What does the world look like when we are no longer compute constrained?
Billions of dollars are flowing into AI companies optimized for a world that may not exist in five years.
Right now, AI is massively compute constrained. And in just the past few weeks, the evidence is piling up:
Rental prices for H100s have shot up 40% from October 2025 to March 2026.
The current DRAM memory shortage is now expected to last through 2027, and likely longer.
TSMC is nearing its ceiling for N3 logic wafer capacity.
Data center developers are expecting power shortages through 2028.
Anthropic announced new throttling measures and usage limits to cope with spiking demand overstretching its compute capacity.
And the SpaceX/Cursor deal is exposing just how in demand GPU clusters are.
Even the favorite shoe brand of every tech bro in 2017 is looking to get into the compute game…

All of this is real. The scarcity is real. And the companies capitalizing on it are posting incredible numbers and building meaningful businesses. But here’s the thing: every prior technology cycle had a scarce resource at its center, and every time, that scarcity eventually broke. When it did, the value map reshuffled dramatically – and the companies that looked unassailable during the scarcity era often weren’t the long-term winners.
Our view: the venture landscape is dramatically overweighting what is in demand today versus what is going to be in demand for the next ten years.
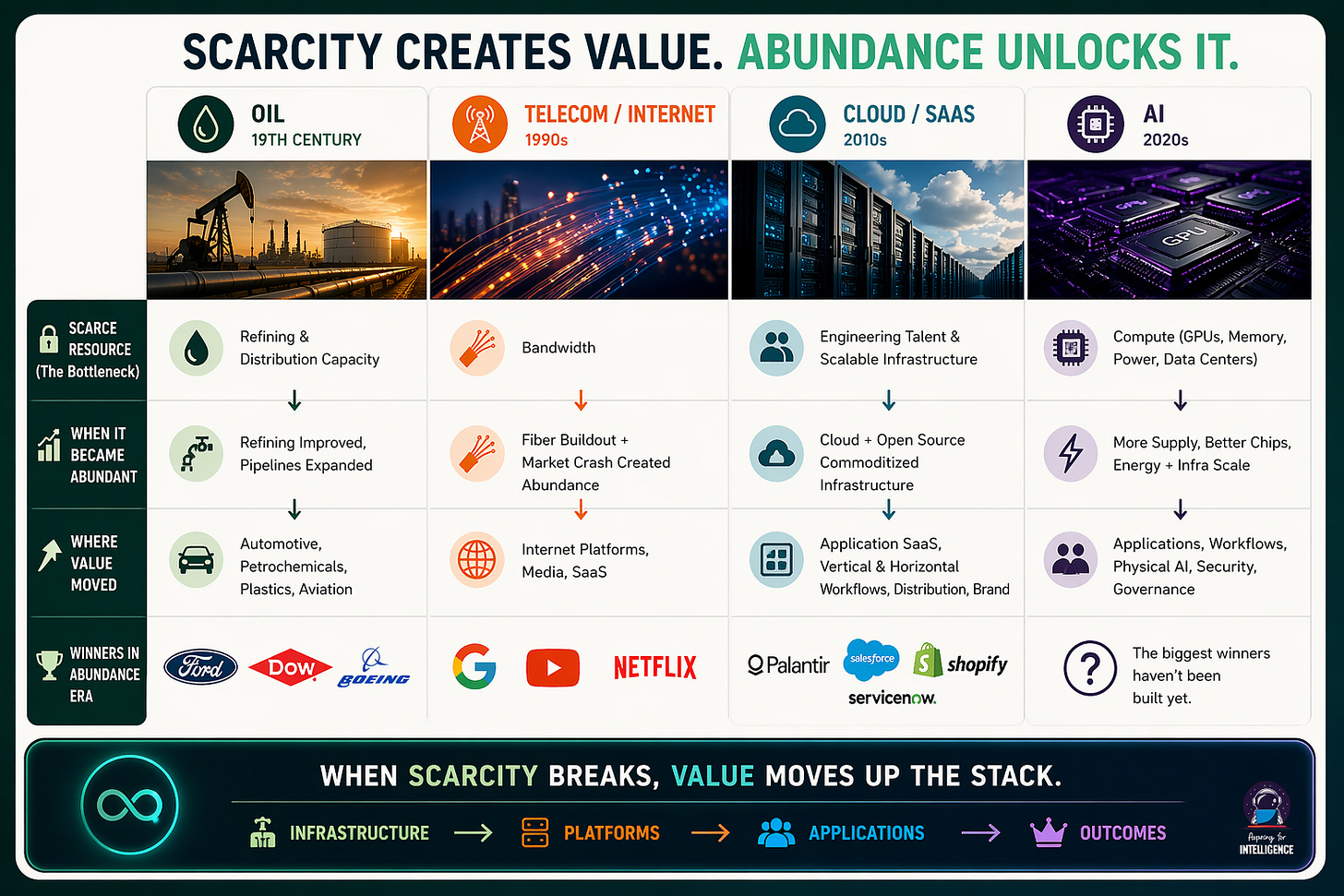
We’ve Seen This Before
Every prior innovation cycle started with a scarce resource that eventually became abundant.
