Source Techcrunch.com
European Union lawmakers proposed a comprehensive update to the bloc’s data protection and privacy rules in 2012.
Their aim: To take account of seismic shifts in the handling of information wrought by the rise of the digital economy in the years since the prior regime was penned — all the way back in 1995 when Yahoo was the cutting edge of online cool and cookies were still just tasty biscuits.
Here’s the EU’s executive body, the Commission, summing up the goal:
The objective of this new set of rules is to give citizens back control over of their personal data, and to simplify the regulatory environment for business. The data protection reform is a key enabler of the Digital Single Market which the Commission has prioritised. The reform will allow European citizens and businesses to fully benefit from the digital economy.
For an even shorter the EC’s theory is that consumer trust is essential to fostering growth in the digital economy. And it thinks trust can be won by giving users of digital services more information and greater control over how their data is used. Which is — frankly speaking — a pretty refreshing idea when you consider the clandestine data brokering that pervades the tech industry. Mass surveillance isn’t just something governments do.
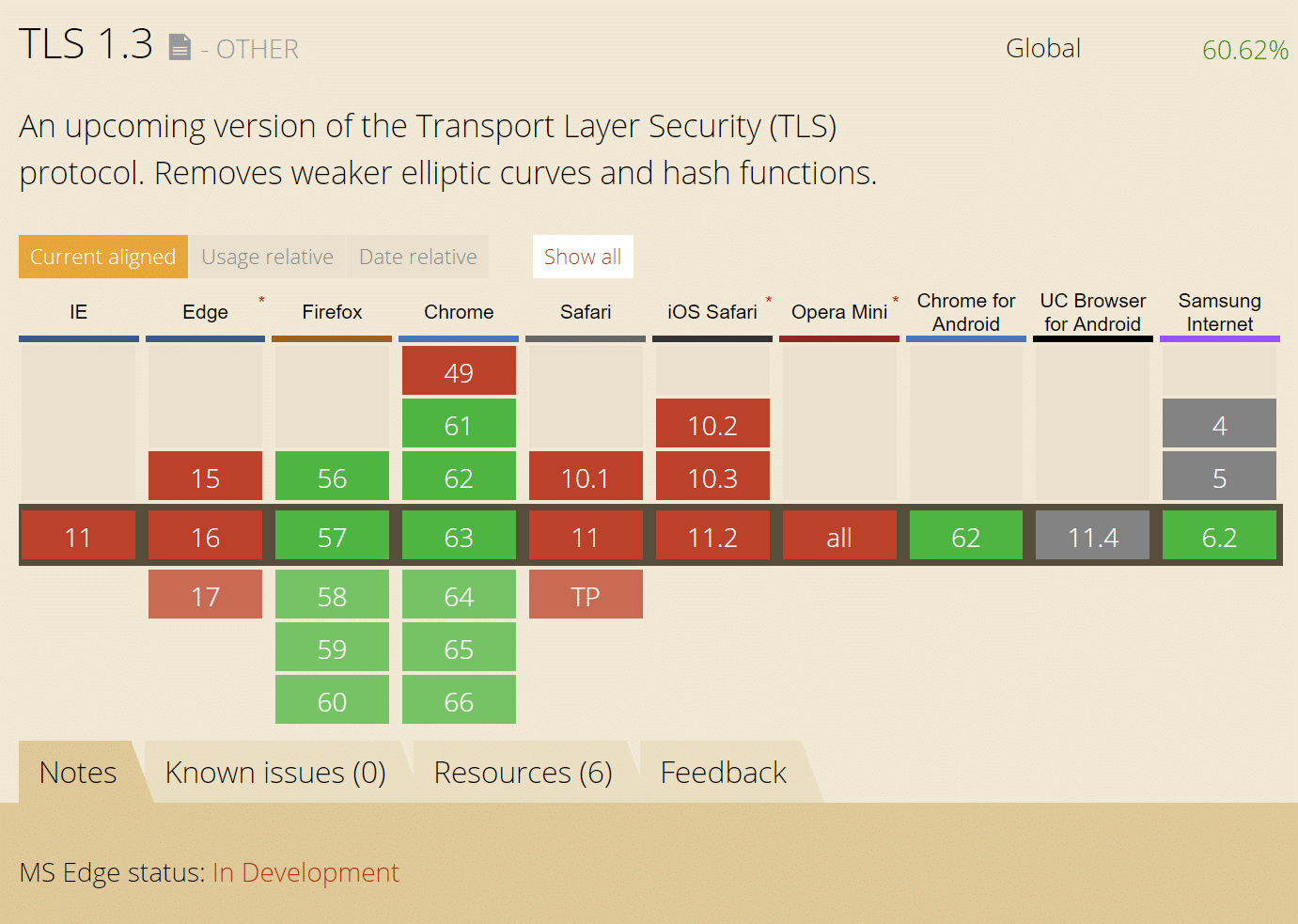
The General Data Protection Regulation (aka GDPR) was agreed after more than three years of negotiations between the EU’s various institutions.
