And the SpaceX/Cursor deal is exposing just how in demand GPU clusters are.
Even the favorite shoe brand of every tech bro in 2017 is looking to get into the compute game…
Tracy Alloway@tracyalloway
Allbirds, the shoe brand, now says it’s an AI compute company.
2:31 PM · Apr 15, 2026 · 4,29 MIO. Views
376 Replies · 692 Reposts · 9760 Likes
All of this is real. The scarcity is real. And the companies capitalizing on it are posting incredible numbers and building meaningful businesses. But here’s the thing: every prior technology cycle had a scarce resource at its center, and every time, that scarcity eventually broke. When it did, the value map reshuffled dramatically – and the companies that looked unassailable during the scarcity era often weren’t the long-term winners.
Our view: the venture landscape is dramatically overweighting what is in demand today versus what is going to be in demand for the next ten years.
We’ve Seen This Before
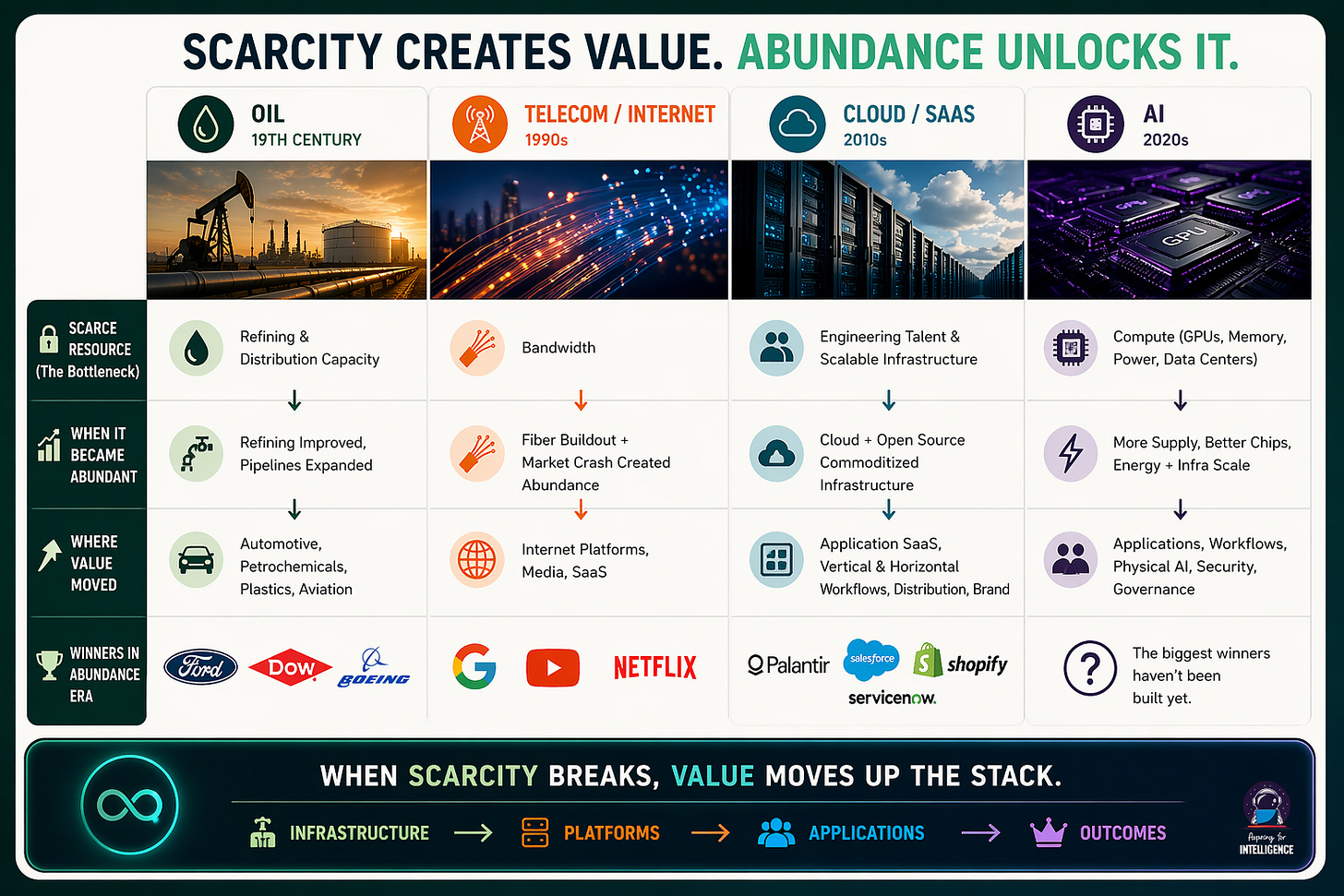
Every prior innovation cycle started with a scarce resource that eventually became abundant.
Oil in the 19th century
In the late 1800s, crude was actually plentiful. Wildcatters kept finding more of it. The real bottleneck was refining capacity and distribution, which is why John D. Rockefeller built Standard Oil around those layers rather than drilling. But once refining technology matured and pipeline networks expanded, that bottleneck broke too. And the interesting thing is what came next: the automotive economy, petrochemicals, plastics, commercial aviation. Ford’s Model T only made sense because fuel was getting cheap. The plastics revolution required abundant petroleum feedstocks. These were entire industries that nobody was really thinking about during the scarcity era, and they ended up dwarfing the value of oil extraction and refining combined.
Telecom in the 1990s
The telecom boom of the late ’90s followed a similar arc, with a twist. Bandwidth was the scarce resource, and telecoms raised hundreds of billions to control it. Then the bubble burst; and the bust created the abundance. All that fiber didn’t disappear when Global Crossing and WorldCom went bankrupt. It got bought at pennies on the dollar. What happened next is instructive. Google, YouTube, Netflix, Spotify — none of these businesses were economically viable at 1999 bandwidth prices. They needed cheap bandwidth to exist at all. Meanwhile, the companies that had been valuable specifically because bandwidth was expensive got crushed. RealNetworks, once worth over $30 billion for its streaming compression tech, became irrelevant almost overnight. Why bother with clever compression when you can just send the full stream? CDN technology went from a high-margin standalone business to a feature baked into cloud platforms. Even Salesforce and the broader SaaS model were downstream beneficiaries of cheap, reliable connectivity.
The winners weren’t the ones who owned the scarce resource or built optimization tricks around it. They were the ones who built for the world where it was cheap.
Cloud / SaaS in the 2010s
Cloud and SaaS repeated the pattern one more time. Through the 2010s, the bottleneck was engineering talent and scalable infrastructure. Engineer salaries soared. Companies fought viciously over hiring. A legendary show satirizing Silicon Valley culture became required viewing. SaaS pricing reflected the genuine cost of building and maintaining good software. Then AWS, Azure, and GCP commoditized infrastructure, open source commoditized components, and value migrated again — from horizontal platforms to vertical SaaS with deep domain knowledge, from engineering as the moat to distribution as the moat, from building software to configuring it. Some of the most valuable late-stage SaaS companies weren’t particularly technically impressive. They just had the best go-to-market and the deepest workflow integration. Same story: when the scarce resource got cheap, value moved up the stack toward whoever was closest to the end user and the actual problem being solved.
These prior waves prove that as the scarce resource becomes abundant, value migrates UP THE STACK. Applications, workflows, and things that touch the user accrue value; “optimization” layers that were valuable during scarcity get squeezed.
Bandwidth prices in the 90s and early 2000s got cheap fast
What’s Priced For Scarcity Today?
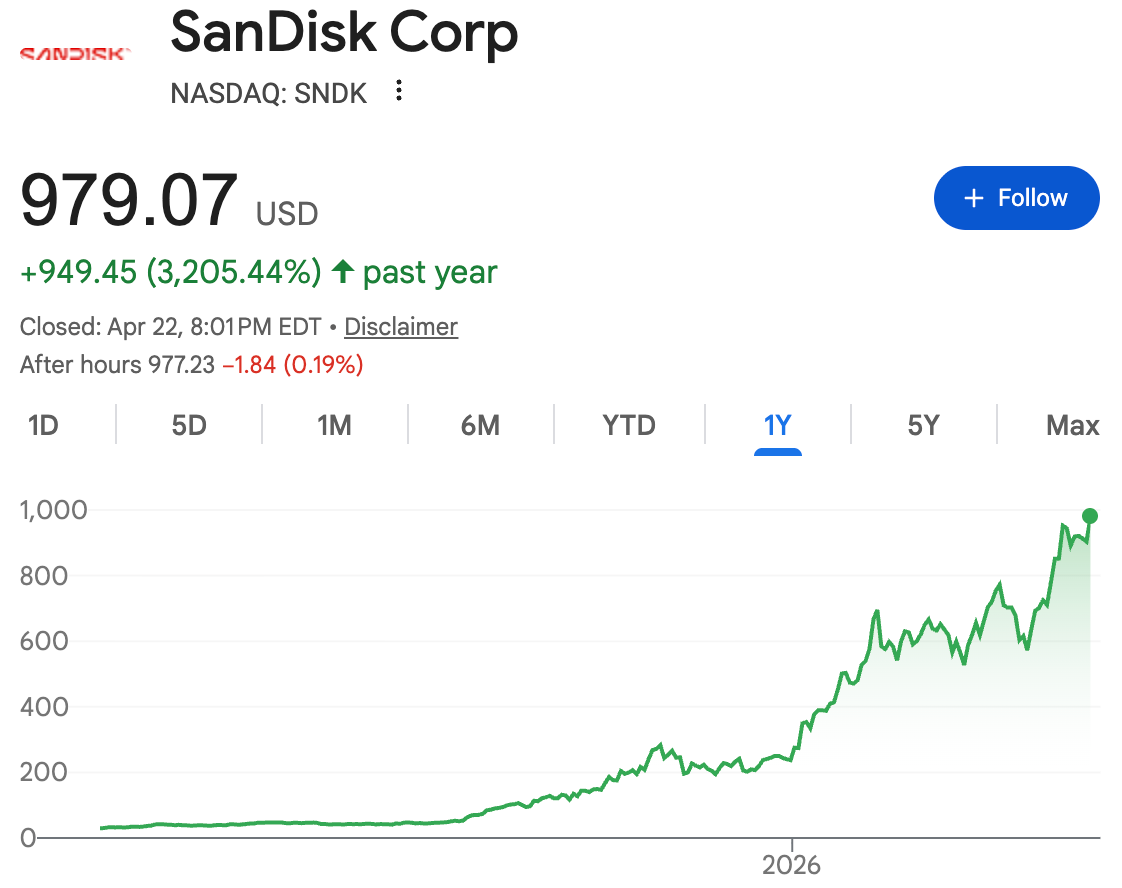
It feels like fundraising and commercialization in the AI market today is heavily skewed towards companies capitalizing on the compute shortages. On the public side, chip companies like Nvidia have been making hay for the past few years, but nearly every company across memory (Sandisk, SK Hynix), semis (TSMC, AMD), and power (Bloom Energy, Vistra) have been seeing record revenues, profits, and a ripping stock. This makes sense — during scarcity, the resource providers always have the best economics. The question is how much of this is structural versus cyclical.
When a 35 year old company has what everyone wants
We’re seeing the same dynamic play out across the private markets. Heavy funding, rapid ARR growth, and massive valuations in categories that are fundamentally downstream of expensive compute include:
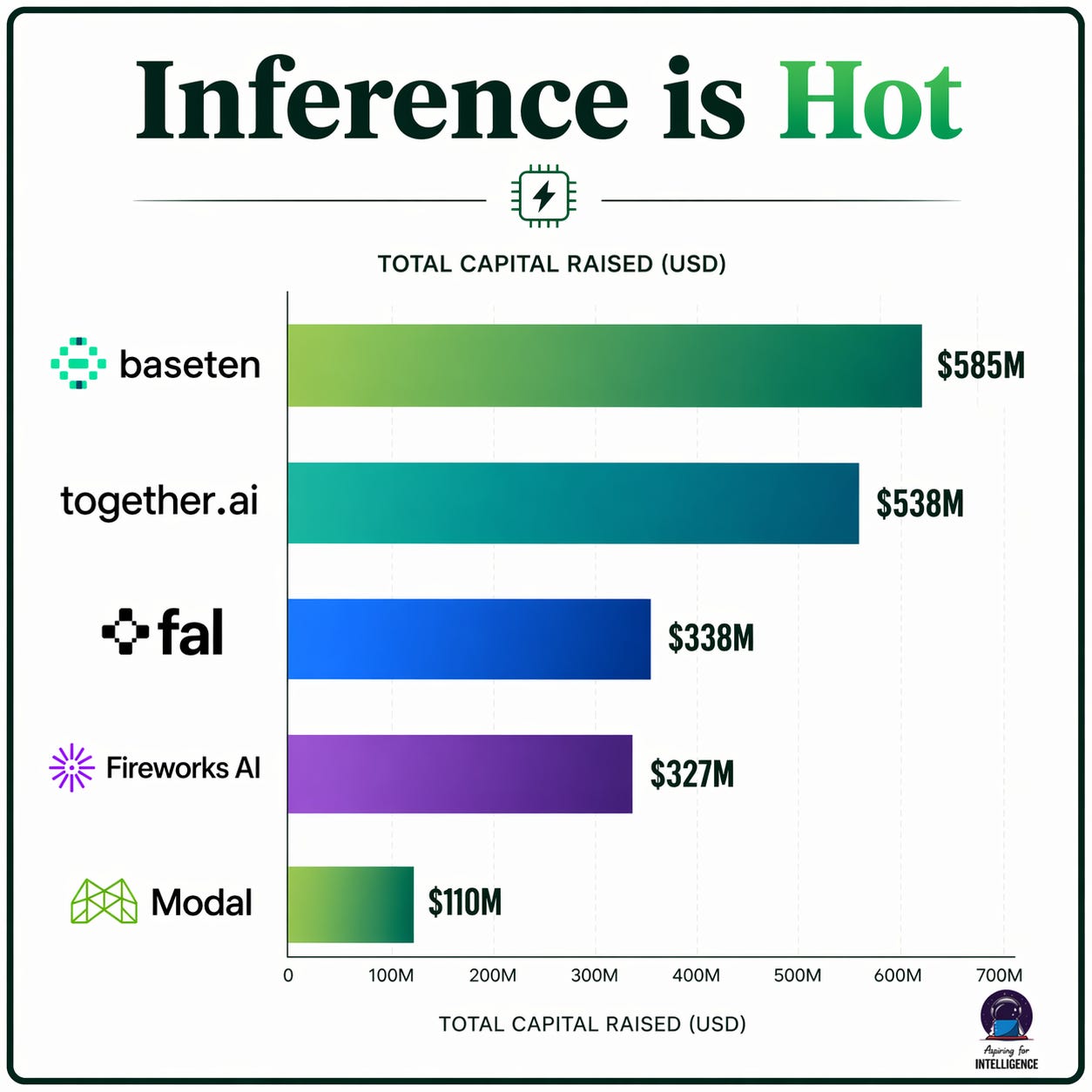
Inference optimization and RL reasoning. Companies like Together AI, Baseten, and Fireworks are building real, fast-growing businesses around making inference faster and cheaper. This is a fantastic category to be in when compute is expensive and generating more intelligence per dollar absolutely matters. On the other end, think about what happened to RealNetworks, or to Akamai’s pricing power once bandwidth got cheap. You don’t need clever compression tricks when you can just send the full stream. When compute gets cheap, you can brute-force a lot of what these techniques achieve — run a bigger model, run multiple passes, throw more inference at the problem and pick the best answer. The techniques won’t disappear, but core pricing will likely commoditize. So the question becomes whether these businesses will have to refactor to maintain durable pricing power in a world with abundant compute.