Oil in the 19th century
In the late 1800s, crude was actually plentiful. Wildcatters kept finding more of it. The real bottleneck was refining capacity and distribution, which is why John D. Rockefeller built Standard Oil around those layers rather than drilling. But once refining technology matured and pipeline networks expanded, that bottleneck broke too. And the interesting thing is what came next: the automotive economy, petrochemicals, plastics, commercial aviation. Ford’s Model T only made sense because fuel was getting cheap. The plastics revolution required abundant petroleum feedstocks. These were entire industries that nobody was really thinking about during the scarcity era, and they ended up dwarfing the value of oil extraction and refining combined.
Telecom in the 1990s
The telecom boom of the late ’90s followed a similar arc, with a twist. Bandwidth was the scarce resource, and telecoms raised hundreds of billions to control it. Then the bubble burst; and the bust created the abundance. All that fiber didn’t disappear when Global Crossing and WorldCom went bankrupt. It got bought at pennies on the dollar. What happened next is instructive. Google, YouTube, Netflix, Spotify — none of these businesses were economically viable at 1999 bandwidth prices. They needed cheap bandwidth to exist at all. Meanwhile, the companies that had been valuable specifically because bandwidth was expensive got crushed. RealNetworks, once worth over $30 billion for its streaming compression tech, became irrelevant almost overnight. Why bother with clever compression when you can just send the full stream? CDN technology went from a high-margin standalone business to a feature baked into cloud platforms. Even Salesforce and the broader SaaS model were downstream beneficiaries of cheap, reliable connectivity.
The winners weren’t the ones who owned the scarce resource or built optimization tricks around it. They were the ones who built for the world where it was cheap.
Cloud / SaaS in the 2010s
Cloud and SaaS repeated the pattern one more time. Through the 2010s, the bottleneck was engineering talent and scalable infrastructure. Engineer salaries soared. Companies fought viciously over hiring. A legendary show satirizing Silicon Valley culture became required viewing. SaaS pricing reflected the genuine cost of building and maintaining good software. Then AWS, Azure, and GCP commoditized infrastructure, open source commoditized components, and value migrated again — from horizontal platforms to vertical SaaS with deep domain knowledge, from engineering as the moat to distribution as the moat, from building software to configuring it. Some of the most valuable late-stage SaaS companies weren’t particularly technically impressive. They just had the best go-to-market and the deepest workflow integration. Same story: when the scarce resource got cheap, value moved up the stack toward whoever was closest to the end user and the actual problem being solved.
These prior waves prove that as the scarce resource becomes abundant, value migrates UP THE STACK. Applications, workflows, and things that touch the user accrue value; “optimization” layers that were valuable during scarcity get squeezed.

What’s Priced For Scarcity Today?