It’s set to apply across the 28-Member State bloc as of May 25, 2018. That means EU countries are busy transposing it into national law via their own legislative updates (such as the UK’s new Data Protection Bill — yes, despite the fact the country is currently in the process of (br)exiting the EU, the government has nonetheless committed to implementing the regulation because it needs to keep EU-UK data flowing freely in the post-brexit future. Which gives an early indication of the pulling power of GDPR.
Meanwhile businesses operating in the EU are being bombarded with ads from a freshly energized cottage industry of ‘privacy consultants’ offering to help them get ready for the new regs — in exchange for a service fee. It’s definitely a good time to be a law firm specializing in data protection.
GDPR is a significant piece of legislation whose full impact will clearly take some time to shake out. In the meanwhile, here’s our guide to the major changes incoming and some potential impacts.
Data protection + teeth
A major point of note right off the bat is that GDPR does not merely apply to EU businesses; any entities processing the personal data of EU citizens need to comply. Facebook, for example — a US company that handles massive amounts of Europeans’ personal data — is going to have to rework multiple business processes to comply with the new rules. Indeed, it’s been working on this for a long time already.
Last year the company told us it had assembled “the largest cross functional team” in the history of its family of companies to support GDPR compliance — specifying this included “senior executives from all product teams, designers and user experience/testing executives, policy executives, legal executives and executives from each of the Facebook family of companies”.
“Dozens of people at Facebook Ireland are working full time on this effort,” it said, noting too that the data protection team at its European HQ (in Dublin, Ireland) would be growing by 250% in 2017. It also said it was in the process of hiring a “top quality data protection officer” — a position the company appears to still be taking applications for.
The new EU rules require organizations to appoint a data protection officer if they process sensitive data on a large scale (which Facebook very clearly does). Or are collecting info on many consumers — such as by performing online behavioral tracking. But, really, which online businesses aren’t doing that these days?
The extra-territorial scope of GDPR casts the European Union as a global pioneer in data protection — and some legal experts suggest the regulation will force privacy standards to rise outside the EU too.
Sure, some US companies might prefer to swallow the hassle and expense of fragmenting their data handling processes, and treating personal data obtained from different geographies differently, i.e. rather than streamlining everything under a GDPR compliant process. But doing so means managing multiple data regimes. And at very least runs the risk of bad PR if you’re outed as deliberately offering a lower privacy standard to your home users vs customers abroad.
Ultimately, it may be easier (and less risky) for businesses to treat GDPR as the new ‘gold standard’ for how they handle all personal data, regardless of where it comes from.
And while not every company harvests Facebook levels of personal data, almost every company harvests some personal data. So for those with customers in the EU GDPR cannot be ignored. At very least businesses will need to carry out a data audit to understand their risks and liabilities.
Privacy experts suggest that the really big change here is around enforcement. Because while the EU has had long established data protection standards and rules — and treats privacy as a fundamental right — its regulators have lacked the teeth to command compliance.
But now, under GDPR, financial penalties for data protection violations step up massively.
