transmitted signals from within a restricted weapons testing facility, revealing its zig-zagging movements across a high-security zone used for tank maneuvers and live munitions drills.
We traced these devices from barracks to work buildings, Italian restaurants, Aldi grocery stores, and bars. As many as four devices that regularly pinged from Ramstein Air Base were later tracked to nearby brothels off base, including a multistory facility called SexWorld.
Experts caution that foreign governments could use this data to identify individuals with access to sensitive areas; terrorists or criminals could decipher when US nuclear weapons are least guarded; or spies and other nefarious actors could leverage embarrassing information for blackmail.
“The unregulated data broker industry poses a clear threat to national security,” says Ron Wyden, a US senator from Oregon with more than 20 years overseeing intelligence work. “It is outrageous that American data brokers are selling location data collected from thousands of brave members of the armed forces who serve in harms’ way around the world.”
Wyden approached the US Defense Department in September after initial reporting by BR and netzpolitik.org raised concerns about the tracking of potential US service members. DoD failed to respond. Likewise, Wyden’s office has yet to hear back from members of US president Joe Biden’s National Security Council, despite repeated inquiries. The NSC did not immediately respond to a request for comment.
“There is ample blame to go around,” says Wyden, “but unless the incoming administration and Congress act, these kinds of abuses will keep happening, and they’ll cost service members‘ lives.”
The Oregon senator also raised the issue earlier this year with the Federal Trade Commission, following an FTC order that imposed unprecedented restrictions against a US company it accused of gathering data around “sensitive locations.” Douglas Farrar, the FTC’s director of public affairs, declined a request to comment.
WIRED can now exclusively report, however, that the FTC is on the verge of fulfilling Wyden’s request. An FTC source, granted anonymity to discuss internal matters, says the agency is planning to file multiple lawsuits soon that will formally recognize US military installations as protected sites. The source adds that the lawsuits are in keeping with years‘ worth of work by FTC Chair Lina Khan aimed at shielding US consumers—including service members—from harmful surveillance practices.
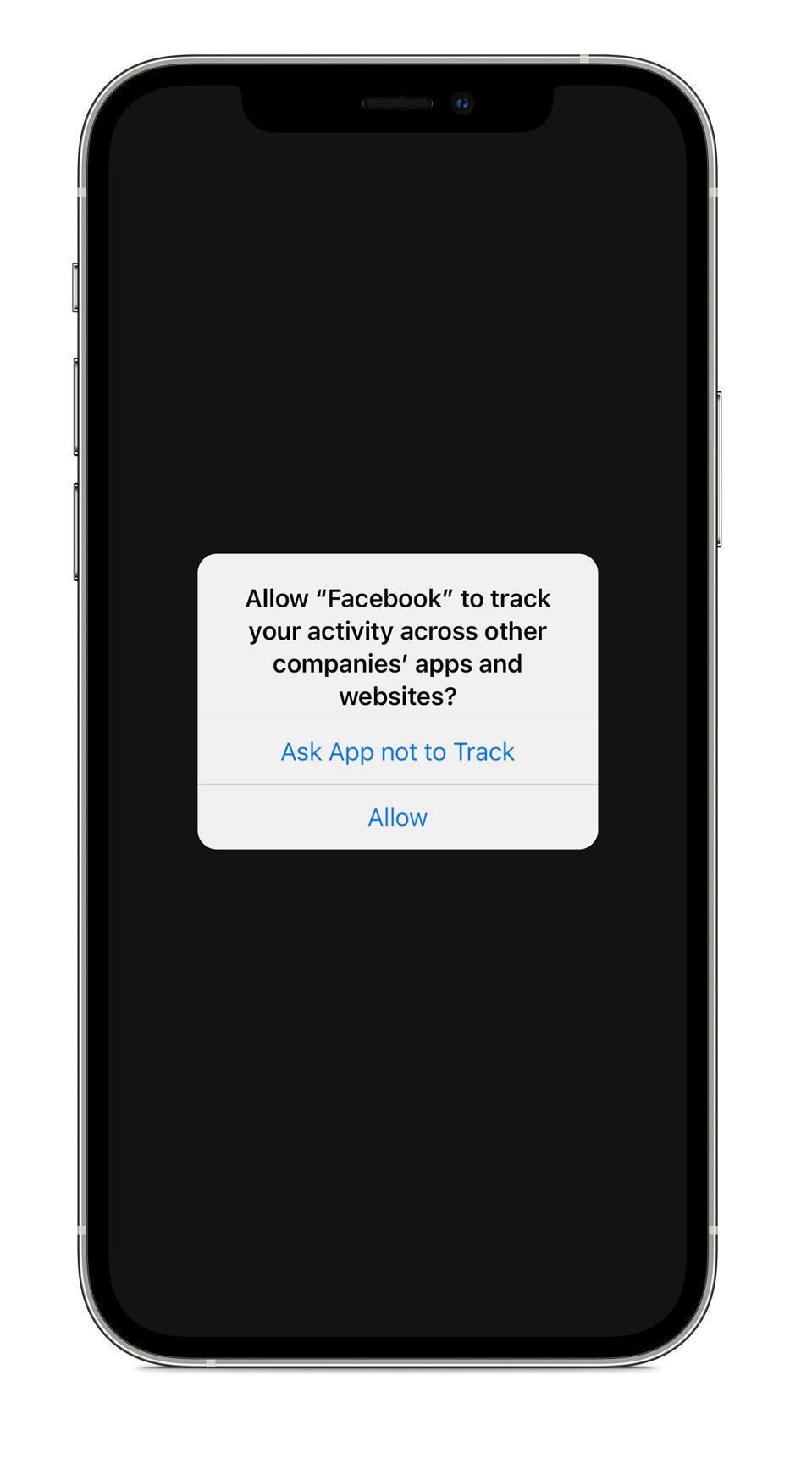