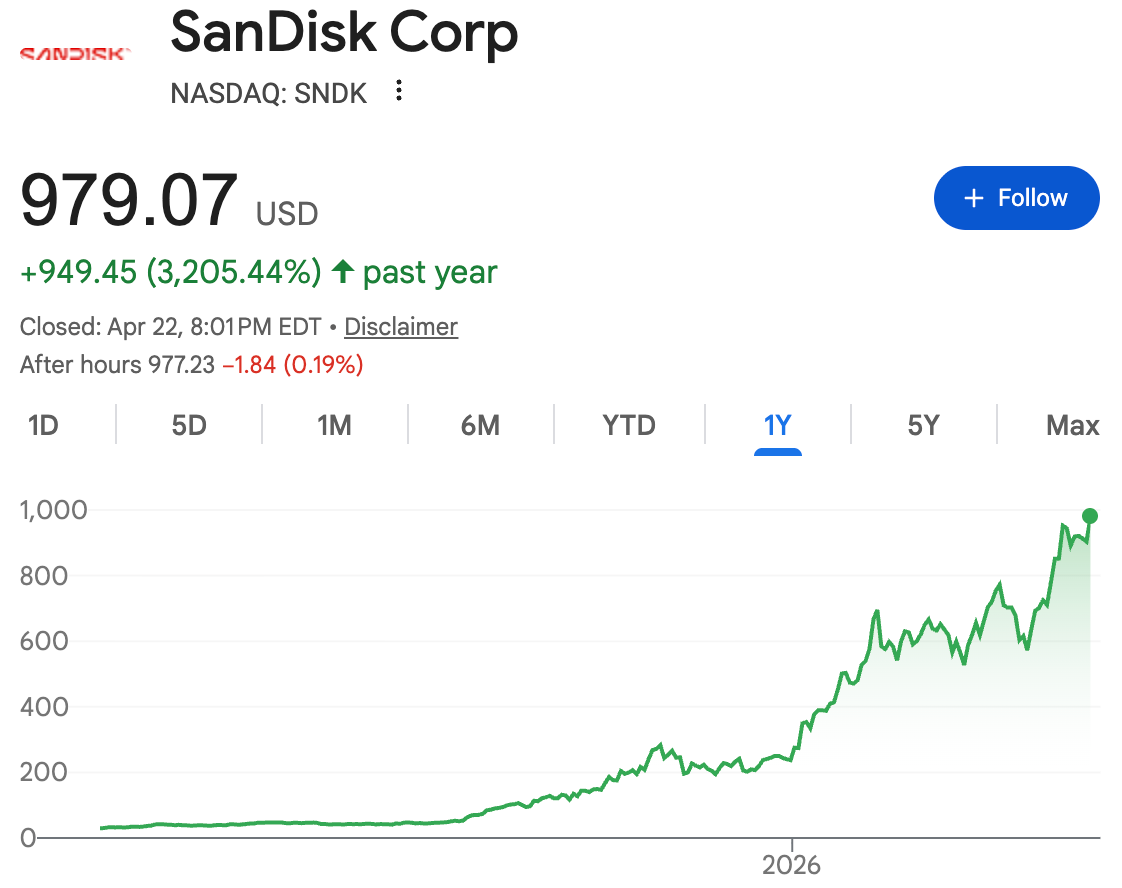
It feels like fundraising and commercialization in the AI market today is heavily skewed towards companies capitalizing on the compute shortages. On the public side, chip companies like Nvidia have been making hay for the past few years, but nearly every company across memory (Sandisk, SK Hynix), semis (TSMC, AMD), and power (Bloom Energy, Vistra) have been seeing record revenues, profits, and a ripping stock. This makes sense — during scarcity, the resource providers always have the best economics. The question is how much of this is structural versus cyclical.