GPU access and compute brokering. CoreWeave is probably the most prominent example, but there’s a whole cohort of GPU cloud companies — Lambda Labs, Crusoe, and others — that have raised significant capital on the back of GPU scarcity. The core (dumbed down) value proposition for most of these companies is “we have allocation.” That is a terrific in a supply-constrained world. The question is how sustainable that moat is when that constraint goes away. What happens when the arb goes away?
Model training and tooling. When a single frontier training run costs tens or hundreds of millions of dollars and a failed run is a catastrophe, the willingness to pay for anything that makes that process more reliable and efficient is enormous. That math changes pretty quickly if compute costs drop by an order of magnitude.
None of this means these are bad companies or bad technologies. In fact sometimes its the exact opposite. The pattern from prior cycles isn’t that the scarce-resource companies go to zero — Exxon is still enormous, Akamai still exists, AWS still prints money.
The point is that during scarcity, the market tends to OVERVALUE these layers and UNDERVALUE what comes next. The best returns in the oil era didn’t come from refining. The best returns in the internet era didn’t come from owning fiber. And the best returns in AI might not come from the layers that look most valuable right now.
Where Will Value Migrate In The Abundance Era?
When compute and infrastructure are no longer the bottleneck, AI goes from supply-constrained to demand-constrained. And in demand-constrained markets, the moats that have always mattered reassert themselves: user attention, distribution, brand, workflow integration, and switching costs.
So what areas do we think will flourish in an era of cheap compute?
Vertical applications that own the user relationship. Companies embedded in real workflows with proprietary data accumulated through thousands of customer interactions — legal AI built on real contract negotiations, security platforms with proprietary threat data, healthcare AI woven into clinical decisions. The test: if every model becomes equally capable and cheap tomorrow, does your company still matter? If yes because you own the distribution or you’re too embedded to rip out, you’re on the right side. These companies‘ margins actually expand as compute gets cheaper, which is the opposite of what happens to the optimization layer.
Physical AI, robotics, and space. When compute is cheap, the constraint shifts from „can we run the model“ to „can we interact with the physical world.“ Companies like Physical Intelligence, Starcloud, Echodyne, and the wave of autonomous systems startups are building in a domain where the moats look nothing like software AI — manufacturing, hardware design, regulatory approval, and supply chains. You can’t GitHub clone a robot factory. There’s a version of this story where the pure-software AI crowd gets caught off guard by how much value migrates toward the intersection of intelligence and atoms, precisely because that’s where the unglamorous barriers to entry still exist.
Security, safety, and governance. This category is still in its infancy today, which is the point. When every company goes from a handful of AI tools to dozens of agents, the pain shifts from access to control — governing agent behavior, auditing outputs, managing security and compliance. Think about what happened in cloud: nobody cared about cloud security when companies had three workloads. When cloud became ubiquitous, Palo Alto Networks and CrowdStrike built massive businesses around securing it. AI governance — companies building the equivalent of model-level audit trails, agent access controls, output monitoring — is on that same curve, just earlier.
Categories that don’t even exist yet i.e the big question mark. Automobiles and commercial aviation came 30+ years after oil was struck. Radio and TV arrived decades after Edison’s first power station opened. The internet took more than a decade to explode. The truth is, the categories that will generate the most value in the age of AI haven’t even been discovered yet. Which makes this whole era even more exciting!
What Are You Building For?
Today, the most scarce resource in the AI supercycle is compute – spanning GPUs, memory, bandwidth, data centers, and energy. That single bottleneck is driving billions in record profits and soaring stock prices for public companies building around this layer, as well as the many private inference and GPU optimization startups collectively growing like a weed. But if prior cycles teach us any lessons, its that patterns in early innovation waves are temporary. Oil refining was scarce until it wasn’t. Bandwidth was scarce until the telecom bust accidentally created the abundance. Cloud infrastructure was scarce until AWS turned it into a utility.
When the scarcity breaks, the effects are real. Pricing power shifts. Margins compress at the resource layer. Value moves up the stack. None of this means the compute companies disappear — Exxon is still enormous and the hyperscalers print money. But the outsized returns tend to come from the companies that were building for what abundance makes possible, not from the ones optimizing around what scarcity made painful.
The question for founders and investors is a simple one: are you building for the scarcity era, or the abundance era? Because the flip is coming.
Martin Alderson argues that AI coding agents are fundamentally reshaping the build-versus-buy calculus for software, enabling organizations with technical capability to rapidly create custom internal tools that threaten to replace simpler SaaS products—particularly back-office CRUD applications and basic analytics dashboards.
Organizations are now questioning SaaS renewal quotes with double-digit annual price increases and choosing to build alternatives with AI agents, while others reduce user licenses by up to 80% by creating internal dashboards that bypass the need for vendor platforms.
The disruption poses an acute threat to SaaS companies whose valuations depend on net revenue retention above 100%—a metric that has declined from 109% in 2021 to a median of 101-106% in 2025—as back-office tools now face competition from „engineers at your customers with a spare Friday afternoon with an agent“.
We spent fifteen years watching software eat the world. Entire industries got swallowed by software – retail, media, finance – you name it, there has been incredible disruption over the past couple of decades with a proliferation of SaaS tooling. This has led to a huge swath of SaaS companies – valued, collectively, in the trillions.
In my last post debating if the cost of software has dropped 90% with AI coding agents I mainly looked at the supply side of the market. What will happen to demand for SaaS tooling if this hypothesis plays out? I’ve been thinking a lot about these second and third order effects of the changes in software engineering.
The calculus on build vs buy is starting to change. Software ate the world. Agents are going to eat SaaS.
The signals I’m seeing
The obvious place to start is simply demand starting to evaporate – especially for „simpler“ SaaS tools. I’m sure many software engineers have started to realise this – many things I’d think to find a freemium or paid service for I can get an agent to often solve in a few minutes, exactly the way I want it. The interesting thing is I didn’t even notice the shift. It just happened.
If I want an internal dashboard, I don’t even think that Retool or similar would make it easier. I just build the dashboard. If I need to re-encode videos as part of a media ingest process, I just get Claude Code to write a robust wrapper round ffmpeg – and not incur all the cost (and speed) of sending the raw files to a separate service, hitting tier limits or trying to fit another API’s mental model in my head.
This is even more pronounced for less pure software development tasks. For example, I’ve had Gemini 3 produce really high quality UI/UX mockups and wireframes in minutes – not needing to use a separate service or find some templates to start with. Equally, when I want to do a presentation, I don’t need to use a platform to make my slides look nice – I just get Claude Code to export my markdown into a nicely designed PDF.
The other, potentially more impactful, shift I’m starting to see is people really questioning renewal quotes from larger „enterprise“ SaaS companies. While this is very early, I believe this is a really important emerging behaviour. I’ve seen a few examples now where SaaS vendor X sends through their usual annual double-digit % increase in price, and now teams are starting to ask „do we actually need to pay this, or could we just build what we need ourselves?“. A year ago that would be a hypothetical question at best with a quick ’no‘ conclusion. Now it’s a real option people are putting real effort into thinking through.
Finally, most SaaS products contain many features that many customers don’t need or use. A lot of the complexity in SaaS product engineering is managing that – which evaporates overnight when you have only one customer (your organisation). And equally, this customer has complete control of the roadmap when it is the same person. No more hoping that the SaaS vendor prioritises your requests over other customers.
The maintenance objection
The key objection to this is „who maintains these apps?“. Which is a genuine, correct objection to have. Software has bugs to fix, scale problems to solve, security issues to patch and that isn’t changing.
I think firstly it’s important to point out that a lot of SaaS is poorly maintained (and in my experience, often the more expensive it is, the poorer the quality). Often, the security risk comes from having an external third party itself needing to connect and interface with internal data. If you can just move this all behind your existing VPN or access solution, you suddenly reduce your organisation’s attack surface dramatically.
On top of this, agents themselves lower maintenance cost dramatically. Some of the most painful maintenance tasks I’ve had – updating from deprecated libraries to another one with more support – are made significantly easier with agents, especially in statically typed programming ecosystems. Additionally, the biggest hesitancy with companies building internal tools is having one person know everything about it – and if they leave, all the internal knowledge goes. Agents don’t leave. And with a well thought through AGENTS.md file, they can explain the codebase to anyone in the future.
Finally, SaaS comes with maintenance problems too. A recent flashpoint I’ve seen this month from a friend is a SaaS company deciding to deprecate their existing API endpoints and move to another set of APIs, which don’t have all the same methods available. As this is an essential system, this is a huge issue and requires an enormous amount of resource to update, test and rollout the affected integrations.
I’m not suggesting that SMEs with no real software knowledge are going to suddenly replace their entire SaaS suite. What I do think is starting to happen is that organisations with some level of tech capability and understanding are going to think even more critically at their SaaS procurement and vendor lifecycle.
The economics problem for SaaS
SaaS valuations are built on two key assumptions: fast customer growth and high NRR (often exceeding 100%).
I think we can start to see a world already where demand from new customers for certain segments of tooling and apps begins to decline. That’s a problem, and will cause an increase in the sales and marketing expenditure of these companies.
However, the more insidious one is net revenue retention (NRR) declines. NRR is a measure of how much existing customers spend with you on an ongoing basis, adjusted for churn. If your NRR is at 100%, your existing cohort of customers are spending the same. If it’s less than that then they are spending less with you and/or customers are leaving overall.
Many great SaaS companies have NRR significantly above 100%. This is the beauty of a lot of SaaS business models – companies grow and require more users added to their plan. Or they need to upgrade from a lower priced tier to a higher one to gain additional features. These increases are generally very profitable. You don’t need to spend a fortune on sales and marketing to get this uptick (you already have a relationship with them) and the profit margin of adding another 100 user licenses to a SaaS product for a customer is somewhere close to infinity.
This is where I think some SaaS companies will get badly hit. People will start migrating parts of the solution away to self-built/modified internal platforms to avoid having to pay significantly more for the next pricing tier up. Or they’ll ingest the data from your platform via your APIs and build internal dashboards and reporting which means they can remove 80% of their user licenses.
Where this doesn’t work (and what still has a moat)
The obvious one is anything that requires very high uptime and SLAs. Getting to four or five 9s is really hard, and building high availability systems gets really difficult – and it’s very easy to shoot yourself in the foot building them. As such, things like payment processing and other core infrastructure are pretty safe in my eyes. You’re not (yet) going to replace Stripe and all their engineering work on core payments easily with an agent.
Equally, very high volume systems and data lakes are difficult to replace. It’s not trivial to spin up clusters for huge datasets or transaction volumes. This again requires specialised knowledge that is likely to be in short supply at your organisation, if it exists at all.
The other one is software with significant network effects – where you collaborate with people, especially external to your organisation. Slack is a great example – it’s not something you are going to replace with an in-house tool. Equally, products with rich integration ecosystems and plugin marketplaces have a real advantage here.
And companies that have proprietary datasets are still very valuable. Financial data, sales intelligence and the like stay valuable. If anything, I think these companies have a real edge as agents can leverage this data in new ways – they get more locked in.
And finally, regulation and compliance is still very important. Many industries require regulatory compliance – this isn’t going to change overnight.
This does require your organisation having the skills (internally or externally) to manage these newly created apps. I think products and people involved in SRE and DevOps are going to have a real upswing in demand. I suspect we’ll see entirely new functions and teams in companies solely dedicated to managing these new applications. This does of course have a cost, but this cost can be often managed by existing SRE or DevOps functions, or if it requires new headcount and infrastructure, amortised over a much higher number of apps.
Who’s most at risk?
To me the companies that are at serious risk are back-office tools that are really just CRUD logic – or simple dashboards and analytics on top of their customers‘ own data.