The maximum fine that organizations can be hit with for the most serious infringements of the regulation is 4% of their global annual turnover (or €20M, whichever is greater). Though data protection agencies will of course be able to impose smaller fines too. And, indeed, there’s a tiered system of fines — with a lower level of penalties of up to 2% of global turnover (or €10M).
This really is a massive change. Because while data protection agencies (DPAs) in different EU Member States can impose financial penalties for breaches of existing data laws these fines are relatively small — especially set against the revenues of the private sector entities that are getting sanctioned.
In the UK, for example, the Information Commissioner’s Office (ICO) can currently impose a maximum fine of just £500,000. Compare that to the annual revenue of tech giant Google (~$90BN) and you can see why a much larger stick is needed to police data processors.
It’s not necessarily the case that individual EU Member States are getting stronger privacy laws as a consequence of GDPR (in some instances countries have arguably had higher standards in their domestic law). But the beefing up of enforcement that’s baked into the new regime means there’s a better opportunity for DPAs to start to bark and bite like proper watchdogs.
GDPR inflating the financial risks around handling personal data should naturally drive up standards — because privacy laws are suddenly a whole lot more costly to ignore.
More types of personal data that are hot to handle
So what is personal data under GDPR? It’s any information relating to an identified or identifiable person (in regulatorspeak people are known as ‘data subjects’).
While ‘processing’ can mean any operation performed on personal data — from storing it to structuring it to feeding it to your AI models. (GDPR also includes some provisions specifically related to decisions generated as a result of automated data processing but more on that below).
A new provision concerns children’s personal data — with the regulation setting a 16-year-old age limit on kids’ ability to consent to their data being processed. However individual Member States can choose (and some have) to derogate from this by writing a lower age limit into their laws.
GDPR sets a hard cap at 13-years-old — making that the defacto standard for children to be able to sign up to digital services. So the impact on teens’ social media habits seems likely to be relatively limited.
The new rules generally expand the definition of personal data — so it can include information such as location data, online identifiers (such as IP addresses) and other metadata. So again, this means businesses really need to conduct an audit to identify all the types of personal data they hold. Ignorance is not compliance.
GDPR also encourages the use of pseudonymization — such as, for example, encrypting personal data and storing the encryption key separately and securely — as a pro-privacy, pro-security technique that can help minimize the risks of processing personal data. Although pseudonymized data is likely to still be considered personal data; certainly where a risk of reidentification remains. So it does not get a general pass from requirements under the regulation.
Data has to be rendered truly anonymous to be outside the scope of the regulation. (And given how often ‘anonymized’ data-sets have been shown to be re-identifiable, relying on any anonymizing process to be robust enough to have zero risk of re-identification seems, well, risky.)
To be clear, given GDPR’s running emphasis on data protection via data security it is implicitly encouraging the use of encryption above and beyond a risk reduction technique — i.e. as a way for data controllers to fulfill its wider requirements to use “appropriate technical and organisational measures” vs the risk of the personal data they are processing.
The incoming data protection rules apply to both data controllers (i.e. entities that determine the purpose and means of processing personal data) and data processors (entities that are responsible for processing data on behalf of a data controller — aka subcontractors).
Indeed, data processors have some direct compliance obligations under GDPR, and can also be held equally responsible for data violations, with individuals able to bring compensation claims directly against them, and DPAs able to hand them fines or other sanctions.
So the intent for the regulation is there be no diminishing in responsibility down the chain of data handling subcontractors. GDPR aims to have every link in the processing chain be a robust one.
For companies that rely on a lot of subcontractors to handle data operations on their behalf there’s clearly a lot of risk assessment work to be done.
As noted above, there is a degree of leeway for EU Member States in how they implement some parts of the regulation (such as with the age of data consent for kids).
Consumer protection groups are calling for the UK government to include an optional GDPR provision on collective data redress to its DP bill, for example — a call the government has so far rebuffed.
But the wider aim is for the regulation to harmonize as much as possible data protection rules across all Member States to reduce the regulatory burden on digital businesses trading around the bloc.