Before a targeted ad appears on an app or website, third-party software often embedded in apps called software development kits transmit information about their users to data brokers, real-time bidding platforms, and ad exchanges—often including location data. Data brokers often will collect that data, analyze it, repackage it, and sell it.
In February of 2024, reporters from BR and Netzpolitik.org obtained a free sample of this kind of data from Datastream Group, a Florida-based data broker. The dataset contains 3.6 billion coordinates—some recorded at millisecond intervals—from up to 11 million mobile advertising IDs in Germany over what the company says is a 59-day span from October through December 2023.
Mobile advertising IDs are unique identifiers used by the advertising industry to serve personalized ads to smartphones. These strings of letters and numbers allow companies to track user behavior and target ads effectively. However, mobile advertising IDs can also reveal much more sensitive information, particularly when combined with precise geolocation data.
In total, our analysis revealed granular location data from up to 12,313 devices that appeared to spend time at or near at least 11 military and intelligence sites, potentially exposing crucial details like entry points, security practices, and guard schedules—information that, in the hands of hostile foreign governments or terrorists, could be deadly.
Our investigation uncovered 38,474 location signals from up to 189 devices inside Büchel Air Base, a high-security German installation where as many as 15 US nuclear weapons are reportedly stored in underground bunkers. At Grafenwöhr Training Area, where thousands of US troops are stationed and have trained Ukrainian soldiers on Abrams tanks, we tracked 191,415 signals from up to 1,257 devices.
At Lucius D. Clay Kaserne, the US Army’s European headquarters, we identified 74,968 location signals from as many as 799 devices, including some at the European Technical Center, once the NSA’s communication hub in Europe.Courtesy of OpenMapTiles
In Wiesbaden, home to the US Army’s European headquarters at Lucius D. Clay Kaserne, 74,968 location signals from as many as 799 devices were detected—some originating from sensitive intelligence facilities like the European Technical Center, once the NSA’s communication hub in Europe, and newly built intelligence operations centers.
At Ramstein Air Base, which supports some US drone operations, 164,223 signals from nearly 2,000 devices were tracked. That included devices tracked to Ramstein Elementary and High School, base schools for the children of military personnel.