These tools often generate a lot of friction – because they don’t work exactly the way the customer wants them to – and they are tools that are the most easily replaced with agents. It’s very easy to document the existing system and tell the agent to build something, but with the pain points removed.
SaaS certainly isn’t dead. Like any major shifts in technology, there are winners and losers. I do think the bar is going to be much higher for many SaaS products that don’t have a clear moat or proprietary knowledge.
What’s going to be difficult to predict is how quickly agents can move up the value chain. I’m assuming that agents can’t manage complex database clusters – but I’m not sure that’s going to be the case for much longer.
And I’m not seeing a path for every company to suddenly replace all their SaaS spend. If anything, I think we’ll see (another) splintering in the market. Companies with strong internal technical ability vs those that don’t. This becomes yet another competitive advantage for those that do – and those that don’t will likely see dramatically increased costs as SaaS providers try and recoup some of the lost sales from the first group to the second who are less able to switch away.
But my key takeaway would be that if your product is just a SQL wrapper on a billing system, you now have thousands of competitors: engineers at your customers with a spare Friday afternoon with an agent.
In China, parents are buying smartwatches for children as young as 5, connecting them to a digital world that blends socializing with fierce competition.
Photo-Illustration: WIRED Staff; Getty Images
At what age should a kid ideally get a smartwatch? In China, parents are buying them for children as young as five. Adults want to be able to call their kids and track their location down to a specific building floor. But that’s not why children are clamoring for the devices, specifically ones made by a company called Xiaotiancai, which translates to Little Genius in English.
The watches, which launched in 2015 and cost up to $330, are a portal into an elaborate world that blends social engagement with relentless competition. Kids can use the watches to buy snacks at local shops, chat and share videos with friends, play games, and, sure, stay in touch with their families. But the main activity is accumulating as many “likes” as possible on their watch’s profile page. On the extreme end, Chinese media outlets have reported on kids who buy bots to juice their numbers, hack the watches to dox their enemies, and sometimes even find romantic partners. According to tech research firm Counterpoint Research, Little Genius accounts for nearly half of global market share for kids’ smartwatches.
Status Games
Over the past decade, Little Genius has found ways to gamify nearly every measurable activity in the life of a child—playing ping pong, posting updates, the list goes on. Earning more experience points boosts kids to a higher level, which increases the number of likes they can send to friends. It’s a game of reciprocity—you send me likes, and I’ll return the favor. One 18-year-old recently told Chinese media that she had struggled to make friends until four years ago when a classmate invited her into a Little Genius social circle. She racked up more than one million likes and became a mini-celebrity on the platform. She said she met all three of her boyfriends through the watch, two of whom she broke up with because they asked her to send erotic photos.
High like counts have become a sort of status symbol. Some enthusiastic Little Genius users have taken to RedNote (or Xiaohongshu), a prominent Chinese social media app, to hunt for new friends so as to collect more likes and badges. As video tutorials on the app explain, low-level users can only give out five likes a day to any one friend; higher-ranking users can give out 20. Because the watch limits its owner to a total of 150 friends, kids are therefore incentivized to maximize their number of high-level friends. Lower-status kids, in turn, are compelled to engage in competitive antics so they don’t get dumped by higher-ranking friends.
“They feel this sense of camaraderie and community,” said Ivy Yang, founder of New York-based consultancy Wavelet Strategy, who has studied Little Genius. “They have a whole world.” But Yang expressed reservations about the way the watch seems to commodify friendship. “It’s just very transactional,” she adds.
Engagement Hacks
On RedNote/Xiaohongshu, people post videos on circumventing Little Genius’s daily like limits, with titles such as “First in the world! Unlimited likes on Little Genius new homepage!” The competitive pressure has also spawned businesses that promise to help kids boost their metrics. Some high-ranking users sell their old accounts. Others sell bots that send likes or offer to help keep accounts active while the owner of a watch is in class.
Get enough likes—say, 800,000—and you become a “big shot” in the Little Genius community. Last month, a Chinese media outlet reported that a 17-year-old with more than 2 million likes used her online clout to sell bots and old accounts, earning her more than $8,000 in a year. Though she enjoyed the fame that the smartwatch brought her, she said she left the platform after getting into fights with other Little Genius “big shots” and facing cyberbullying.
In September, a Beijing-based organization called China’s Child Safety Emergency Response warned parents that children with Little Genius watches were at risk of developing dangerous relationships or falling victim to scams. Officials have also raised alarms about these hidden corners of the Little Genius universe. The Chinese government has begun drafting national safety standards for children’s watches, following growing concerns over internet addiction, content unfit for children, and overspending via the watch payment function. The company did not respond to requests for comment.
I talked to one parent who had been reluctant to buy the watch. Lin Hong, a 48-year-old mom in Beijing, worried that her nearsighted daughter, Yuanyuan, would become obsessed with its tiny screen. But once Yuanyuan turned 8, Lin relented and splurged on the device. Lin’s fears quickly materialized.
Yuanyuan loved starting her day by customizing her avatar’s appearance. She regularly sent likes to her friends and made an effort to run and jump rope to earn more points. “She would look for her smartwatch first thing every morning,” Lin said. “It was like adults, actually, they’re all a bit addicted.”
To curb her daughter’s obsession, Lin limited Yuanyuan’s time on the watch. Now she’s noticing that her daughter, who turns 9 soon, chafes at her mother’s digital supervision. “If I call her three times, she’ll finally pick up to say, ‘I’m still out, stop calling. I’m not done playing yet,’ and hang up,” Lin said. “If it’s like this, she probably won’t want to keep wearing the watch for much longer.”
OpenAI said it will allow users in the U.S. to make purchases directly through ChatGPT using a new Instant Checkout feature powered by a payment protocol for AI co-developed with Stripe.
The new chatbot shopping feature is a big step toward helping OpenAI monetize its 700 million weekly users, many of whom currently pay nothing to interact with ChatGPT, as well as a move that could eventually steal significant market share from traditional Google search advertising.
The rollout of chatbot shopping features—including the possibility of AI agents that will shop on behalf of users—could also upend e-commerce, radically transforming the way businesses design their websites and try to market to consumers.
OpenAI said it was rolling out its Instant Checkout feature with Etsy sellers today, but would begin adding over a million Shopify merchants, including brands such as Glossier, Skims, Spanx, and Vuori “soon.”
The company also said it was open-sourcing the Agentic Commerce Protocol, a payment standard developed in partnership with payments processor Stripe that powers the Instant Checkout feature, so that any retailer or business could decide to build a shopping integration with ChatGPT. (Stripe’s and OpenAI’s commerce protocol, in turn, supports the open-source Model Context Protocol, or MCP, that was originally developed by AI company Anthropic last year. MCP is designed to allow AI models to directly hook into the backend systems of businesses and retailers. The new Agentic Commerce Protocol also supports more conventional API calls too.)
OpenAI will take what it described as small fee from the merchant on each purchase, helping to bolster the company’s revenue at a time when it is burning through many billions of dollars each year to train and support the running of its AI models.
How it works
OpenAI had previously launched a shopping feature in ChatGPT that helped users find products that were best suited to them, but the suggested results then linked out to merchants’ websites, where a user had to complete the purchase—analogous to the way a Google search works.
When a ChatGPT user asks a shopping-related question—such as “the best hiking boots for me that cost under $150” or “possible birthday gifts for my 10-year old nephew”—the chatbot will still respond with product suggestions. Under the new system, if a user likes one of the suggestions and Instant Checkout is enabled, they will be able to click a “Buy” button in the chatbot response and confirm their order, shipping, and payment details without ever leaving the chat.
OpenAI said its “product results are organic and unsponsored, ranked purely on relevance to the user.” The company also emphasized that the results are not affected by the fee the merchant pays it to support Instant Checkout.
Then, to determine which merchants that carry that particular product should be surfaced for the user, “ChatGPT considers factors like availability, price, quality, whether a merchant is the primary seller, and whether Instant Checkout is enabled,” when displaying results, the company said.
OpenAI said that ChatGPT subscribers, who pay a monthly fee for premium features, would be able to use the same credit or debit card to which they charge their subscription or store alternate payment methods to use.
OpenAI’s decision to launch the shopping feature using Stripe’s Agentic Commerce Protocol will be a big boost for that payment standard, which can be used across different AI platforms and also works with different payment processors—although it is easier to integrate for existing Stripe customers. The protocol works by creating an encrypted token for payment details and other sensitive data.
Currently, OpenAI says that the user remains in control, having to explicitly agree to each step of the purchasing process before any action is taken. But it is easy to imagine that in the future, users may be able to authorize ChatGPT or other AI models to act more “agentically” and actually make purchases for the user based on a prompt, without having to check back in with a user.
The fact that users never have to leave the chat interface to make the purchase may pose a challenge to Alphabet’s Google, which makes most of its money by referring users to companies’ websites. Although Google may be able to roll out similar shopping features within its Gemini chatbot or “AI Mode” in Google Search, it’s unclear whether what it could charge for transactions completed in these AI-native ways would compensate for any loss in referral revenue and what the opportunities would be for the display of other advertising around chatbot queries.
The CMG Active Listening scandal involves Cox Media Group (CMG), a major American media company, which admitted to using „Active Listening“ technology that allegedly captures conversations through smartphone microphones and smart devices to target users with hyper-specific advertisements[1][2][3]. This revelation has sparked significant controversy and prompted responses from major American tech companies.
American Tech Companies Listed in CMG’s Presentations
Companies Named as Partners
According to leaked CMG pitch decks obtained by 404 Media, the following American tech giants were explicitly identified as CMG partners or clients in their Active Listening program[4][5][6]:
Google (including Google Ads and Bing search)
Meta (Facebook’s parent company)
Amazon (Amazon Ads)
Microsoft (including Bing search engine)
Tech Company Responses and Denials
Google’s Response:
Google took the most decisive action, removing CMG from its Partners Program immediately after the 404 Media report was published[1][4][5]. A Google spokesperson stated: „All advertisers must comply with all applicable laws and regulations as well as our Google Ads policies, and when we identify ads or advertisers that violate these policies, we will take appropriate action“[6].
Meta’s Response:
Meta denied any involvement in the Active Listening program and announced an investigation into whether CMG violated Facebook’s terms of service[7][4]. A Meta spokesperson told Newsweek: „Meta does not use your phone’s microphone for ads, and we’ve been public about this for years. We are reaching out to CMG to clarify that their program is not based on Meta data“[8][9].
Amazon’s Response:
Amazon completely denied any collaboration with CMG on the Active Listening program[4][6]. An Amazon spokesperson stated: „Amazon Ads has never worked with CMG on this program and has no plans to do so“[9][10].
Microsoft’s Response:
While Microsoft was mentioned in the pitch deck as a partner through its Bing search engine[4][11], the company has not provided a public response to the allegations at the time of these reports.
Apple’s Response:
Although not directly implicated as a CMG partner, Apple responded to the controversy by clarifying that such practices would violate its App Store guidelines[12]. Apple emphasized that apps must request „explicit user consent and provide a clear visual and/or audible indication when recording, logging, or otherwise making a record of user activity“[12].
How the Active Listening Technology Allegedly Works
According to CMG’s marketing materials, the Active Listening system operates by[1][13][14]:
Real-time voice data collection through smartphone microphones, smart TVs, and other connected devices
AI analysis of conversations to identify consumer intent and purchasing signals
Data integration with behavioral data from over 470 sources
Targeted advertising delivery through various platforms including streaming services, social media, and search engines
Geographic targeting within 10-mile ($100/day) or 20-mile ($200/day) radius
CMG’s pitch deck boldly stated: „Yes, Our Phones Are Listening to Us“ and claimed the technology could „identify buyers based on casual conversations in real-time“[14][15][9].
Legal and Privacy Implications
The scandal has raised significant legal and privacy concerns[16][17]. Senator Marsha Blackburn sent letters to CMG, Google, and Meta demanding answers about the extent of Active Listening deployment and requesting copies of the investor presentation[17].
CMG initially defended the practice as legal, claiming that microphone access permissions are typically buried in the fine print of lengthy terms of service agreements that users rarely read thoroughly[14][18]. However, privacy experts note that such practices would likely violate GDPR regulations in Europe and potentially face legal challenges in various US jurisdictions[19][16].
Current Status
Following the public backlash, CMG has:
Removed all references to Active Listening from its website[3][20]
Claimed the presentation contained „outdated materials for a product that CMG Local Solutions no longer offers“[7][8]
Stated that while the product „never listened to customers, it has been discontinued to avoid misperceptions“[8]
The scandal has reignited long-standing consumer suspicions about device surveillance and targeted advertising, with many users reporting eerily accurate ads that seemed to reflect their private conversations[13][21][22].
The web’s collective memory is stored in the servers of the Internet Archive. Legal battles threaten to wipe it all away.
If you step into the headquarters of the Internet Archive on a Friday after lunch, when it offers public tours, chances are you’ll be greeted by its founder and merriest cheerleader, Brewster Kahle.
You cannot miss the building; it looks like it was designed for some sort of Grecian-themed Las Vegas attraction and plopped down at random in San Francisco’s foggy, mellow Richmond district. Once you pass the entrance’s white Corinthian columns, Kahle will show you the vintage Prince of Persia arcade game and a gramophone that can play century-old phonograph cylinders on display in the foyer. He’ll lead you into the great room, filled with rows of wooden pews sloping toward a pulpit. Baroque ceiling moldings frame a grand stained glass dome. Before it was the Archive’s headquarters, the building housed a Christian Science church.
I made this pilgrimage on a breezy afternoon last May. Along with around a dozen other visitors, I followed Kahle, 63, clad in a rumpled orange button-down and round wire-rimmed glasses, as he showed us his life’s work. When the afternoon light hits the great hall’s dome, it gives everyone a halo. Especially Kahle, whose silver curls catch the sun and who preaches his gospel with an amiable evangelism, speaking with his hands and laughing easily. “I think people are feeling run over by technology these days,” Kahle says. “We need to rehumanize it.”