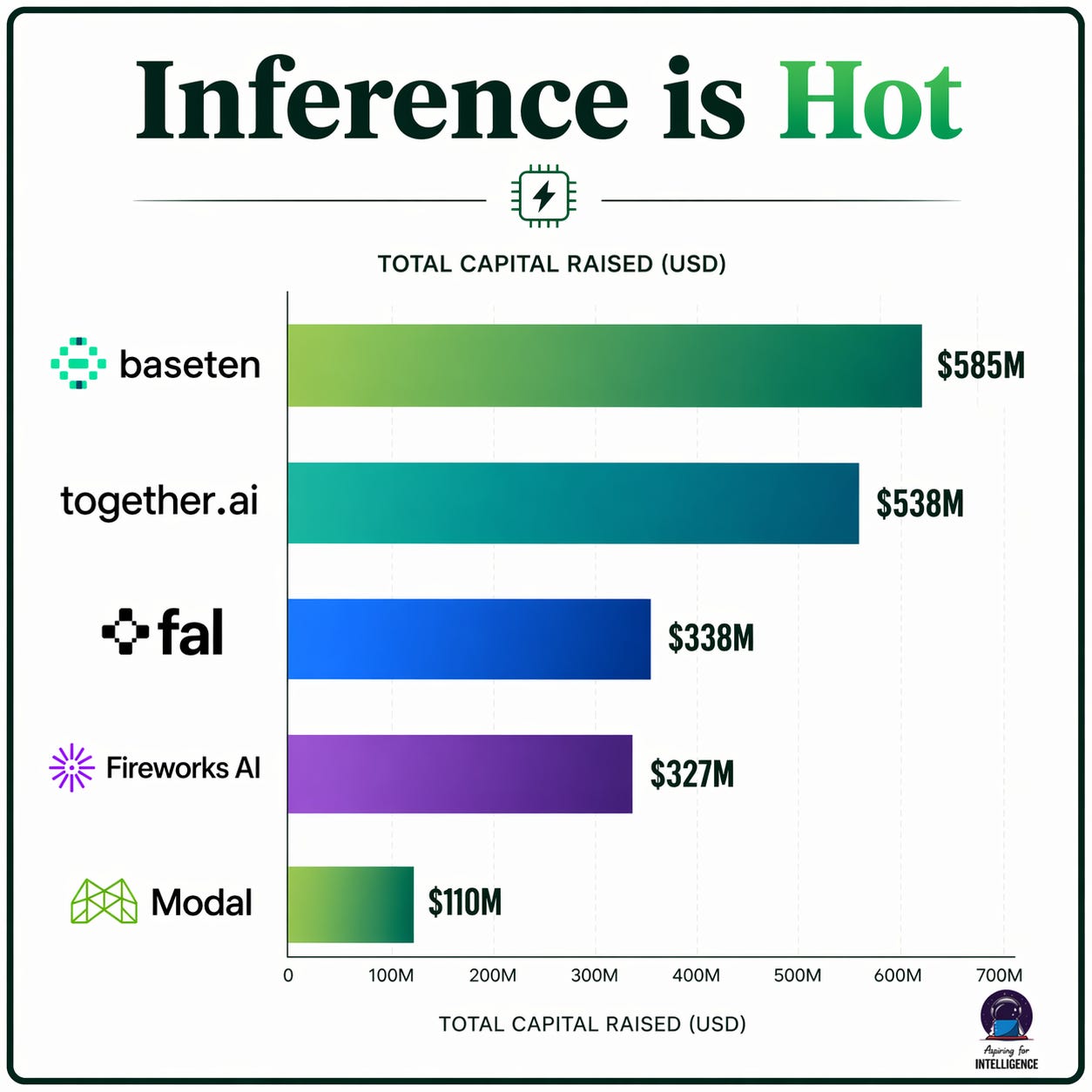
We’re seeing the same dynamic play out across the private markets. Heavy funding, rapid ARR growth, and massive valuations in categories that are fundamentally downstream of expensive compute include:
Inference optimization and RL reasoning. Companies like Together AI, Baseten, and Fireworks are building real, fast-growing businesses around making inference faster and cheaper. This is a fantastic category to be in when compute is expensive and generating more intelligence per dollar absolutely matters. On the other end, think about what happened to RealNetworks, or to Akamai’s pricing power once bandwidth got cheap. You don’t need clever compression tricks when you can just send the full stream. When compute gets cheap, you can brute-force a lot of what these techniques achieve — run a bigger model, run multiple passes, throw more inference at the problem and pick the best answer. The techniques won’t disappear, but core pricing will likely commoditize. So the question becomes whether these businesses will have to refactor to maintain durable pricing power in a world with abundant compute.
GPU access and compute brokering. CoreWeave is probably the most prominent example, but there’s a whole cohort of GPU cloud companies — Lambda Labs, Crusoe, and others — that have raised significant capital on the back of GPU scarcity. The core (dumbed down) value proposition for most of these companies is “we have allocation.” That is a terrific in a supply-constrained world. The question is how sustainable that moat is when that constraint goes away. What happens when the arb goes away?