Of these devices, 1,326 appeared at more than one of these highly sensitive military sites, potentially mapping the movements of US service members across Europe’s most secure locations.
The data is not infallible. Mobile ad IDs can be reset, meaning multiple IDs can be assigned to the same device. Our analysis found that, in some instances, devices were assigned more than 10 mobile ad IDs.
The location data’s precision at the individual device level can also be inconsistent. By contacting several people whose movements were revealed in the dataset, the reporting collective confirmed that much of the data was highly accurate—identifying work commutes and dog walks of individuals contacted. However, this wasn’t always the case. One reporter whose ID appears in the dataset found that it often placed him a block away from his apartment and during times when he was out of town. A study from NATO Strategic Communications Center of Excellence found that “quantity overshadows quality” in the data broker industry and that, on average, only up to 60 percent of the data surveyed can be considered precise.
According to its website, Datastream Group appears to offer “internet advertising data coupled with hashed emails, cookies, and mobile location data.” Its listed datasets include niche categories like boat owners, mortgage seekers, and cigarette smokers. The company, one of many in a multibillion-dollar location-data industry, did not respond to our request for comment about the data it provided on US military and intelligence personnel in Germany, where the US maintains a force of at least 35,000 troops, according to the most recent estimates.
Defense Department officials have known about the threat that commercial data brokers pose to national security since at least 2016, when Mike Yeagley, a government contractor and technologist, delivered a briefing to senior military officials at the Joint Special Operations Command compound in Fort Liberty (formerly Fort Bragg), North Carolina, about the issue. Yeagley’s presentation aimed to show how commercially available mobile data—already pervasive in conflict zones like Syria—could be weaponized for pattern of life analysis.
Midway through the presentation, Yeagley decided to raise the stakes. “Well, here’s the behavior of an ISIS operator,” he tells WIRED, recalling his presentation. “Let me turn the mirror around—let me show you how it works for your own personnel.” He then displayed data revealing phones as they moved from Fort Bragg in North Carolina and MacDill Air Force Base in Florida—critical hubs for elite US special operations units. The devices traveled through transit points like Turkey before clustering in northern Syria at a seemingly abandoned cement factory near Kobane, a known ISIS stronghold. The location he pinpointed was a covert forward operating base.
Yeagley says he was quickly escorted to a secured room to continue his presentation behind closed doors. There, officials questioned him on how he had obtained the data, concerned that his stunt had involved hacking personnel or unauthorized intercepts.
The data wasn’t sourced from espionage but from unregulated commercial brokers, he explained to the concerned DOD officials. “I didn’t hack, intercept, or engineer this data,” he told them. “I bought it.”
Now, years later, Yeagley remains deeply frustrated with the DODs inability to control the situation. What WIRED, BR, and Netzpolitik.org are now reporting is “very similar to the alarms we raised almost 10 years ago,” he says, shaking his head. “And it doesn’t seem like anything’s changed.”
US law requires the director of national intelligence to provide “protection support” for the personal devices of “at risk” intelligence personnel who are deemed susceptible to “hostile information collection activities.” But which personnel meet this criteria is unclear, as is the extent of the protections beyond periodic training and advice. The location data we acquired demonstrates, regardless, that commercial surveillance is far too pervasive and complex to be reduced to individual responsibility.
Biden’s outgoing director of national intelligence, Avril Haines, did not respond to a request for comment.
A report declassified by Haines last summeracknowledges that US intelligence agencies had purchased a “large amount” of “sensitive and intimate information” about US citizens from commercial data brokers, adding that “in the wrong hands,” the data could “facilitate blackmail, stalking, harassment, and public shaming.” The report, which contains numerous redactions, notes that, while the US government „would never have been permitted to compel billions of people to carry location tracking devices on their persons at all times,” smartphones, connected cars, and web tracking have all made this possible “without government participation.”