In the great room, where the tour ends, hundreds of colorful, handmade clay statues line the walls. They represent the Internet Archive’s employees, Kahle’s quirky way of immortalizing his circle. They are beautiful and weird, but they’re not the grand finale. Against the back wall, where one might find confessionals in a different kind of church, there’s a tower of humming black servers. These servers hold around 10 percent of the Internet Archive’s vast digital holdings, which includes 835 billion web pages, 44 million books and texts, and 15 million audio recordings, among other artifacts. Tiny lights on each server blink on and off each time someone opens an old webpage or checks out a book or otherwise uses the Archive’s services. The constant, arrhythmic flickers make for a hypnotic light show. Nobody looks more delighted about this display than Kahle.
It is no exaggeration to say that digital archiving as we know it would not exist without the Internet Archive—and that, as the world’s knowledge repositories increasingly go online, archiving as we know it would not be as functional. Its most famous project, the Wayback Machine, is a repository of web pages that functions as an unparalleled record of the internet. Zoomed out, the Internet Archive is one of the most important historical-preservation organizations in the world. The Wayback Machine has assumed a default position as a safety valve against digital oblivion. The rhapsodic regard the Internet Archive inspires is earned—without it, the world would lose its best public resource on internet history.
Its employees are some of its most devoted congregants. “It is the best of the old internet, and it’s the best of old San Francisco, and neither one of those things really exist in large measures anymore,” says the Internet Archive’s director of library services, Chris Freeland, another longtime staffer, who loves cycling and favors black nail polish. “It’s a window into the late-’90s web ethos and late-’90s San Francisco culture—the crunchy side, before it got all tech bro. It’s utopian, it’s idealistic.”
But the Internet Archive also has its foes. Since 2020, it’s been mired in legal battles. In Hachette v. Internet Archive, book publishers complained that the nonprofit infringed on copyright by loaning out digitized versions of physical books. In UMG Recordings v. Internet Archive, music labels have alleged that the Internet Archive infringed on copyright by digitizing recordings.
In both cases, the Internet Archive has mounted “fair use” defenses, arguing that it is permitted to use copyrighted materials as a noncommercial entity creating archival materials. In both cases, the plaintiffs characterized it as a hub for piracy. In 2023, it lost Hachette. This month, it lost an appeal in the case. The Archive could appeal once more, to the Supreme Court of the United States, but has no immediate plans to do so. (“We have not decided,” Kahle told me the day after the decision.)
A judge rebuffed an attempt to dismiss the music labels’ case earlier this year. Kahle says he’s thinking about settling, if that’s even an option.
The combined weight of these legal cases threatens to crush the Internet Archive. The UMG case could prove existential, with potential fines running into the hundreds of millions. The internet has entrusted its collective memory to this one idiosyncratic institution. It now faces the prospect of losing it all.
Kahle has been obsessed with creating a digital library since he was young, a calling that spurred him to study artificial intelligence at MIT. “I wanted to build the library of everything, and we needed computers that were big enough to be able to deal with it,” he says.
After graduating in 1982, he worked at the supercomputing startup Thinking Machines Corporation. While there, he developed a program called Wide Area Information Server (WAIS), a way to search for data on remote computers. He left to cocreate a startup of the same name, which he sold to AOL in 1995. The next year, he launched a two-headed project from his attic: “AI and IA.”That “AI” was a for-profit company called Alexa Internet—“Alexa” a nod to the Library of Alexandria—alongside the nonprofit Internet Archive. The two projects were interlinked; Alexa Internet crawled the web, then donated what it collected to the Internet Archive. Kahle couldn’t quite make the business model work. When Amazon made an offer in 1999, it seemed prudent to accept. The Everything Store paid a reported $250 million in stock for Alexa, severing the AI from IA and leaving Kahle a wealthy man.
Kahle stayed on with Alexa for a few years but left in 2002 to focus on the Internet Archive. It has been his vocation ever since. “His entire being is committed to the Archive,” says copyright scholar Pam Samuelson, who has known Kahle since the ’90s. “He lives and breathes it.”
If Silicon Valley has a Mr. Fezziwig, it’s Kahle. He’s not an ascetic; he owns a handsome black sailboat anchored in a slip at a tony yacht club. But his day-to-day life is modest. He ebikes to work and dresses like a guy who doesn’t care about clothes, and while he used to love Burning Man—he and his wife, Mary Austin, got married there in 1992—now he thinks it’s gotten too big. (Their current bougie-hippie pastime is the seasteading gathering Ephemerisle, where boaters hitch themselves together and create temporary islands in the Sacramento River Delta every July.)
What he really loves, above all, is his job.
“The story of Brewster Kahle is that of a guy who wins the lottery,” says longtime archivist Jason Scott. “And he and his wife, Mary, turned around and said, awesome, we get to be librarians now.”
Kahle is now the merry custodian to a uniquely comprehensive catalog, spanning all manner of digital and physical media, from classic video games to live recordings of concerts to magazines and newspapers to books from around the world. It recently backed up the island of Aruba’s cultural institutions. It’s an essential tool for everything from legal research—particularly around patent law—to accountability journalism. “There are other online archiving tools,” says ProPublica reporter Craig Silverman, “but none of them touch the Internet Archive.” It is, in short, a proof machine.What makes the Internet Archive unique is its willingness to push boundaries in ways that traditional libraries do not. The Library of Congress also archives the web—but only after it has notified, and often asked permission from, the websites it scrapes.
“The Internet Archive has always been a little risky,” says University of Waterloo historian Ian Milligan, who has a forthcoming book on web archiving. Its distinctive utility is entwined with its long-standing outré approach to copyright. In fact, Kahle and the Internet Archive sued the government more than two decades ago, challenging the way the Copyright Renewal Act of 1992 and the Copyright Term Extension Act of 1998 had expanded copyright law. He lost that case—but, certainly, not his desire to keep pushing.
One of those pushes came in 2005. At the time, beloved hacker Aaron Swartz was often working on Internet Archive projects, and he cocreated and led the development of a new initiative called the Open Library program along with Kahle. The goal was to create one webpage for every book in the world. Kahle saw it as an alternative to Google Books, one that wasn’t driven by commercial interests but loftier and decidedly kumbaya information-wants-to-be-free ambitions.
In addition to its attempt to catalog every book ever, the project sought to make copies available to readers. To that end, it scans physical books, then allows people to check out the digitized versions. For over a decade, it has operated using a framework called controlled digital lending (CDL), where digitized books are treated as old-fashioned physical books rather than ebooks. The books it lends out were either purchased by the Internet Archive or donated by other libraries, organizations, or individuals; according to CDL principles, libraries that own a physical copy of a book should be able to lend it digitally.
The project primarily appeals to researchers for whom specific books are hard to attain elsewhere, rather than casual readers. “Try checking out one of our books and then reading it—it’s tough going,” Kahle says. He’s not lying. A blurry scan of a physical book on a desktop screen compared to a regular ebook on a Kindle is like music from a tinny iPhone speaker versus a Bose surround sound system. Most borrowers read what they check out for less than five minutes.
Like other digital media, ebooks are typically licensed rather than sold outright, at a much higher rate than the cover price. Libraries who license ebooks get a limited number of loans; if they stop paying, the book vanishes. CDL is an attempt to give libraries more control over their inventory, and to expand access to books in a library’s collection that exist only as physical copies.
For years, publishers ignored the Internet Archive’s book-scanning spree. Finally, during the pandemic, after the Internet Archive took one liberty too many with its approach to CDL, they snapped.
In March 2020, as schools and libraries abruptly shut down, they faced a dilemma. Demand for ebooks far outstripped their ability to loan them out under restrictive licensing deals, and they had no way of lending out books that existed only in physical form. In response, the Internet Archive made a bold decision: It allowed multiple people to check out digital versions of the same book simultaneously. It called this program the National Emergency Library. “We acted at the request of librarians and educators and writers,” says Chris Freeland.
Kahle remembers feeling a vocational tug in that moment for the Internet Archive to do whatever it could to expand access. He thought they had broad support, too. “We got over 100 libraries to sign on and say ‘help us,’” Kahle says. “They stood behind the National Emergency Library and said ‘do this under our names.’”
Dave Hansen, now executive director of the nonprofit Authors Alliance, was a librarian at Duke University at the time. “We had tremendous challenges getting books for our students,” he says. “What they did was a good-faith effort.”
Not everyone agreed. Prominent writers vehemently criticized the project, as did the Authors Guild and the National Writers Union. “They are not a library. Libraries buy books and respect copyright. They are fraudsters posing as saints,” author James Gleick wrote on Twitter. (Today, Gleick maintains that the Internet Archive is not a library, though he says “fraudsters was a little harsh.”)
“They seem to work by fiat,” says Bhamati Viswanathan, a copyright lawyer who signed an amicus brief on behalf of the publishers in the Hachette case. Viswanathan thinks it was arrogant to circumvent the licensing system. “Very much like what the tech companies seem to be doing, which is, ‘we’re going to ask forgiveness, not permission.’”
The Internet Archive was in its first full-blown PR crisis. The coalition of publishing houses filed its lawsuit in June 2020, alleging that both the National Emergency Library and the Internet Archive’s broader Open Library program violated copyright. A few weeks later, the Internet Archive scuttled the National Emergency Library and reverted to its traditional, capped loan system, but it made no difference to the publishers.
The publishing houses and their supporters maintain that the Archive’s behavior harmed authors. “Internet Archive is arguing that it is OK to make and publicly distribute unauthorized copies of an author’s work to the global public,” Terrance Hart, the general counsel for the Association of American Publishers, tells WIRED. “Imagine if everyone started doing the same. The only existential threat here is the one posed by Internet Archive to the livelihoods of authors and to the copyright system itself in the digital age.”
AI Lab
WIRED’s resident AI expert Will Knight takes you to the cutting edge of this fast-changing field and beyond—keeping you informed about where AI and technology are headed. Delivered on Wednesdays.
After the lawsuit was filed, over a thousand writers signed a letter in support of libraries and the Internet Archive to be able to loan digital books, including Naomi Klein and Daniel Ellsberg. One supportive author, Chuck Wendig, had very publicly changed his mind after initially tweeting criticism. Even some writers who currently belong to and support the Authors Guild, like Joanne McNeil, were staunch supporters of the Archive. She sometimes reads out-of-print books using the lending service and still sees it as a vital tool. “I hope my books are in the Open Library project,” she says, telling me that she’s already aware that her critically acclaimed but modestly popular books aren’t widely available. “At least I’ll know that way there’s someplace someone can find them.”
The shows of support didn’t matter. The publishers didn’t back down. In March 2023, the Internet Archive lost the case. This September, it lost its appeal. The court refuted the fair use arguments, insisting that the organization had not proved that it wasn’t financially harming publishers. In the meantime, legal bills continue to pile up for the Internet Archive’s next challenge.
After the initial ruling in Hachette v. Internet Archive, the parties agreed upon settlement terms; although those terms are confidential, Kahle has confirmed that the Internet Archive can financially survive it thanks to the help of donors. If the Internet Archive decides not to file a second appeal, it will have to fulfill those settlement terms. A blow, but not a death knell.The other lawsuit may be far harder to survive. In 2023, several major record labels, including Universal Music Group, Sony, and Capitol, sued the Internet Archive over its Great 78 Project, a digital archive of a niche collection of recordings of albums in the obsolete record format known as 78s, which was used from the 1890s to the late 1950s. The complaint alleges that the project “undermines the value of music.” It lists 2,749 recordings as infringed, which means damages could potentially be over $400 million.
“One thing that you can say about the recording industry,” Pam Samuelson says, “is that there are no statutory damages that are too large for them to claim.”
As with the book publishing case, the Internet Archive’s defense hinges on fair use. It argues that preserving obsolete versions of these records, complete with the crackles and pops from the old shellac resin, makes history accessible. Copyright law is notoriously unpredictable, and some find the Internet Archive’s case shaky. “It doesn’t strike me, necessarily, as a winning fair use argument,” says Zvi Rosen, a law professor at Southern Illinois University who focuses on copyright.
James Grimmelmann, a professor of digital and information law at Cornell University, thinks the labels are “vastly exaggerating the commercial harm” from the project. (If there was a sizable audience for extremely low-quality versions of songs, he reasons, why wouldn’t the labels be putting out 78-style releases?) On average, each recording is accessed only once a month. Still, Grimmelmann isn’t convinced that will matter. “They are directly reproducing these works,” he says. “That’s a very hard lift for a judge.”
It may be years before the case is resolved, which means the uncertainty about the Internet Archive’s future is likely to linger, and potentially spread. And if it is resolved through either a settlement or a win for the recording industry, other copyright holders could be inspired to sue. “I’m worried about the blast radius from the music lawsuit,” Grimmelmann says.In Kahle’s view, the Internet Archive’s legal challenges are part of a larger story about beleaguered libraries in the United States. He likes to frame his plight as a battle against a cadre of nefarious publishers, one piece of a larger struggle to wrest back the right to own books in the digital age. (Get him started on the topic, and he’ll likely point out that both ebook distributor OverDrive and publishing company Simon & Schuster are owned by the global investment firm Kohlberg Kravis Roberts & Co.) He’s keenly aware that everything he has built is in danger. “It’s the time of Orwell but with corporations,” Kahle says. “It’s scary.”
Losing the Archive is, indeed, a frightening prospect. “There is a misperception that things on the web are forever—but they really, really aren’t,” says Craig Silverman, who thinks the nonprofit’s demise would make certain types of scholarship and reporting “way more difficult, if not impossible,” in addition to representing a disappearance of a bastion of collective memory.