On data redress, European privacy campaigner Max Schrems — most famous for his legal challenge to US government mass surveillance practices that resulted in a 15-year-old data transfer arrangement between the EU and US being struck down in 2015 — is currently running a crowdfunding campaign to set up a not-for-profit privacy enforcement organization to take advantage of the new rules and pursue strategic litigation on commercial privacy issues.
Schrems argues it’s simply not viable for individuals to take big tech giants to court to try to enforce their privacy rights, so thinks there’s a gap in the regulatory landscape for an expert organization to work on EU citizen’s behalf. Not just pursuing strategic litigation in the public interest but also promoting industry best practice.
The proposed data redress body — called noyb; short for: ‘none of your business’ — is being made possible because GDPR allows for collective enforcement of individuals’ data rights. And that provision could be crucial in spinning up a centre of enforcement gravity around the law. Because despite the position and role of DPAs being strengthened by GDPR, these bodies will still inevitably have limited resources vs the scope of the oversight task at hand.
Some may also lack the appetite to take on a fully fanged watchdog role. So campaigning consumer and privacy groups could certainly help pick up any slack.
Privacy by design and privacy by default
Another major change incoming via GDPR is ‘privacy by design’ no longer being just a nice idea; privacy by design and privacy by default become firm legal requirements.
This means there’s a requirement on data controllers to minimize processing of personal data — limiting activity to only what’s necessary for a specific purpose, carrying out privacy impact assessments and maintaining up-to-date records to prove out their compliance.
Consent requirements for processing personal data are also considerably strengthened under GDPR — meaning lengthy, inscrutable, pre-ticked T&Cs are likely to be unworkable. (And we’ve sure seen a whole lot of those hellish things in tech.) The core idea is that consent should be an ongoing, actively managed process; not a one-off rights grab.
As the UK’s ICO tells it, consent under GDPR for processing personal data means offering individuals “genuine choice and control” (for sensitive personal data the law requires a higher standard still — of explicit consent).
There are other legal bases for processing personal data under GDPR — such as contractual necessity; or compliance with a legal obligation under EU or Member State law; or for tasks carried out in the public interest — so it is not necessary to obtain consent in order to process someone’s personal data. But there must always be an appropriate legal basis for each processing.
Transparency is another major obligation under GDPR, which expands the notion that personal data must be lawfully and fairly processed to include a third principle of accountability. Hence the emphasis on data controllers needing to clearly communicate with data subjects — such as by informing them of the specific purpose of the data processing.
The obligation on data handlers to maintain scrupulous records of what information they hold, what they are doing with it, and how they are legally processing it, is also about being able to demonstrate compliance with GDPR’s data processing principles.
But — on the plus side for data controllers — GDPR removes the requirement to submit notifications to local DPAs about data processing activities. Instead, organizations must maintain detailed internal records — which a supervisory authority can always ask to see.
It’s also worth noting that companies processing data across borders in the EU may face scrutiny from DPAs in different Member States if they have users there (and are processing their personal data).
Although the GDPR sets out a so-called ‘one-stop-shop’ principle — that there should be a “lead” DPA to co-ordinate supervision between any “concerned” DPAs — this does not mean that, once it applies, a cross-EU-border operator like Facebook is only going to be answerable to the concerns of the Irish DPA.
Indeed, Facebook’s tactic of only claiming to be under the jurisdiction of a single EU DPA looks to be on borrowed time. And the one-stop-shop provision in the GDPR seems more about creating a co-operation mechanism to allow multiple DPAs to work together in instances where they have joint concerns, rather than offering a way for multinationals to go ‘forum shopping’ — which the regulation does not permit (per WP29 guidance).
Another change: Privacy policies that contain vague phrases like ‘We may use your personal data to develop new services’ or ‘We may use your personal data for research purposes’ will not pass muster under the new regime. So a wholesale rewriting of vague and/or confusingly worded T&Cs is something Europeans can look forward to this year.