Mike Rogers, the Republican chair of the House Armed Services Committee, did not respond to multiple requests for comment. A spokesperson for Adam Smith, the committee’s ranking Democrat, said Smith was unavailable to discuss the matter, busy negotiating a must-pass bill to fund the Pentagon’s policy priorities next year.
Jack Reed and Roger Wicker, the leading Democrat and Republican on the Senate Armed Services Committee, respectively, did not respond to multiple requests for comment. Inquiries placed with House and Senate leaders and top lawmakers on both congressional intelligence committees have gone unanswered.
The DOD and the NSA declined to answer specific questions related to our investigation. However, DOD spokesperson Javan Rasnake says that the Pentagon is aware that geolocation services could put personnel at risk and urged service members to remember their training and adhere strictly to operational security protocols. “Within the USEUCOM region, members are reminded of the need to execute proper OPSEC when conducting mission activities inside operational areas,” Rasnake says, using the shorthand for operational security.
An internal Pentagon presentation obtained by the reporting collective, though, claims that not only is the domestic data collection likely capable of revealing military secrets, it is essentially unavoidable at the personal level, service members’ lives being simply too intertwined with the technology permitting it. This conclusion closely mirrors the observations of Chief Justice John Roberts of the US Supreme Court, who in landmark privacy cases within the past decade described cell phones as being a “pervasive and insistent part of daily life” and that owning one was “indispensable to participation in modern society.”
The presentation, which a source says was delivered to high-ranking general officers, including the US Army’s chief information officer, warns that despite promises from major ad tech companies, “de-anonymization” is all but trivial given the widespread availability of commercial data collected on Pentagon employees. The document emphasizes that the caches of location data on US individuals is a “force protection issue,” likely capable of revealing troop movements and other highly guarded military secrets.
While instances of blackmail inside the Pentagon have seen a sharp decline since the Cold War, many of the structural barriers to persistently surveilling Americans have also vanished. In recent decades, US courts have repeatedly found that new technologies pose a threat to privacy by enabling surveillance that, “in earlier times, would have been prohibitively expensive,“ as the 7th Circuit Court of Appeals noted in 2007.
In an August 2024 ruling, another US appeals court disregarded claims by tech companies that users who “opt in” to surveillance were actually “informed” and doing so “voluntarily,” declaring the opposite is clear to “anyone with a smartphone.” The internal presentation for military staff presses that adversarial nations can gain access to advertising data with ease, using it to exploit, manipulate, and coerce military personnel for purposes of espionage.
Patronizing sex workers, whether legal in a foreign country or not, is a violation of the Uniform Code of Military Justice. The penalties can be severe, including forfeiture of pay, dishonorable discharge, and up to one year of imprisonment. But the ban on solicitation is not merely imposed on principle alone, says Michael Waddington, a criminal defense attorney who specializes in court-marial cases. “There’s a genuine danger of encountering foreign agents in these establishments, which can lead to blackmail or exploitation,” he says.
“This issue is particularly concerning given the current geopolitical climate. Many US servicemembers in Europe are involved in supporting Ukraine in its defense against the Russian invasion,” Waddington says. “Any compromise of their integrity could have serious implications for our operations and national security.”
When it comes to jeopardizing national security, even data on low-level personnel can pose a risk, says Vivek Chilukuri, senior fellow and program director of the Technology and National Security Program at the Center for a New American Security (CNAS). Before joining CNAS, Chilukuri served in part as legislative director and tech policy advisor to US senator Michael Bennet on the Senate Intelligence Committee and previously worked at the US State Department, specializing in countering violent extremism.
„Low-value targets can lead to high-value compromises,“ Chilukuri says. „Even if someone isn’t senior in an organization, they may have access to highly sensitive infrastructure. A system is only as secure as its weakest link.“ He points out that if adversaries can target someone with access to a crucial server or database, they could exploit that vulnerability to cause serious damage. “It just takes one USB stick plugged into the right device to compromise an organization.”