Just this September, Google and the Internet Archive announced a partnership to allow people to see previous versions of websites surfaced through Google Search by linking to the Wayback Machine. Google previously offered its own cached historical websites; now it leans on a small nonprofit.
The Internet Archive also has challenges beyond its legal woes. For starters, it’s getting harder to archive things. As Mark Graham, director of the Wayback Machine, told me, the rise of apps with functions like livestreaming, especially when they’re limited to certain operating systems, presents a technical challenge. On top of that, paywalls are an obstacle, as is the sheer and ever-increasing amount of content. “There’s just so much material,” he says. “How does one know what to prioritize?”
Then there’s AI, once again. Thus far, the Internet Archive has sidestepped or been exempt from the new scrutiny on web crawling as it relates to AI training data. This June, for example, when Reddit announced that it was updating its scraping policy, it specifically noted that it was still allowing “good faith actors” like the Internet Archive to crawl it. But as opposition to rampant AI data scraping grows, the Internet Archive may yet face a new obstacle: If regulators and lawmakers are clumsy in attempts to curb permissionless AI web scraping, it could kneecap services like the Wayback Machine, which functions precisely because it can trawl and reproduce vast amounts of data.
The rise of AI has already soured some creative types on the Internet Archive’s approach to copyright. While Kahle views his creation as a library on the side of the little guy, opponents strenuously dispute this view. They paint Kahle as a tech-wolf disguised in librarian-sheep clothing, stuck in a mentality better suited for the Napster era. “The Internet Archive is really fighting the battles of 20 years ago, when it was as simple as ‘publishers bad, anything that hurts publishers good,’” says Neil Turkewitz, a former Recording Industry Association of America executive who has criticized the Archive’s copyright stances. “But that’s not the world we live in.”
When I talk to Kahle over Zoom this September, shortly after he’d learned that the Internet Archive had lost the appeal, he’s agitated—an internet prophet literally wandering around in the wilderness. He’s perched in front of jagged cliffs while hiking outside of Arles, France, a blue baseball cap pulled over his hair, cheeks extra-ruddy in the sun, his default affability tempered by a sense of despondency. He hadn’t known about the timing of the ruling in advance, so he interrupted a weeklong vacation with Mary to jump back into work crisis mode. “It’s just so depressing,” he says.
As he sits on a rock with his phone in his hand, Kahle says the US legal system is broken. He says he doesn’t think this is the end of the lawsuits. “I think the copyright cartel is on a roll,” he says. He frets that copycat cases could be on the way. He’s the most bummed-out guy I’ve ever seen on vacation in the south of France. But he’s also defiant. There’s no inkling of regret, only a renewed sense that what he’s doing is righteous. “We have such an opportunity here. It’s the dream of the internet,” he says. “It’s ours to lose.” It sounds less like a statement and more like a prayer.
“I was too poor,” he said. “And then I was too rich.”
In fact, Mr. Karp, a co-founder and the C.E.O. of Palantir Technologies, the mysterious and powerful data analytics firm, doesn’t trust himself to drive. Or ride a bike. Or ski downhill.
“I’m a dreamer,” he said. “I’ll start dreaming and then I fall over. I started doing tai chi to prevent that. It’s really, really helped with focusing on one thing at a time. If you had met me 15 years ago, two-thirds of the conversation, I’d just be dreaming.”
What would he dream about?
“Literally, it could be a walk I did five years ago,” he said. “It could be some conversation I had in grad school. Could be my family member annoyed me. Something a colleague said, like: ‘Why did they say this? What does it actually mean?’”
Mr. Karp is a lean, extremely fit billionaire with unruly salt-and-pepper curls. He is introvert-charming (something I aspire to myself). He has A.D.H.D. and can’t hide it if he is not interested in what someone is saying. After a hyper spurt of talking, he loses energy and has to recharge on the stationary bike or by reading. Even though he thinks of himself as different, he seems to like being different. He enjoys being a provocateur onstage and in interviews.
“I’m a Jewish, racially ambiguous dyslexic, so I can say anything,” he said, smiling.
Unlike many executives in Silicon Valley, Mr. Karp backed President Biden, cutting him a big check, despite skepticism about his handling of the border and his overreliance on Hollywood elites like Jeffrey Katzenberg. Now he is supporting Vice President Kamala Harris, but he still has vociferous complaints about his party.
When he donates, he said, he does it in multiples of 18 because “it’s mystical — 18 brings good luck in the tradition of kabbalah. I gave Biden $360,000.”
The 56-year-old is perfectly happy hanging out in a remote woodsy meadow alone — except for his Norwegian ski instructor, his Swiss-Portuguese chef, his Austrian assistant, his American shooting instructor and his bodyguards. (Mr. Karp, who has never married, once complained that bodyguards crimp your ability to flirt.)
“This is like introverts’ heaven,” he said, looking at his red barn from the porch of his Austrian-style house with a mezuza on the door. “You can invite people graciously. No one comes.”
The house is sparse on furniture, but Mr. Karp still worries that it is too cluttered. “I do have a Spartan thing,” he said. “I definitely feel constrained and slightly imprisoned when I have too much stuff around me.”
Asked about the dangers of artificial intelligence, Mr. Karp said, “The only solution to stop A.I. abuse is to use A.I.”Credit…Ryan David Brown for The New York Times
So how did a daydreaming doctoral student in German philosophy wind up leading a shadowy data analytics firm that has become a major American defense contractor, one that works with spy services as it charts the future of autonomous warfare?
He’s not a household name, and yet Mr. Karp is at the vanguard of what Mark Milley, the retired general and former chairman of the Joint Chiefs of Staff, has called “the most significant fundamental change in the character of war ever recorded in history.” In this new world, unorthodox Silicon Valley entrepreneurs like Mr. Karp and Elon Musk are woven into the fabric of America’s national security.
Mr. Karp is also at the white-hot center of ethical issues about whether firms like Palantir are too Big Brother, with access to so much of our personal data as we sign away our privacy. And he is in the middle of the debate about whether artificial intelligence is friend or foe, whether killer robots and disembodied A.I. will one day turn on us.
Mr. Karp’s position is that we’re hurtling toward this new world whether we like it or not. Do we want to dominate it, or do we want to be dominated by China?
Critics worry about what happens when weapons are autonomous and humans become superfluous to the killing process. Tech reflects the values of its operators, so what if it falls into the hands of a modern Caligula?
“I think a lot of the issues come back to ‘Are we in a dangerous world where you have to invest in these things?’” Mr. Karp told me, as he moved around his living room in a tai chi rhythm, wearing his house shoes, jeans and a tight white T-shirt. “And I come down to yes. All these technologies are dangerous.” He adds: “The only solution to stop A.I. abuse is to use A.I.”
Inspired by Tolkien
Palantir’s name is derived from palantíri, the seeing stones in the J.R.R. Tolkien fantasies. The company’s office in Palo Alto, Calif., features “Lord of the Rings” décor and is nicknamed the Shire.
After years under the radar, Mr. Karp is now in the public eye. He has joked that he needs a coach to teach him how to be more normal.
Born in New York and raised outside Philadelphia in a leftist family, Mr. Karp has a Jewish father who was a pediatrician and a Black mother who is an artist. They were social activists who took young Alex to civil rights marches and other protests. His uncle, Gerald D. Jaynes, is an economics and African American studies professor at Yale; his brother, Ben, is an academic who lives in Japan.
“I just think I’ve always viewed myself as I don’t fit in, and I can’t really try to,” Mr. Karp said. “My parents’ background just gave me a primordial subconscious bias that anything that involves ‘We fit in together’ does not include me.
“Yes, I think the way I explain it politically is like, if fascism comes, I will be the first or second person on the wall.”
Mr. Karp has his own unique charisma. “He’s one of a kind, to say the least,” said the Democratic strategist James Carville, who is an informal adviser to Palantir.
When I visited the Palo Alto office, Mr. Karp accidentally knocked down a visitor while demonstrating a tai chi move. He apologized, then ran off to get a printout of Goethe’s “Faust” in German, which he read aloud in an effort to show that it was better than the English translation.
“If you were to do a sitcom on Palantir, it’s equal parts Larry David, a philosophy class, tech and James Bond,” he said.
Mr. Karp at the Senate building in Washington last year. He was among the tech industry titans, including Bill Gates, Elon Musk and Sam Altman, who took part in a discussion of A.I. with lawmakers.Credit…Haiyun Jiang for The New York Times
Palantir was founded in 2003 by a gang of five, including Karp and his old Stanford Law School classmate Peter Thiel (now the company’s chairman). It was backed, in part, by nearly $2 million from In-Q-Tel, the C.I.A.’s venture capital arm.
“Saving lives and on occasion taking lives is super interesting,” Mr. Karp told me.
He described what his company does as “the finding of hidden things” — sifting through mountains of data to perceive patterns, including patterns of suspicious or aberrant behavior.
Mr. Karp does not believe in appeasement. “You scare the crap out of your adversaries,” he said. He brims with American chauvinism, boasting that we are leagues ahead of China and Russia on software.
“The tech scene in America is like the jazz scene in the 1950s,” he said in one forum. He told me: “I’m constantly telling people 86 percent of the top 50 tech companies in the world just by market cap are American — and people fall out of their chair. It’s hard for us to understand how dominant we are in certain industries.”
In the wake of 9/11, the C.I.A. bet on Palantir’s maw gobbling up data and auguring where the next terrorist attacks would come from. Palantir uses multiple databases to find the bad guy, even, as Mr. Karp put it, “if the bad guy actually works for you.”
The company is often credited with helping locate Osama bin Laden so Navy SEALs could kill him, but it’s unclear if that is true. As with many topics that came up in the course of our interviews in Washington, Palo Alto and New Hampshire, Mr. Karp zips his lips about whether his company was involved in dispatching the fiend of 9/11.
“If you have a reputation for talking about what the pope says when you meet him,” Mr. Karp explained, “you’ll never meet the pope again.”
He does crow a little about Western civilization’s resting on Palantir’s slender shoulders, noting that without its software, “you would’ve had massive terror attacks in Europe already, like Oct. 7 style.” And those attacks, he believes, would have propelled the far right to power.
Palantir does not do business with China, Russia or other countries that are opposed to the West. Mr. Thiel said the company tries to work with “more allied” and “less corrupt” governments, noting dryly that aside from their ideological stances, “with corrupt countries, you never get paid.”
“We have a consistently pro-Western view that the West has a superior way of living and organizing itself, especially if we live up to our aspirations,” Mr. Karp said. “It’s interesting how radical that is, considering it’s not, in my view, that radical.”
He added: “If you believe we should appease Iran, Russia and China by saying we’re going to be nicer and nicer and nicer, of course you’ll look at Palantir negatively. Some of these places want you to do the apology show for what you believe in, and we don’t apologize for what we believe in. I’m not going to apologize for defending the U.S. government on the border, defending the Special Ops, bringing the people home. I’m not apologizing for giving our product to Ukraine or Israel or lots of other places.”
As one Karp acquaintance put it: “Alex is principled. You just may not like his principles.”
Kara Swisher, the author of “Burn Book: A Tech Love Story,” told me: “While Palantir promises a more efficient and cost-effective way to conduct war, should our goal be to make it less expensive, onerous and painful? After all, war is not a video game, nor should it be.”
Mr. Karp’s friend Diane von Furstenberg told me that he sees himself as Batman, believing in the importance of choosing sides in a parlous world. (The New York office is called Gotham and features a statue and prints of Batman.) But some critics have a darker view, worrying about Palantir creating a “digital kill chain” and seeing Mr. Karp less as a hero than as a villain.
Back in 2016, some Democrats regarded Palantir as ominous because of Mr. Thiel’s support for former President Donald J. Trump. Later, conspiracy theories sprang up around the company’s role in OperationWarp Speed, the federal effort pushing the Covid-19 vaccine program from clinical trials to jabs in arms.
In December 2016, Donald J. Trump, then the president-elect, met with tech executives including the Palantir co-founder Peter Thiel.Credit…Drew Angerer/Getty Images
Some critics focused on Palantir’s work at the border, which helped U.S. Immigration and Customs Enforcement track down undocumented migrants for deportation. In 2019, about 70 demonstrators blocked access to the cafeteria outside the Palo Alto office. “Immigrants are welcome here, time to cancel Palantir,” they shouted.
The same year, over 200 Palantir employees, in a letter to Mr. Karp, outlined their concerns about the software that had helped ICE. And there was a campaign inside Palantir — in vain — to get him to donate the proceeds of a $49 million ICE contract to charity.
I asked Mr. Karp if Mr. Thiel’s public embrace of Mr. Trump the first time around had made life easier — in terms of getting government contracts — or harder.
“I didn’t enjoy it,” he said. “There’s a lot of reasons I cut Biden a check. I do not enjoy being protested every day. It was completely ludicrous and ridiculous. It was actually the opposite. Because Peter had supported Mr. Trump, it was actually harder to get things done.”
Did they talk about it?
“Peter and I talk about everything,” Mr. Karp said. “It’s like, yes, I definitely informed Peter, ‘This is not making our life easier.’”
Mr. Thiel did not give money to Mr. Trump or speak at his convention this time around, although he supports JD Vance, his former protégé at his venture capital firm. He said he might get more involved now because of Mr. Vance.
Palantir got its start in intelligence and defense — it now works with the Space Force — and has since sprouted across the government through an array of contracts. It helps the I.R.S. to identify tax fraud and the Food and Drug Administration to prevent supply chain disruptions and to get drugs to market quicker.
It has assisted Ukraine and Israel in sifting through seas of data to gather relevant intelligence in their wars — on how to protect special forces by mapping capabilities, how to safely transport troops and how to target drones and missiles more accurately.