Add to that, any changes to privacy policies must be clearly communicated to the user on an ongoing basis. Which means no more stale references in the privacy statement telling users to ‘regularly check for changes or updates’ — that just won’t be workable.
The onus is firmly on the data controller to keep the data subject fully informed of what is being done with their information. (Which almost implies that good data protection practice could end up tasting a bit like spam, from a user PoV.)
The overall intent behind GDPR is to inculcate an industry-wide shift in perspective regarding who ‘owns’ user data — disabusing companies of the notion that other people’s personal information belongs to them just because it happens to be sitting on their servers.
“Organizations should acknowledge they don’t exist to process personal data but they process personal data to do business,” is how analyst Gartner research director Bart Willemsen sums this up. “Where there is a reason to process the data, there is no problem. Where the reason ends, the processing should, too.”
The data protection officer (DPO) role that GDPR brings in as a requirement for many data handlers is intended to help them ensure compliance.
This officer, who must report to the highest level of management, is intended to operate independently within the organization, with warnings to avoid an internal appointment that could generate a conflict of interests.
Which types of organizations face the greatest liability risks under GDPR? “Those who deliberately seem to think privacy protection rights is inferior to business interest,” says Willemsen, adding: “A recent example would be Uber, regulated by the FTC and sanctioned to undergo 20 years of auditing. That may hurt perhaps similar, or even more, than a one-time financial sanction.”
“Eventually, the GDPR is like a speed limit: There not to make money off of those who speed, but to prevent people from speeding excessively as that prevents (privacy) accidents from happening,” he adds.
Another right to be forgotten
Under GDPR, people who have consented to their personal data being processed also have a suite of associated rights — including the right to access data held about them (a copy of the data must be provided to them free of charge, typically within a month of a request); the right to request rectification of incomplete or inaccurate personal data; the right to have their data deleted (another so-called ‘right to be forgotten’ — with some exemptions, such as for exercising freedom of expression and freedom of information); the right to restrict processing; the right to data portability (where relevant, a data subject’s personal data must be provided free of charge and in a structured, commonly used and machine readable form).
All these rights make it essential for organizations that process personal data to have systems in place which enable them to identify, access, edit and delete individual user data — and be able to perform these operations quickly, with a general 30 day time-limit for responding to individual rights requests.
GDPR also gives people who have consented to their data being processed the right to withdraw consent at any time. Let that one sink in.
Data controllers are also required to inform users about this right — and offer easy ways for them to withdraw consent. So no, you can’t bury a ‘revoke consent’ option in tiny lettering, five sub-menus deep. Nor can WhatsApp offer any more time-limit opt-outs for sharing user data with its parent multinational, Facebook. Users will have the right to change their mind whenever they like.
The EU lawmakers’ hope is that this suite of rights for consenting consumers will encourage respectful use of their data — given that, well, if you annoy consumers they can just tell you to sling yer hook and ask for a copy of their data to plug into your rival service to boot. So we’re back to that fostering trust idea.
Add in the ability for third party organizations to use GDPR’s provision for collective enforcement of individual data rights and there’s potential for bad actors and bad practice to become the target for some creative PR stunts that harness the power of collective action — like, say, a sudden flood of requests for a company to delete user data.
Data rights and privacy issues are certainly going to be in the news a whole lot more.
Getting serious about data breaches
But wait, there’s more! Another major change under GDPR relates to security incidents — aka data breaches (something else we’ve seen an awful, awful lot of in recent years) — with the regulation doing what the US still hasn’t been able to: Bringing in a universal standard for data breach disclosures.
GDPR requires that data controllers report any security incidents where personal data has been lost, stolen or otherwise accessed by unauthorized third parties to their DPA within 72 hours of them becoming aware of it. Yes, 72 hours. Not the best part of a year, like er Uber.
If a data breach is likely to result in a “high risk of adversely affecting individuals’ rights and freedoms” the regulation also implies you should ‘fess up even sooner than that — without “undue delay”.