Model training and tooling. When a single frontier training run costs tens or hundreds of millions of dollars and a failed run is a catastrophe, the willingness to pay for anything that makes that process more reliable and efficient is enormous. That math changes pretty quickly if compute costs drop by an order of magnitude.
None of this means these are bad companies or bad technologies. In fact sometimes its the exact opposite. The pattern from prior cycles isn’t that the scarce-resource companies go to zero — Exxon is still enormous, Akamai still exists, AWS still prints money.
The point is that during scarcity, the market tends to OVERVALUE these layers and UNDERVALUE what comes next. The best returns in the oil era didn’t come from refining. The best returns in the internet era didn’t come from owning fiber. And the best returns in AI might not come from the layers that look most valuable right now.
Where Will Value Migrate In The Abundance Era?
When compute and infrastructure are no longer the bottleneck, AI goes from supply-constrained to demand-constrained. And in demand-constrained markets, the moats that have always mattered reassert themselves: user attention, distribution, brand, workflow integration, and switching costs.
So what areas do we think will flourish in an era of cheap compute?
Vertical applications that own the user relationship. Companies embedded in real workflows with proprietary data accumulated through thousands of customer interactions — legal AI built on real contract negotiations, security platforms with proprietary threat data, healthcare AI woven into clinical decisions. The test: if every model becomes equally capable and cheap tomorrow, does your company still matter? If yes because you own the distribution or you’re too embedded to rip out, you’re on the right side. These companies‘ margins actually expand as compute gets cheaper, which is the opposite of what happens to the optimization layer.
Physical AI, robotics, and space. When compute is cheap, the constraint shifts from „can we run the model“ to „can we interact with the physical world.“ Companies like Physical Intelligence, Starcloud, Echodyne, and the wave of autonomous systems startups are building in a domain where the moats look nothing like software AI — manufacturing, hardware design, regulatory approval, and supply chains. You can’t GitHub clone a robot factory. There’s a version of this story where the pure-software AI crowd gets caught off guard by how much value migrates toward the intersection of intelligence and atoms, precisely because that’s where the unglamorous barriers to entry still exist.
Security, safety, and governance. This category is still in its infancy today, which is the point. When every company goes from a handful of AI tools to dozens of agents, the pain shifts from access to control — governing agent behavior, auditing outputs, managing security and compliance. Think about what happened in cloud: nobody cared about cloud security when companies had three workloads. When cloud became ubiquitous, Palo Alto Networks and CrowdStrike built massive businesses around securing it. AI governance — companies building the equivalent of model-level audit trails, agent access controls, output monitoring — is on that same curve, just earlier.
Categories that don’t even exist yet i.e the big question mark. Automobiles and commercial aviation came 30+ years after oil was struck. Radio and TV arrived decades after Edison’s first power station opened. The internet took more than a decade to explode. The truth is, the categories that will generate the most value in the age of AI haven’t even been discovered yet. Which makes this whole era even more exciting!
What Are You Building For?
Today, the most scarce resource in the AI supercycle is compute – spanning GPUs, memory, bandwidth, data centers, and energy. That single bottleneck is driving billions in record profits and soaring stock prices for public companies building around this layer, as well as the many private inference and GPU optimization startups collectively growing like a weed. But if prior cycles teach us any lessons, its that patterns in early innovation waves are temporary. Oil refining was scarce until it wasn’t. Bandwidth was scarce until the telecom bust accidentally created the abundance. Cloud infrastructure was scarce until AWS turned it into a utility.
When the scarcity breaks, the effects are real. Pricing power shifts. Margins compress at the resource layer. Value moves up the stack. None of this means the compute companies disappear — Exxon is still enormous and the hyperscalers print money. But the outsized returns tend to come from the companies that were building for what abundance makes possible, not from the ones optimizing around what scarcity made painful.
The question for founders and investors is a simple one: are you building for the scarcity era, or the abundance era? Because the flip is coming.
Source: https://aspiringforintelligence.substack.com/p/from-scarcity-to-abundance





:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25582800/helicopter_original.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25582782/helicopter_watermarked.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25582794/rug_original.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25582787/rug_watermarked.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25582928/motorcycle_original.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25582929/motorcycle_watermarked.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25584251/PXL_20240819_174352535.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25584252/PXL_20240819_174352535_2_copy.jpg)