In 2022, Mr. Karp took a secret trip to war-ravaged Kyiv, becoming the first major Western C.E.O. to meet with Ukraine’s president, Volodymyr Zelensky, and offering to supply his country with the technology that would allow it to be David to Russia’s Goliath. Time magazine ran a cover on Ukraine as a lab for A.I. warfare, and Palantir operatives embedded with the troops.
A Ukrainian government handout image of Mr. Karp meeting with President Volodymyr Zelensky of Ukraine and Deputy Prime Minister Mykhailo Fedorov in 2022.Credit…Office of the President of Ukraine
While Palantir’s role in helping Ukraine was heralded, its work with Israel, where targeting is more treacherous, because the enemy is parasitically entangled with civilians, is far more controversial.
“I think there’s a huge dichotomy between how the elite sees Ukraine and Israel,” Mr. Karp said. “If you go into any elite circle, pushing back against Russia is obvious, and Israel is complicated. If you go outside elite circles, it’s exactly the opposite.”
Independent analysts have said that Israel, during an April operation, could not have shot down scores of Iranian missiles and drones in mere minutes without Palantir’s tech. But Prime Minister Benjamin Netanyahu’s scorched-earth campaign in Gaza, the starving and orphaned children and the deaths of tens of thousands of civilians have drawn outrage, including some aimed at Mr. Karp and Mr. Thiel.
In May, protesters trapped Mr. Thiel inside a student building at the University of Cambridge. In recent days, senior U.S. officials have expressed doubts about Israel’s conduct of the war.
Mr. Karp’s position on backing Israel is adamantine. The company took out a full-page ad in The New York Times last year stating that “Palantir stands with Israel.”
“It’s like we have a double standard on Israel,” he told me. If the Oct. 7 attack had happened in America, he said, we would turn the hiding place of our enemies “into a parking lot. There would be no more tunnels.”
As Mr. Karp told CNBC in March: “We’ve lost employees. I’m sure we’ll lose more employees. If you have a position that does not cost you ever to lose an employee, it’s not a position.”
He told me, “If you believe that the West should lose and you believe that the only way to defend yourself is always with words and not with actions, you should be skeptical of us.”
He added: “I always think it’s hard because where the critics are right is what we do is morally complex. If you’re supporting the West with products that are used at war, you can’t pretend that there’s a simple answer.”
Does he have any qualms about what his company does?
“I’d have many more qualms if I thought our adversaries were committed to anything like the rule of law,” he said, adding: “A lot of this does come down to, do you think America is a beacon of good or not? I think a lot of the critics, what they actually believe is America is not a force for good.” His feeling is this: “Without being Pollyannaish, idiotic or pretending like any country’s been perfect or there’s not injustice, at the margin, would you want a world where America is stronger, healthy and more powerful, or not?”
In 2019, demonstrators protested the role of Palantir Technologies in aiding U.S. Immigration and Customs Enforcement.Credit…Shannon Stapleton/Reuters
Asked about the impending TikTok ban, he said he’s “very in favor.”
“I do not think you should allow an adversary to control an algorithm that is specifically designed to make us slower, more divided and arguably less cognitively fit,” he said.
He considered the anti-Israel demonstrations such “an infection inside society,” reflecting “a pagan religion of mediocrity and discrimination and intolerance, and violence,” that he offered 180 jobs to students who were fearful of staying in college because of a spike in antisemitism on campuses.
“Palantir is a much better diploma,” he told me. “Honestly, it’s helping us, because there are very talented people at the Ivy League, and they’re like, ‘Get me out of here!’”
Mr. Karp sometimes gets emotional in his defense of Palantir. In June, when he received an award named in honor of Dwight Eisenhower at a D.C. gala for national security executives, he teared up. He said that when he lived in Germany, he often thought about the young men from Iowa and Kansas who risked their lives “to free people like me” during World War II. He said he was honored to receive an award named after the president who had integrated schools by force.
Claiming that his products “changed the course of history by stopping terror attacks,” Mr. Karp said that Palantir had also “protected our men and women on the battlefield” and “taken the lives of our enemies, and I don’t think that’s something to be ashamed of.”
He told the gala audience about being “yelled at” by people who “call themselves progressives.”
“I actually am a progressive,” he said. “I want less war. You only stop war by having the best technology and by scaring the bejabers — I’m trying to be nice here — out of our adversaries. If they are not scared, they don’t wake up scared, they don’t go to bed scared, they don’t fear that the wrath of America will come down on them, they will attack us. They will attack us everywhere.”
He added that “we in the corporate world” have “to grow a spine” on issues like the Ivy League protesters: “If we do not win the battle of ideas and reassert basic norms and the basic, obvious idea that America is a noble, great, wonderful aspiration of a dream that we are blessed to be part of, we will have a much, much worse world for all of us.”
How It Started
Mr. Karp practicing tai chi at his home in New Hampshire.Credit…Ryan David Brown for The New York Times
The wild origin story of Palantir plays like a spy satire.
After graduating from Haverford College, Mr. Karp went to Stanford Law School, which he called “the worst three years of my adult life.”
He wasn’t interested in his classmates’ obsession with landing prestigious jobs at top law firms. “I learned at law school that I cannot do something I do not believe in,” he said, “even if it’s just turning a wrench.”
He met Mr. Thiel, a fellow student, and they immediately hit it off, trash-talking law school and, over beers, debating socialism vs. capitalism. “We argued like feral animals,” Mr. Karp told Michael Steinberger in a New York Times Magazine piece.
The liberal Heidegger fan and the conservative René Girard fan made strange bedfellows, but that’s probably what drew them together.
“I think we bonded on this intellectual level where he was this crazy leftist and I was this crazy right-wing person,” Mr. Thiel told me, “but we somehow talked to each other.”
“Alex did the Ph.D. thing,“ he continued, “which was, in some ways, a very, very insane thing to do after law school, but I was positive on it, because it sounded more interesting than working at a law firm.”
Mr. Karp received his doctorate in neoclassical social theory from Goethe University Frankfurt. He reconnected with Mr. Thiel in 2002, while working at the Jewish Philanthropy Partnership in San Francisco. The two began doing “vague brainstorming,” as Mr. Thiel put it, about a business they could start.
Mr. Thiel thought he could figure out how to find terrorists by using some of the paradigms developed at PayPal, which he helped found, to uncover patterns of fraud.
“I was just always super annoyed when, every time you go to the airport, you had to take off a shoe or you had to go through all this security theater, which was both somewhat taxing but probably had very little to do with actual security,” Mr. Thiel said.
They brought in some software engineers.
“It was two and a half years after 9/11, and you’re starting a software company with people who know nothing about the C.I.A. or any of these organizations,” Mr. Thiel recalled.
It was all very cloak-and-dagger, in an Inspector Clouseau way. They decided to seek out John Poindexter, a retired rear admiral who was dubbed the godfather of modern surveillance; Admiral Poindexter had been forced to resign as President Ronald Reagan’s national security adviser after the Iran-Contra scandal broke. After 9/11, he worked at the Pentagon on a surveillance program called Total Information Awareness.
During the meeting, Mr. Thiel said he felt he was in the presence of a medal-festooned, Machiavelli-loving member of the military brass out of “Dr. Strangelove,” with “a LARPing vibe.”
“We had a hunch that there was a room marked ‘Super-Duper Computer,’ and if you went inside, it was just an empty room,” Mr. Thiel said. They feared their budding algorithm “would end up in a broom closet in the Pentagon,” so they moved on.
In 2005, Mr. Thiel asked Mr. Karp to be the frontman of a company with few employees, no contracts, no investors, no office and no functional tech. “It charitably could have been described as a work in progress,” Mr. Thiel said.
Palantir’s headquarters in Palo Alto, Calif.Credit…Jim Wilson/The New York Times
Mr. Karp and his motley crew got a bunch of desks and explained to clients that they were unmanned because the (fictional) engineers were coming in later.
“God knows why Peter picked me as co-founder,” said Mr. Karp, who had to learn about coding on the job. “It was, in all modesty, a very good choice.”
Mr. Thiel explained: “In some ways, Alex doesn’t look like a salesperson from central casting you would send to the C.I.A. The formulation I always have is that if you’re trying to sell something to somebody, the basic paradox is you have to be just like them, so they can trust you — but you have to be very different from them so that they think you have something they don’t have.”
He said that Mr. Karp would not be suited to running Airbnb or Uber “or some mass consumer product.” But Palantir, he said, “is connected with this great set of geopolitical questions about the Western world versus the rising authoritarian powers. So if we can get our governments to function somewhat better, it’s a way to rebalance things in the direction of the West.”
“Normally,” Mr. Thiel continued, “these are bad ideas to have as a company. They’re too abstract, too idealistic. But I think something like this was necessary in the Palantir case. If you didn’t get some energy from thinking about these things, man, we would’ve sold the company after three years.”
Mr. Karp could not have been more of an outsider, to Silicon Valley and to Washington. He and his engineers had to buy suits for their visits to the capital. “We had no believers,” he said. “I kept telling Palantirians to call me Alex, and they kept calling me Dr. Karp. Then I realized the only thing they could believe in was that I had a Ph.D.”
The first few years, when tech investors were more interested in programs that let you play games on your phone, were rough. “We were like pariahs,” Mr. Karp said. “We couldn’t get meetings. If they did, it was a favor to Peter.”
With administrators in Washington, Mr. Karp recalled: “It was like, What is this Frankenstein monster doing in my office, making these wild claims that he can do better on things I have a huge budget for? How can it be that a freak-show motley crew of 12-year-old-looking mostly dudes, led by a pretty unique figure, from their perspective, would be able to do something with 1 percent of the money that we can’t do with billions and billions of dollars?”
“There’s nothing that we did at Palantir in building our software company that’s in any M.B.A.-made playbook,” Mr. Karp said. “Not one. That’s why we have been doing so well.”
He said that “the single most valuable education I had for business was sitting at the Sigmund Freud Institute, because I spent all my time with analysts.” When he worked at the institute in Frankfurt while getting his doctorate, Mr. Karp said, he would smoke cigars and think about “the conscious subconscious.”
“You’d be surprised how much analysts talk about their patients,” he said. “It’s disconcerting, actually. You just learn so much about how humans actually think.” This knowledge helps him motivate his engineers, he said.
How It’s Going
Mr. Karp said he likes to think of Palantir’s workers as part of an artists’ colony or a family; he doesn’t use the word “staff.” He enjoys interviewing prospective employees personally and prides himself on making hires in under two minutes. (He likes to have a few people around who can talk philosophy and literature with him, in German and French.)
“A lot of my populist-left politics actually bleed into my hiring stuff,” he said. “If you ask the question that the Stanford, Harvard, Yale person has answered a thousand times, all you’re learning is that the Stanford, Harvard, Yale person has learned to play the game.”
Even if he gets a good answer from a “privileged” candidate and a bad answer from “the child of a mechanic,” he might prefer the latter if “I have that feeling like I’m in the presence of talent.”
He views Palantirians like the Goonies, underdogs winning in the end. “Most people at Palantir didn’t get to do a lot of winning in high school,” Mr. Karp said at a company gathering in Palo Alto, to laughter from the audience.
He thinks the United States is “very likely” to end up in a three-front war with China, Russia and Iran. So, he argues, we have to keep going full-tilt on autonomous weapons systems, because our adversaries will — and they don’t have the same moral considerations that we do.
“I think we’re in an age when nuclear deterrent is actually less effective because the West is very unlikely to use anything like a nuclear bomb, whereas our adversaries might,” he said. “Where you have technological parity but moral disparity, the actual disparity is much greater than people think.”
“In fact,” he added, “given that we have parity technologically but we don’t have parity morally, they have a huge advantage.”
Mr. Karp, who said he supports Vice President Kamala Harris in the 2024 election, described his politics as “populist-left.”Credit…Ryan David Brown for The New York Times
Mr. Karp said that we are “very close” to terminator robots and at the threshold of “somewhat autonomous drones and devices like this being the most important instruments of war. You already see this in Ukraine.”
Palantir has learned from some early setbacks.
In 2011, the hacker group Anonymous showed that Palantir employees were involved in a proposed misinformation campaign to discredit WikiLeaks and smear some of its supporters, including the journalist Glenn Greenwald. (Mr. Karp apologized to Mr. Greenwald.) Then, at least one Palantir employee helped Cambridge Analytica collect the Facebook data that the Trump campaign used ahead of the 2016 election.
A pro bono contract with the New Orleans Police Department starting in 2012 was dropped after six years amid criticism that its “predictive policing” eroded privacy and had a disparate impact on people of color.
“We reduced the rates of Black-on-Black death in New Orleans,” Mr. Karp said, “and we have these critics who are like, ‘Palantir is racist.’ I don’t know. The hundreds of people that are alive now don’t think we’re racist.”
Mr. Carville, a New Orleans pooh-bah, asserted that the partnership ended because of “left-wing conspiracy theories.”
Palantir’s rough start in Silicon Valley came about, in part, because many objected to its work with the Department of Defense.
In 2017, Google won a Pentagon contract, Project Maven, to help the military use the company’s A.I. to analyze footage from drones. Employees protested, sending a letter to the C.E.O., Sundar Pichai: “Google should not be in the business of war,” it read. Soon after, Google backed away from the project.
In response, Palantir shaded Google in a tweet that quoted Mr. Karp: “Silicon Valley is telling the average American ‘I will not support your defense needs’ while selling products that are adversarial to America. That is a loser position.” Palantir picked up the contract in 2019.
That same year, Mr. Thiel said that Google had a “treasonous” relationship with China. When Google opened an A.I. lab in 2017 in China, where there’s little distinction between the civilian and the military, he argued, it was de facto helping China while refusing to help America. (That lab closed in 2019, but Google still does business with China, as does Apple.)