Only in instances where a data controller assesses that a breach is unlikely to result in a risk to the rights and freedoms of “natural persons” are they exempt from the breach disclosure requirement (though they still need to document the incident internally, and record their reason for not informing a DPA in a document that DPAs can always ask to see).
“You should ensure you have robust breach detection, investigation and internal reporting procedures in place,” is the ICO’s guidance on this. “This will facilitate decision-making about whether or not you need to notify the relevant supervisory authority and the affected individuals.”
The new rules generally put strong emphasis on data security and on the need for data controllers to ensure that personal data is only processed in a manner that ensures it is safeguarded.
Here again, GDPR’s requirements are backed up by the risk of supersized fines. So suddenly sloppy security could cost your business big — not only in reputation terms, as now, but on the bottom line too. So it really must be a C-suite concern going forward.
Nor is subcontracting a way to shirk your data security obligations. Quite the opposite. Having a written contract in place between a data controller and a data processor was a requirement before GDPR but contract requirements are wider now and there are some specific terms that must be included in the contract, as a minimum.
Breach reporting requirements must also be set out in the contract between processor and controller. If a data controller is using a data processor and it’s the processor that suffers a breach, they’re required to inform the controller as soon as they become aware. The controller then has the same disclosure obligations as per usual.
Essentially, data controllers remain liable for their own compliance with GDPR. And the ICO warns they must only appoint processors who can provide “sufficient guarantees” that the regulatory requirements will be met and the rights of data subjects protected.
tl;dr, be careful who and how you subcontract.
Right to human review for some AI decisions
Article 22 of GDPR places certain restrictions on entirely automated decisions based on profiling individuals — but only in instances where these human-less acts have a legal or similarly significant effect on the people involved.
There are also some exemptions to the restrictions — where automated processing is necessary for entering into (or performance of) a contract between an organization and the individual; or where it’s authorized by law (e.g. for the purposes of detecting fraud or tax evasion); or where an individual has explicitly consented to the processing.
In its guidance, the ICO specifies that the restriction only applies where the decision has a “serious negative impact on an individual”.
Suggested examples of the types of AI-only decisions that will face restrictions are automatic refusal of an online credit application or an e-recruiting practices without human intervention.
Having a provision on automated decisions is not a new right, having been brought over from the 1995 data protection directive. But it has attracted fresh attention — given the rampant rise of machine learning technology — as a potential route for GDPR to place a check on the power of AI blackboxes to determine the trajectory of humankind.
The real-world impact will probably be rather more prosaic, though. And experts suggest it does not seem likely that the regulation, as drafted, equates to a right for people to be given detailed explanations of how algorithms work.
Though as AI proliferates and touches more and more decisions, and as its impacts on people and society become ever more evident, pressure may well grow for proper regulatory oversight of algorithmic blackboxes.
In the meanwhile, what GDPR does in instances where restrictions apply to automated decisions is require data controllers to provide some information to individuals about the logic of an automated decision.
They are also obliged to take steps to prevent errors, bias and discrimination. So there’s a whiff of algorithmic accountability. Though it may well take court and regulatory judgements to determine how stiff those steps need to be in practice.
Individuals do also have a right to challenge and request a (human) review of an automated decision in the restricted class.
Here again the intention is to help people understand how their data is being used. And to offer a degree of protection (in the form of a manual review) if a person feels unfairly and harmfully judged by an AI process.
The regulation also places some restrictions on the practice of using data to profile individuals if the data itself is sensitive data — e.g. health data, political belief, religious affiliation etc — requiring explicit consent for doing so. Or else that the processing is necessary for substantial public interest reasons (and lies within EU or Member State law).
While profiling based on other types of personal data does not require obtaining consent from the individuals concerned, it still needs a legal basis and there is still a transparency requirement — which means service providers will need to inform users they are being profiled, and explain what it means for them.
And people also always have the right to object to profiling activity based on their personal data.
Source: https://techcrunch.com/2018/01/20/wtf-is-gdpr/







/cdn.vox-cdn.com/uploads/chorus_asset/file/3975956/android.0.jpg)