It’s not just individual service members who are at risk—entire security protocols and operational routines can be exposed through location data. At Büchel Air Base, where the US is believed to have stored an estimated 10 to 15 B61 nuclear weapons, the data reveals the daily activity patterns of devices on the base, including when personnel are most active and, more concerningly, potentially when the base is least populated.
Overview of the Air Mobility Command ramp at Ramstein Air Base, Germany.Photograph: Timm Ziegenthaler/Stocktrek Images; Getty Images
Büchel has 11 protective aircraft shelters equipped with hardened vaults for nuclear weapons storage. Each vault, which is located in a so-called WS3, or Weapons Storage and Security System, can hold up to four warheads. Our investigation traced precise location data for as many as 40 cellular devices that were present in or near these bunkers.
The patterns we could observe from devices at Büchel go far beyond just understanding the working hours of people on base. In aggregate, it’s possible to map key entry and exit points, pinpointing frequently visited areas, and even tracing personnel to their off-base routines. For a terrorist, this information could be a gold mine—an opportunity to identify weak points, plan an attack, or target individuals with access to sensitive areas.
This month, German authorities arrested a former civilian contractor employed by the US military on allegations of offering to pass sensitive information about American military operations in Germany to Chinese intelligence agencies.
In April, German authorities arrested two German-Russian nationals accused of scouting US military sites for potential sabotage, including allegedly arson. One of the targeted locations was the US Army’s Grafenwöhr Training Area in Bavaria, a critical hub for US military operations in Europe that spans 233 square kilometers.
At Grafenwöhr, WIRED, BR, and Netzpolitik.org could track the precise movements from up to 1,257 devices. Some devices could even be observed zigzagging through Range 301, an armored vehicle course, before returning to nearby barracks.
Our investigation found 38,474 location signals from up to 189 devices inside Büchel Air Base, around a dozen US nuclear weapons are reportedly stored.Courtesy of OpenMapTiles
A senior fellow at Duke University’s Sanford School of Public Policy and head of its data brokerage research project, Justin Sherman also leads Global Cyber Strategies, a firm specializing in cybersecurity and tech policy. In 2023, he and his coauthors at Duke secured $250,000 in funding from the United States Military Academy to investigate how easy it is to purchase sensitive data about military personnel from data brokers. The results were alarming: They were able to buy highly sensitive, nonpublic, individually identifiable health and financial data on active-duty service members, without any vetting.
“It shows you how bad the situation is,” Sherman says, explaining how they geofenced requests to specific special operations bases. “We didn’t pretend to be a marketing firm in LA. We just wanted to see what the data brokers would ask.” Most brokers didn’t question their requests, and one even offered to bypass an ID verification check if they paid by wire.
During the study, Sherman helped draft an amendment to the National Defense Authorization Act that requires the Defense Department to ensure that highly identifiable individual data shared with contractors cannot be resold. He found the overall impact of the study underwhelming, however. “The scope of the industry is the problem,” he says. “It’s great to pass focused controls on parts of the ecosystem, but if you don’t address the rest of the industry, you leave the door wide open for anyone wanting location data on intelligence officers.”
Efforts by the US Congress to pass comprehensive privacy legislation have been stalled for the better part of a decade. The latest effort, known as the American Privacy Rights Act, failed to advance in June after GOP leaders threatened to scuttle the bill, which was significantly weakened before being shelved.
Another current privacy bill, the Fourth Amendment Is Not For Sale Act, seeks to ban the US government from purchasing data on Americans that it would normally need a warrant to obtain. While the bill would not prohibit the sale of commercial location data altogether, it would bar federal agencies from using those purchases to circumvent constitutional protections upheld by the Supreme Court. Its fate rests in the hands of House and Senate leaders, whose negotiations are private.
“The government needs to stop subsidizing what is now for good reason one of the world’s least popular industries,” says Sean Vitka, policy director at the nonprofit Demand Progress. “There are a lot of members of Congress who take seriously the severe threats to privacy and national security posed by data brokers, but we’ve seen many actions by congressional leaders that only furthers the problem. There shouldn’t need to be a body count for these people to take action.”