“When you have people working at consumer internet companies protesting us because we help the Navy SEALs and the U.S. military and were pro-border — and you’re becoming incredibly, mind-bogglingly rich, in part because America protects your right to export — to me, you’ve lost the sheet of music,” Mr. Karp said. “I don’t think that’s good for America.”
Scott Galloway, a professor at New York University and an authority on tech companies, agrees that many Silicon Valley C.E.O.s have been virtue-signaling and pretending to care about the progressive political views of employees, but really would sell “their mother for a nickel.”
“They’re not there to save the whales,” Mr. Galloway said. “They’re there to make money.”
He added: “Some of these big tech companies seem to be engaged in raising a generation of business leaders that just don’t like America, who are very focused on everything that’s wrong with America.
“Alex Karp is like, ‘No, we’ll cash the Pentagon’s check and we’ll collect data on our enemies.’ He’s gone the entirely opposite way, and I think it was a smart move.”
Palantir’s “spooky connotations,” as one executive put it, dissipated quite a bit when the company went public in 2020 and took on more commercial business; its clients include Airbus, J.P. Morgan, IBM and Amazon.
Mr. Thiel said that while Palantir had a brief stint working on a pilot program for the National Security Agency, the company would not want to do any more work there: “The N.S.A., it hoovers up all the data in the world. As far as I can tell, there are incredible civil liberties violations where they’re spying on everybody outside the U.S., basically. Then they’re fortunately too incompetent to do much with the data.”
The company has started turning a profit, and the stock has climbed. After a triumphant earnings report this month, Palantir’s stock price jumped again.
“The share price gives us more street cred,” Mr. Karp said.
In 2020, after 17 years in Silicon Valley, Mr. Karp moved Palantir’s headquarters to Denver. “I was fleeing Silicon Valley because of what I viewed as the regressive side of progressive politics,” he said.
He thinks that the valley has intensified class divisions in America.
“I don’t believe you would have a Trump phenomenon without the excesses of Silicon Valley,” he said. “Very, very wealthy people who support policies where they don’t have to absorb the cost at all. Just also the general feeling that these people are not tethered to our society, and simultaneously are becoming billionaires.“
“Not supporting the U.S. military,” he said, in a tone of wonder. “I don’t even know how you explain to the average American that you’ve become a multibillionaire and you won’t supply your product to the D.O.D. It’s jarringly corrosive. That’s before you get to all the corrosive, divisive things that are on these platforms.”
Akshay Krishnaswamy, Palantir’s chief architect, agreed on their Silicon Valley critics: “You live in the liberal democratic West because of reasons, and those reasons don’t come for free. They act like it doesn’t have to be fought for or defended rigorously.”
Mr. Karp’s workout room.Credit…Ryan David Brown for The New York TimesA few of his favorite things.Credit…Ryan David Brown for The New York Times
Mr. Karp said things had evolved. “I think there’s a different perception of us now a little bit. A lot of that was tied to Trump, ICE work. It built up and we were definitely outsiders. We’re still outsiders, but I feel less resistance for sure. And people have a better idea of what we do, maybe.” He added, “Defense tech is a big part of Silicon Valley now.”
The A.I. revolution, he said, will come with a knotty question: “How do you make sure the society’s fair when the means of production have become means that only 1 percent of the population actually knows how to navigate?”
I asked if he agrees with Elon Musk that A.I. is eventually going to take everyone’s jobs.
“I think what’s actually dangerous,” Mr. Karp replied, “is that people who understand how to use this are going to capture a lot of the value of the market and everyone else is going to feel left behind.”
Mr. Karp’s iconoclastic style and ironclad beliefs have inspired memes and attracted a flock of online acolytes — some call him Papa Karp or Daddy Karp. He has no social media presence, but his online fans treat him like a mystic, obsessing over the tight white T-shirts he wears for earnings reports, his Norwegian ski outfits, his corkscrew hair, his Italian jeans and sunglasses and his extreme candor. (In a recent earnings report, Mr. Karp dismissed his rivals as “self-pleasuring” and engaging in “self-flagellation.”)
He is not, as one colleague puts it, “a wife, kids and dog person.”
“I tend to have long-term relationships,” he told me. “And I tend to end up with very high IQ women,” including some who tell him he’s talking nonsense.
He prefers what he calls a German attitude toward relationships, where “you have a much greater degree of privacy,” he said, with separate bedrooms and “your own world, your own thoughts, and you get to be alone a lot.” There is much less requirement to “micro-lie” about where you were or whom you were with.
I asked Mr. Karp about his 2013 quote to Forbes that “the only time I’m not thinking about Palantir is when I’m swimming, practicing qigong or during sexual activity.”
He frowned, noting: “It should be tai chi. I don’t know why people always conflate tai chi with qigong. Yes, that was in my early days, when we were a pre-public company and I was allowed to admit I had sexual activity.”
So it’s true that the notion of settling down and raising a family gives him hives?
“There’s some truth in that,” he said. “This is how I like to live. See, I’m sitting here doing my freedom thing. I train. I do distance shooting.” He reads. “Who else has a Len Deighton spy novel next to a book on Confucian philosophy?”
Many of the doyennes of Washington society would love to snag the eligible Mr. Karp for a dinner party. He told me he has “a great social life.” But when I asked him what that is, he replied, “First of all, I’m a cross-country skier, so then I do all this training.”
He continued, “To have an elite VO2 max, an elite level of strength, it’s just consistency and the Norwegian-style training method.”
Some who know Mr. Karp said that the happiest they had ever seen him was last year when Mike Allen reported for Axios that the C.E.O.’s body fat was an impressive 7 percent.
Mr. Karp may be able to do more than 20 miles of cross-country skiing without being out of breath, but there are some sports at which, he admitted, he’s “a complete zero. For example, ball sports. I really suck at them.”
Unlike Mr. Musk and other tech lords, Mr. Karp is not into micro-dosing ketamine or any other drug. “My drug is athletics,” he said. “I love drinking, but now I’ve moved to drinking very little because what I’ve noticed is if you’re traveling all the time, the alcohol, it really affects your brain.” He’s on the road about 240 days a year.
Mr. Musk and Mr. Karp at the forum on A.I. in Washington last year.Credit…Haiyun Jiang for The New York Times
Mr. Karp said of his dyslexia: “I think this is not getting less, it’s likely getting more. In 40 years, I’ll be unable to read.”
In New Hampshire, we had a lunch of lobster pasta — he kept his panic button on the table — and then went shooting on his property. He expertly hit targets with a 9-millimeter pistol from 264 yards. When an aide suggested that a photographer not shoot Mr. Karp in the act of shooting, he overruled the idea.
“Actually, honestly, guns would be much better regulated if you had someone who knows guns,” he said. “I’m not a hunter. I’m an artist with a gun.”
(Later, Mr. Karp pointed out that he had been shooting at targets that were about twice as far from him as Mr. Trump was from his would-be assassin. “There’s something really wrong with security for our future president, or maybe not future president,” he said. “All these people need a different level of security.”)
Mr. Karp believes the Democrats need to project more strength: “Are we tough enough to scare our adversaries so we don’t go to war? Do the Chinese, Russians and Persians think we’re strong? The president needs to tell them if you cross these lines, this is what we’re going to do, and you have to then enforce it.”
He thinks that in America and in Europe, the inability or unwillingness to secure borders fuels authoritarianism.
“I see it as pretty simple: You have an open border, you get the far right,” he said. “And once you get them, you can’t get rid of them. We saw it in Brexit, we see it with Le Pen in France, you see it across Europe. Now you see it in Germany.”
“They should be much stricter,” he continued. That, he said, “is the only reason we have the rise of the right, the only reason. When people tell you we need an open border, then they should also tell you why they’re electing right-wing politicians, because they are.”
“The biggest mistake — and it’s not one politician, it’s a generation — was believing there was something bigoted about having a border, and there are just a lot of people who believe that,” he said.
Weeks later, we were back in the Washington office, which is dubbed Rivendell, after a valley in Tolkien’s Middle-earth, and is filled with tech goodies like a Ping-Pong table, a pool table and a towering replica of Chewbacca.
We picked up our conversation about politics, talking about the swap of President Biden and Vice President Harris, the rise of JD Vance, the assassination attempt and the changed political landscape.
Mr. Karp concurred with his friend Mr. Carville on the problem of drawing men to the Democratic Party, saying, “If this is going to be a party complaining about guys and to guys all the time, it’s not going to succeed.”
At the shooting range on his property in New Hampshire. “I’m an artist with a gun,” Mr. Karp said.Credit…Ryan David Brown for The New York Times
He continued: “The biggest problem with hard political correctness is it makes it impossible to deal with unfortunate facts. The unfortunate fact here is that this election is really going to turn on ‘What percentage of males can the Democrats still get?’”
Describing himself as “progressive but not woke,” he said, “We are so unwilling to talk to the actual constituents that are voting for the Democratic Party who would probably strongly prefer policies that are more moderate.”
Given Mr. Karp’s blended racial identity, I wondered how he felt about Mr. Trump’s attack on the vice president’s heritage.
“I think people are most fascinated by the fact of this whole Black-Jewish thing,” he said. “I tend to be less fascinated by that.”
He added: “I think that people always expect me somehow to see the world in one way or another, and I don’t really understand what that means. I see the world the way I see it. I think, at the end of the day, if people want to choose what their identity is, then they choose it, and that’s their definition.”
I note that he recently made an elite list of Black billionaires.
He shrugged. “Some Black people think I’m Black, some don’t,” he said. “I view me as me. And I’m very honored to be honored by all groups that will have me.”
He added: “I do not believe racism is the most important issue in this country. I think class is determinate, and I’m mystified by how often we talk about race. I’m not saying it doesn’t exist. I’m not saying people don’t have biases. Of course, we all do, but the primary thing that’s bad for you in this culture is to be born poor of any color.”
He said he would support class-based affirmative action and declared himself “pro draft.”
“I think part of the reason we have a massive cleavage in our culture is, at the end of the day, by and large, only people who are middle- and working-class do all the fighting,” he said.
Since I had last seen him, Mr. Karp had gotten caught between two of the battling billionaires of Silicon Valley, lords of the cloud vituperously fighting in public over the possible restoration of Donald Trump.
According to an account in Puck, Mr. Karp was onstage with the LinkedIn co-founder Reid Hoffman at a conference last month in Sun Valley, Idaho, sponsored by the investment bank Allen & Company, when Mr. Hoffman called Mr. Thiel’s support for Mr. Trump “a moral issue.” Speaking up from his seat in the audience, Mr. Thiel sarcastically thanked Mr. Hoffman for funding lawsuits against Mr. Trump, which allowed the candidate to claim that he is “a martyr.”
Mr. Hoffman snapped back, “Yeah, I wish I had made him an actual martyr” — an unfortunate comment given what would later happen in Butler, Pa.
I asked Mr. Karp whether the encounter was as uncomfortable as it seemed.
“Well, I’m used to being uncomfortable,” he said. “I’m going to stick with my friends. I just feel the same way I always feel when Peter is under attack, which is: ‘This is my friend. I feel that my friend is being attacked, and I will defend him.’”
The fancy digital clock behind Mr. Karp’s desk, which tells time in German, had gone from “Es ist zehn nach drei” to “Es ist halb vier.”
It was time to go.
Mr. Karp said that while working at the Sigmund Freud Institute in Frankfurt, he learned things that were helpful to him later as a business leader.Credit…Ryan David Brown for The New York Times
Confirm or Deny
Maureen Dowd: You run the Twitter account Alex Karp’s Hair.
Alex Karp: I wish.
Your favorite movie is the classic kung fu flick “The 36th Chamber of Shaolin.”
One of my favorite movies.
You have 10 houses around the world, from Alaska to Vermont, from Norway to New Hampshire.
You have to reframe that as I have 10 cross-country ski huts.
You love the idea of Peter Thiel backing Olympic-style games where the athletes will dope out in the open.
Deny. I want the best cross-country skiers to win without doping.
You love to watch spy shows and German movies, and one of your favorite filmmakers is Rainer Werner Fassbinder.
Confirm.
You have 20 identical pairs of swim goggles in your office.
No longer. I used to. I gave up swimming. There’s an emptiness to it.
You commissioned a French comic book, “Palantir: L’Indépendance,” with yourself as the protagonist.
Oui!
You starred in a movie by Hanna Laura Klar in 1998, “I Have Two Faces,” where you looked like a young Woody Allen.
I look better than Woody Allen.
Your dissertation is about how people transmit aggression subconsciously in language, presaging the rise of the right in America and Europe.
Often, the more charismatic ideologies were, the more irrational they were.
The dissertation touched on expressing taboo wishes. Do you want to share some of those?
I would love to express taboo wishes with you, but not to your audience.
SocialAI is an online universe where everyone you interact with is a bot—for better or worse.
The first time I used SocialAI, I was sure the app was performance art. That was the only logical explanation for why I would willingly sign up to have AI bots named Blaze Fury and Trollington Nefarious, well, troll me.
Even the app’s creator, Michael Sayman, admits that the premise of SocialAI may confuse people. His announcement this week of the app read a little like a generative AI joke: “A private social network where you receive millions of AI-generated comments offering feedback, advice, and reflections.”
But, no, SocialAI is real, if “real” applies to an online universe in which every single person you interact with is a bot.
There’s only one real human in the SocialAI equation. That person is you. The new iOS app is designed to let you post text like you would on Twitter or Threads. An ellipsis appears almost as soon as you do so, indicating that another person is loading up with ammunition, getting ready to fire back. Then, instantaneously, several comments appear, cascading below your post, each and every one of them written by an AI character. In the new new version of the app, just rolled out today, these AIs also talk to each other.
When you first sign up, you’re prompted to choose these AI character archetypes: Do you want to hear from Fans? Trolls? Skeptics? Odd-balls? Doomers? Visionaries? Nerds? Drama Queens? Liberals? Conservatives? Welcome to SocialAI, where Trollita Kafka, Vera D. Nothing, Sunshine Sparkle, Progressive Parker, Derek Dissent, and Professor Debaterson are here to prop you up or tell you why you’re wrong.
Screenshot of the instructions for setting up the Social AI app.
Is SocialAI appalling, an echo chamber taken to the extreme? Only if you ignore the truth of modern social media: Our feeds are already filled with bots, tuned by algorithms, and monetized with AI-driven ad systems. As real humans we do the feeding: freely supplying social apps fresh content, baiting trolls, buying stuff. In exchange, we’re amused, and occasionally feel a connection with friends and fans.As notorious crank Neil Postman wrote in 1985, “Anyone who is even slightly familiar with the history of communications knows that every new technology for thinking involves a trade-off.” The trade-off for social media in the age of AI is a slice of our humanity. SocialAI just strips the experience down to pure artifice.
“With a lot of social media, you don’t know who the bot is and who the real person is. It’s hard to tell the difference,” Sayman says. “I just felt like creating a space where you’re able to know that they’re 100 percent AIs. It’s more freeing.”
You might say Sayman has a knack for apps. As a teenage coder in Miami, Florida, during the financial crisis, Sayman gained fame for building a suite of apps to support his family, who had been considering moving back to Peru. Sayman later ended up working in product jobs at Facebook, Google, and Roblox. SocialAI was launched from Sayman’s own venture-backed app studio, Friendly Apps.
In many ways his app is emblematic of design thinking rather than pure AI innovation. SocialAI isn’t really a social app, but ChatGPT in the container of a social broadcast app. It’s an attempt to redefine how we interact with generative AI. Instead of limiting your ChatGPT conversation to a one-to-one chat window, Sayman posits, why not get your answers from many bots, all at the same time?
Over Zoom earlier this week, he explained to me how he thinks of generative AI like a smoothie if cups hadn’t yet been invented. You can still enjoy it from a bowl or plate, but those aren’t the right vessel. SocialAI, Sayman says, could be the cup.
Almost immediately Sayman laughed. “This is a terrible analogy,” he said.
Sayman is charming and clearly thinks a lot about how apps fit into our world. He’s a team of one right now, relying mostly on OpenAI’s technology to power SocialAI, blended with some other custom AI models. (Sayman rate-limits the app so that he doesn’t go broke in “three minutes” from the fees he’s paying to OpenAI. He also hasn’t quite yet figured out how he’ll make money off of SocialAI.) He knows he’s not the first to launch an AI-character app; Meta has burdened its apps with AI characters, and the Character AI app, which was just quasi-acquired by Google, lets you interact with a huge number of AI personas.But Sayman is hand-wavy about this competition. “I don’t see my app as, you’re going to be interacting with characters who you think might be real,” he says. “This is really for seeking answers to conflict resolution, or figuring out if what you’re trying to say is hurtful and get feedback before you post it somewhere else.”
“Someone joked to me that they thought Elon Musk should use this, so he could test all of his posts before he posts them on X,” Sayman said.
I’d actually tried that, tossing some of the most trafficked tweets from Elon Musk and the Twitter icon Dril into my SocialAI feed. I shared a news story from WIRED; the link was unclickable, because SocialAI doesn’t support link-sharing. (There’s no one to share it with, anyway.) I repurposed the viral “Bean Dad” tweet and purported to be a Bean Mom on SocialAI, urging my 9-year-old daughter to open a can of beans herself as a life lesson. I posted political content. I asked my synthetic SocialAI followers who else I should follow.
The bots obliged and flooded my feed with comments, like Reply Guys on steroids. But their responses lacked nutrients or human messiness. Mostly, I told Sayman, it all felt too uncanny, that I had a hard time crossing that chasm and placing value or meaning on what the bots had to say.
Sayman encouraged me to craft more posts along the lines of Reddit’s “Am I the Asshole” posts: Am I wrong in this situation? Should I apologize to a friend? Should I stay mad at my family forever? This, Sayman says, is the real purpose of SocialAI. I tried it. For a second the SocialAI bot comments lit up my lizard brain, my id and superego, the “I’m so right” instinct. Then Trollita Kafka told me, essentially, that I was in fact the asshole.One aspect of SocialAI that clearly does not represent the dawn of a new era: Sayman has put out a minimum viable product without communicating important guidelines around privacy, content policies, or how SocialAI or OpenAI might use the data people provide along the way. (Move fast, break things, etc.) He says he’s not using anyone’s posts to train his own AI models, but notes that users are still subject to OpenAI’s data-training terms, since he uses OpenAI’s API. You also can’t mute or block a bot that has gone off the rails.
At least, though, your feed is always private by default. You don’t have any “real” followers. My editor at WIRED, for example, could join SocialAI himself but will never be able to follow me or see that I copied and pasted an Elon Musk tweet about wanting to buy Coca-Cola and put the cocaine back in it, just as he could not follow my ChatGPT account and see what I’m enquiring about there.
As a human on SocialAI, you will never interact with another human. That’s the whole point. It’s your own little world with your own army of AI characters ready to bolster you or tear you down. You may not like it, but it might be where you’re headed anyway. You might already be there.
The ChatGPT maker reveals details of what’s officially known as OpenAI o1, which shows that AI needs more
OpenAI made the last big breakthrough in artificial intelligence by increasing the size of its models to dizzying proportions, when it introduced GPT-4 last year. The company today announced a new advance that signals a shift in approach—a model that can “reason” logically through many difficult problems and is significantly smarter than existing AI without a major scale-up.
The new model, dubbed OpenAI o1, can solve problems that stump existing AI models, including OpenAI’s most powerful existing model, GPT-4o. Rather than summon up an answer in one step, as a large language model normally does, it reasons through the problem, effectively thinking out loud as a person might, before arriving at the right result.
“This is what we consider the new paradigm in these models,” Mira Murati, OpenAI’s chief technology officer, tells WIRED. “It is much better at tackling very complex reasoning tasks.”
The new model was code-named Strawberry within OpenAI, and it is not a successor to GPT-4o but rather a complement to it, the company says.
Murati says that OpenAI is currently building its next master model, GPT-5, which will be considerably larger than its predecessor. But while the company still believes that scale will help wring new abilities out of AI, GPT-5 is likely to also include the reasoning technology introduced today. “There are two paradigms,” Murati says. “The scaling paradigm and this new paradigm. We expect that we will bring them together.”
LLMs typically conjure their answers from huge neural networks fed vast quantities of training data. They can exhibit remarkable linguistic and logical abilities, but traditionally struggle with surprisingly simple problems such as rudimentary math questions that involve reasoning.
Murati says OpenAI o1 uses reinforcement learning, which involves giving a model positive feedback when it gets answers right and negative feedback when it does not, in order to improve its reasoning process. “The model sharpens its thinking and fine tunes the strategies that it uses to get to the answer,” she says. Reinforcement learning has enabled computers to play games with superhuman skill and do useful tasks like designing computer chips. The technique is also a key ingredient for turning an LLM into a useful and well-behaved chatbot.
Mark Chen, vice president of research at OpenAI, demonstrated the new model to WIRED, using it to solve several problems that its prior model, GPT-4o, cannot. These included an advanced chemistry question and the following mind-bending mathematical puzzle: “A princess is as old as the prince will be when the princess is twice as old as the prince was when the princess’s age was half the sum of their present age. What is the age of the prince and princess?” (The correct answer is that the prince is 30, and the princess is 40).
“The [new] model is learning to think for itself, rather than kind of trying to imitate the way humans would think,” as a conventional LLM does, Chen says.
OpenAI says its new model performs markedly better on a number of problem sets, including ones focused on coding, math, physics, biology, and chemistry. On the American Invitational Mathematics Examination (AIME), a test for math students, GPT-4o solved on average 12 percent of the problems while o1 got 83 percent right, according to the company.
The new model is slower than GPT-4o, and OpenAI says it does not always perform better—in part because, unlike GPT-4o, it cannot search the web and it is not multimodal, meaning it cannot parse images or audio.
AlphaProof was able to learn how to reason over math problems by looking at correct answers. A key challenge with broadening this kind of learning is that there are not correct answers for everything a model might encounter. Chen says OpenAI has succeeded in building a reasoning system that is much more general. “I do think we have made some breakthroughs there; I think it is part of our edge,” Chen says. “It’s actually fairly good at reasoning across all domains.”
Noah Goodman, a professor at Stanford who has published work on improving the reasoning abilities of LLMs, says the key to more generalized training may involve using a “carefully prompted language model and handcrafted data” for training. He adds that being able to consistently trade the speed of results for greater accuracy would be a “nice advance.”
Yoon Kim, an assistant professor at MIT, says how LLMs solve problems currently remains somewhat mysterious, and even if they perform step-by-step reasoning there may be key differences from human intelligence. This could be crucial as the technology becomes more widely used. “These are systems that would be potentially making decisions that affect many, many people,” he says. “The larger question is, do we need to be confident about how a computational model is arriving at the decisions?”
The technique introduced by OpenAI today also may help ensure that AI models behave well. Murati says the new model has shown itself to be better at avoiding producing unpleasant or potentially harmful output by reasoning about the outcome of its actions. “If you think about teaching children, they learn much better to align to certain norms, behaviors, and values once they can reason about why they’re doing a certain thing,” she says.
Oren Etzioni, a professor emeritus at the University of Washington and a prominent AI expert, says it’s “essential to enable LLMs to engage in multi-step problem solving, use tools, and solve complex problems.” He adds, “Pure scale up will not deliver this.” Etzioni says, however, that there are further challenges ahead. “Even if reasoning were solved, we would still have the challenge of hallucination and factuality.”
OpenAI’s Chen says that the new reasoning approach developed by the company shows that advancing AI need not cost ungodly amounts of compute power. “One of the exciting things about the paradigm is we believe that it’ll allow us to ship intelligence cheaper,” he says, “and I think that really is the core mission of our company.”
Temu, the Chinese e-commerce platform, offers products at remarkably low prices, which raises concerns about its business practices. One significant issue is the undervaluation of parcels entering the EU. Estimates suggest that around 65% of parcels are deliberately undervalued in customs declarations to avoid tariffs, which undermines local businesses and creates an uneven playing field [1]. Additionally, Temu employs a direct-to-consumer model, sourcing products directly from manufacturers in China, allowing them to benefit from bulk discounts and reduced shipping costs [2].
Benefits for the Chinese State
The low pricing strategy of Temu serves multiple purposes for the Chinese state. Firstly, it helps expand China’s influence in global e-commerce by increasing the market share of Chinese companies abroad. This can lead to greater economic ties and dependency on Chinese goods. Secondly, by facilitating the export of low-cost products, Temu contributes to the Chinese economy by boosting manufacturing and logistics sectors. Lastly, the data collected from users can be leveraged for insights into consumer behavior, which may benefit Chinese businesses and potentially the state itself in terms of economic planning and strategy [1].
Overall, while Temu’s low prices attract consumers, they also raise significant regulatory and ethical concerns in Europe, prompting scrutiny from authorities regarding compliance with local laws and standards.
Deeper Analysis of Future Benefits for the Chinese State
Temu’s aggressive pricing strategy in Europe not only serves immediate commercial interests but also aligns with broader strategic goals of the Chinese state. Here are several potential future benefits for China:
Economic Expansion and Market Penetration: By establishing a strong foothold in European markets through low prices, Temu can facilitate the expansion of Chinese goods into new territories. This not only increases sales volume but also enhances brand recognition and loyalty among European consumers. As more consumers become accustomed to purchasing Chinese products, it could lead to a long-term shift in buying habits, favoring Chinese brands over local alternatives.
Strengthening Supply Chains: Temu’s model emphasizes direct sourcing from manufacturers, which can help streamline supply chains. This efficiency can be replicated across various sectors, allowing China to become a dominant player in global supply chains. By controlling more aspects of production and distribution, China can mitigate risks associated with international trade tensions and disruptions, ensuring a more resilient economic structure.
Data Collection and Consumer Insights: The platform’s operations will generate vast amounts of consumer data, which can be analyzed to gain insights into European consumer behavior. This data can inform not only marketing strategies but also product development, allowing Chinese manufacturers to tailor their offerings to meet the specific preferences of European consumers. Such insights can enhance competitiveness and drive innovation within Chinese industries.
Geopolitical Influence: By increasing its economic presence in Europe, China can leverage its commercial relationships to enhance its geopolitical influence. Economic ties often translate into political goodwill, which can be beneficial in negotiations on various fronts, including trade agreements and international policies. This strategy aligns with China’s broader goal of expanding its influence globally, as outlined in its recent political resolutions emphasizing the importance of state power and common prosperity.
Promotion of Technological Advancements: As Temu grows, it may invest in technology to improve logistics, customer service, and user experience. This could lead to advancements in e-commerce technologies that can be exported back to China, enhancing domestic capabilities. Moreover, the emphasis on technology aligns with China’s ambitions to become a leader in areas such as artificial intelligence and data analytics, as highlighted in its national strategies.
Cultural Exchange and Soft Power: By making Chinese products more accessible and appealing to European consumers, Temu can facilitate a form of cultural exchange. As consumers engage with Chinese brands, they may also become more receptive to Chinese culture and values, enhancing China’s soft power. This cultural integration can help counter negative perceptions and foster a more favorable view of China in the long term.
In conclusion, Temu’s low pricing strategy is not merely a tactic for market entry; it is a multifaceted approach that can yield significant long-term benefits for the Chinese state. By enhancing economic ties, gathering valuable consumer data, and promoting technological advancements, China positions itself to strengthen its global influence and economic resilience in an increasingly competitive landscape.